Сюжет GeoPandas - есть ли способ ускорить процесс?
Я использую алгоритм градиентного спуска на некоторых геоданных. Цель состоит в том, чтобы назначить различные области различным кластерам, чтобы минимизировать некоторые целевые функции. Я пытаюсь сделать короткий фильм, показывающий, как продвигается алгоритм. Прямо сейчас мой подход заключается в построении карты на каждом шаге, а затем использовать некоторые другие инструменты, чтобы сделать небольшой фильм из всех статических изображений (довольно просто). Но у меня есть около 3000 областей для построения, и для выполнения команды plot требуется не менее 90 секунд, что убивает мой алгоритм.
Есть несколько очевидных ярлыков: сохраняйте изображения на каждой N-й итерации, сохраняйте все шаги в списке и делайте все изображения в конце (возможно, параллельно). Пока все нормально, но в конечном итоге я стремлюсь к некоторой интерактивной функциональности, где пользователь может ввести некоторые параметры и увидеть, как их карта сходится в реальном времени. Похоже, что обновление карты на лету было бы лучше в этом случае.
Есть идеи? Вот основная команда (с использованием последней версии dev геопанд)
fig, ax = plt.subplots(1,1, figsize=(7,5))
geo_data.plot(column='cluster',ax=ax, cmap='gist_rainbow',linewidth=0)
fig.savefig(filename, bbox_inches='tight', dpi=400)
Также пробовал что-то похожее на следующее (сокращенная версия ниже). Я открываю один график, меняю его и сохраняю с каждой итерацией. Кажется, не ускоряет все.
fig, ax = plt.subplots(1,1, figsize=(7,5))
plot = geo_data.plot(ax=ax)
for iter in range(100): #just doing 100 iterations now
clusters = get_clusters(...)
for i_d, district in enumerate(plot.patches):
if cluster[i] == 1
district.set_color("#FF0000")
else:
district.set_color("#d3d3d3")
fig.savefig('test'+str(iter)+'.pdf')
обновление: взглянул на drawnow и другие указатели из прорисовки в реальном времени в цикле while с matplotlib, но шейп-файлы кажутся слишком большими / неуклюжими, чтобы работать в реальном времени.
1 ответ
Я думаю, что два аспекта могут улучшить производительность: 1) использование коллекции matplotlib (текущая реализация геопанды строит графики для каждого многоугольника отдельно) и 2) только обновляет цвет многоугольников и не выводит его снова на каждой итерации (это вы уже делаете, но с использованием коллекции это будет намного проще).
1) Использование коллекции matplotlib для построения полигонов
Это возможная реализация для более эффективной функции построения графиков с геопандами для построения GeoSeries of Polygons:
from matplotlib.collections import PatchCollection
from matplotlib.patches import Polygon
import shapely
def plot_polygon_collection(ax, geoms, values=None, colormap='Set1', facecolor=None, edgecolor=None,
alpha=0.5, linewidth=1.0, **kwargs):
""" Plot a collection of Polygon geometries """
patches = []
for poly in geoms:
a = np.asarray(poly.exterior)
if poly.has_z:
poly = shapely.geometry.Polygon(zip(*poly.exterior.xy))
patches.append(Polygon(a))
patches = PatchCollection(patches, facecolor=facecolor, linewidth=linewidth, edgecolor=edgecolor, alpha=alpha, **kwargs)
if values is not None:
patches.set_array(values)
patches.set_cmap(colormap)
ax.add_collection(patches, autolim=True)
ax.autoscale_view()
return patches
Это примерно в 10 раз быстрее, чем текущий метод построения геопанд.
2) Обновление цветов полигонов
Если у вас есть рисунок, обновление цветов коллекции полигонов можно сделать за один шаг, используя set_array метод, в котором значения в массиве указывают цвет (преобразуется в цвет в зависимости от карты цветов)
Например (учитывая s_poly GeoSeries с полигонами):
fig, ax = plt.subplots(subplot_kw=dict(aspect='equal'))
col = plot_polygon_collection(ax, s_poly.geometry)
# update the color
col.set_array( ... )
Полный пример с некоторыми фиктивными данными:
from shapely.geometry import Polygon
p1 = Polygon([(0, 0), (1, 0), (1, 1)])
p2 = Polygon([(2, 0), (3, 0), (3, 1), (2, 1)])
p3 = Polygon([(1, 1), (2, 1), (2, 2), (1, 2)])
s = geopandas.GeoSeries([p1, p2, p3])
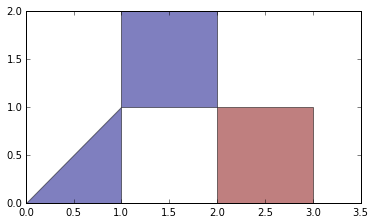
Построение этого:
fig, ax = plt.subplots(subplot_kw=dict(aspect='equal'))
col = plot_polygon_collection(ax, s.geometry)
дает:
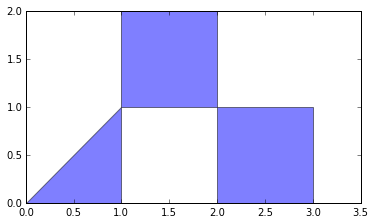
Затем обновите цвет массивом с указанием кластеров:
col.set_array(np.array([0,1,0]))
дает