Потоковый конвейер данных Google не распределяет рабочую нагрузку между несколькими работниками после создания окон
Я пытаюсь настроить потоковый конвейер потока данных в Python. У меня есть некоторый опыт работы с пакетными трубопроводами. Наша базовая архитектура выглядит так:
На первом этапе выполняется некоторая базовая обработка, и для сообщения в окно требуется около 2 секунд. Мы используем скользящие окна с интервалом 3 секунды и 3 секунды (может измениться позже, поэтому у нас перекрывающиеся окна). В качестве последнего шага у нас есть прогноз SOG, который занимает около 15-ти секунд для обработки и который является явным преобразованием нашего узкого места.
Итак, проблема, с которой мы, похоже, сталкиваемся, заключается в том, что рабочая нагрузка отлично распределяется между нашими работниками до начала работы с окнами, но самое важное преобразование не распространяется вообще. Все окна обрабатываются по одному на одного работника, в то время как у нас есть 50 доступных.
Журналы показывают нам, что шаг прогнозирования sog выводится один раз в каждые 15 с лишним секунд, что не должно иметь место, если окна будут обрабатываться на большем количестве рабочих, поэтому это создает огромную задержку с течением времени, которую мы не хотим. С 1 минутой сообщений у нас есть задержка 5 минут для последнего окна. Когда распределение будет работать, это должно быть только около 15 секунд (время прогнозирования SOG). Так что на данный момент мы невежественны..
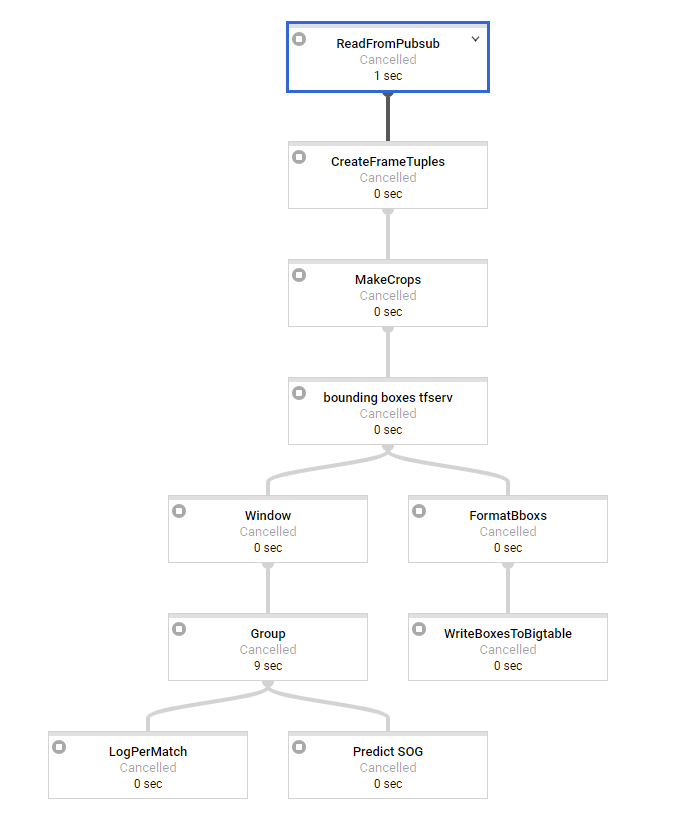
Кто-нибудь видит, если что-то не так с нашим кодом или как предотвратить / обойти это? Кажется, что-то происходит во внутреннем потоке данных облака Google. Это также происходит в потоковых конвейерах Java?
В пакетном режиме все отлично работает. Там можно попытаться сделать перестановку, чтобы убедиться, что не происходит слияния и т.д. Но это невозможно после создания окон в потоковом режиме.
args = parse_arguments(sys.argv if argv is None else argv)
pipeline_options = get_pipeline_options(project=args.project_id,
job_name='XX',
num_workers=args.workers,
max_num_workers=MAX_NUM_WORKERS,
disk_size_gb=DISK_SIZE_GB,
local=args.local,
streaming=args.streaming)
pipeline = beam.Pipeline(options=pipeline_options)
# Build pipeline
# pylint: disable=C0330
if args.streaming:
frames = (pipeline | 'ReadFromPubsub' >> beam.io.ReadFromPubSub(
subscription=SUBSCRIPTION_PATH,
with_attributes=True,
timestamp_attribute='timestamp'
))
frame_tpl = frames | 'CreateFrameTuples' >> beam.Map(
create_frame_tuples_fn)
crops = frame_tpl | 'MakeCrops' >> beam.Map(make_crops_fn, NR_CROPS)
bboxs = crops | 'bounding boxes tfserv' >> beam.Map(
pred_bbox_tfserv_fn, SERVER_URL)
sliding_windows = bboxs | 'Window' >> beam.WindowInto(
beam.window.SlidingWindows(
FEATURE_WINDOWS['goal']['window_size'],
FEATURE_WINDOWS['goal']['window_interval']),
trigger=AfterCount(30),
accumulation_mode=AccumulationMode.DISCARDING)
# GROUPBYKEY (per match)
group_per_match = sliding_windows | 'Group' >> beam.GroupByKey()
_ = group_per_match | 'LogPerMatch' >> beam.Map(lambda x: logging.info(
"window per match per timewindow: # %s, %s", str(len(x[1])), x[1][0][
'timestamp']))
sog = sliding_windows | 'Predict SOG' >> beam.Map(predict_sog_fn,
SERVER_URL_INCEPTION,
SERVER_URL_SOG )
pipeline.run().wait_until_finish()
2 ответа
В луче единица параллелизма является ключом - все окна для данного ключа будут созданы на одной машине. Однако, если у вас есть более 50 ключей, они должны быть распределены среди всех работников.
Вы упомянули, что не можете добавить Reshuffle в потоковом режиме. Это должно быть возможно; если вы получаете ошибки, пожалуйста, отправьте сообщение об ошибке по адресу https://issues.apache.org/jira/projects/BEAM/issues. Перераспределение окон в GlobalWindows устраняет проблему с перестановками?
Похоже, вам не обязательно нужен GroupByKey, потому что вы всегда группируете по одному и тому же ключу. Вместо этого вы можете использовать CombineGlobally для добавления всех элементов в окне вместо GroupByKey (с всегда одним и тем же ключом).
combined = values | beam.CombineGlobally(append_fn).without_defaults()
combined | beam.ParDo(PostProcessFn())
Я не уверен, как работает распределение нагрузки при использовании CombineGlobally, но поскольку он не обрабатывает пары ключ-значение, я бы ожидал, что другой механизм будет выполнять распределение нагрузки.