Подключение ч / б R Studio Server Pro и куст на GCP
Это не вопрос, связанный с программированием, прошу вас об этом.
В настоящее время я настроил два экземпляра на GCP - один - R Studio Server PRO, а другой - мой кластер с Hive DB. Я хочу получить доступ к базе данных в улье с помощью моего сервера rstudio pro. Оба работают на GCP.
Может кто-нибудь, пожалуйста, наставить меня на это? (Я видел статьи по подключению hive на рабочем столе rstudio --->, а также по запуску rstudio-сервера из кластера искр, но мне нужно связать R studio server PRO с базой данных hive, обе работают на GCP:O)
1 ответ
Для дальнейшего использования: R studio - Dataproc -
В этом конкретном случае я отправляю данные из HiveDB в Spark и использую пакет sparklyr для установления соединения на сервере R studio в том же кластере. Вы также можете проверить соединение "Hive-R-JDBC", если хотите напрямую подключиться к Hive.
GCP предлагает R Studio Server PRO на вычислительном движке, но это не является экономически эффективным. Я использовал это в течение приблизительно 8 часов и был выставлен счет приблизительно 21 $. 5 дней в неделю, и вы смотрите на> 100 долларов. Я надеюсь, что следующие шаги помогут вам:
R studio работает через порт 8787. Вам нужно будет добавить этот порт в сетевое правило брандмауэра. Прокрутите к значку гамбургера в вашем GCP и прокрутите вниз до VPC Networks, нажмите на правила брандмауэра и добавьте 8787. После этого это должно выглядеть так 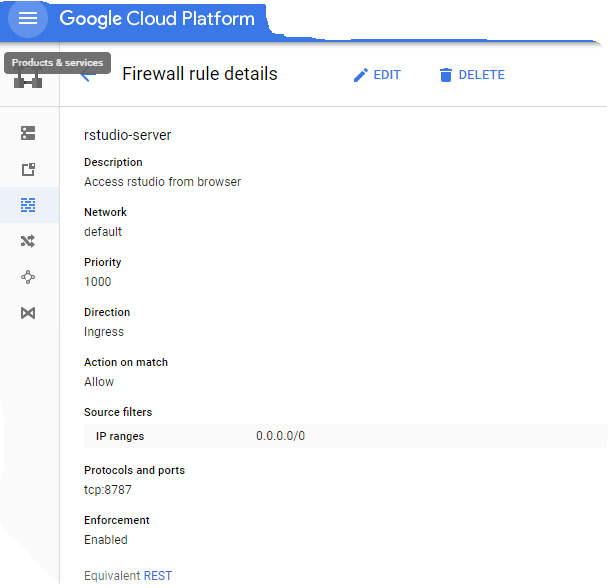
Настройте кластер dataproc в соответствии с вашими требованиями и местоположением. А затем либо SSH в окно браузера, либо запустить через командную строку gcloud. Просто нажмите Enter, когда он предложит запустить в облачной оболочке. 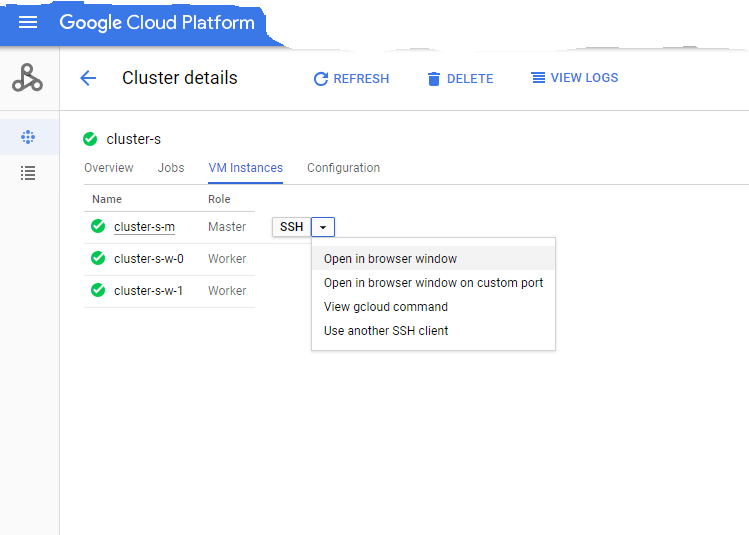
Когда вы окажетесь в командной строке window / gcloud, добавьте пользователя для R-сервера:
sudo adduser rstudio
Установите пароль для этого. Помни это.
Затем перейдите на веб-сайт R studio, перейдите по ссылке https://dailies.rstudio.com/ и нажмите на Ubuntu для сервера R studio. Скопируйте адрес ссылки 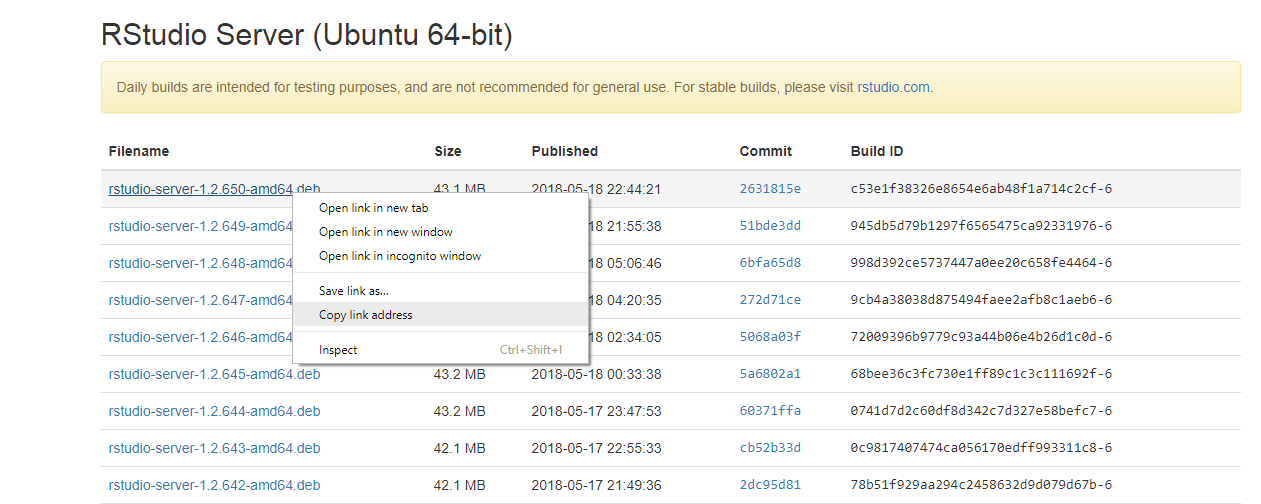
Вернитесь к окну / командной строке и установите его. Вставьте адрес ссылки после sudo wget следующим образом:
sudo wget https://s3.amazonaws.com/rstudio-ide-build/server/trusty/amd64/rstudio-server-1.2.650-amd64.deb
Затем запустите:
sudo apt-get install gdebi-core
Далее следует: Обратите внимание, что это версия r по ссылке выше.
sudo gdebi rstudio-server-1.2.650-amd64.deb
Нажмите Да, чтобы принять, и вы должны увидеть сообщение R сервер активен (работает). Теперь перейдите на вкладку Compute Engine в GCP и скопируйте внешний IP-адрес вашего главного кластера (первый). Теперь откройте новый браузер и введите:
http://<yourexternalIPaddress>:8787
Это должно открыть сервер R studio, теперь введите используемый идентификатор как "rstudio" и пароль, который вы установили ранее. Теперь у вас есть R Studio Server, запущенный и работающий из вашего кластера данных.
** Улей **:
Вернитесь к терминалу и введите
beeline -u jdbc:hive2://localhost:10000/default -n *myusername*@*clustername-m* -d org.apache.hive.jdbc.HiveDriver
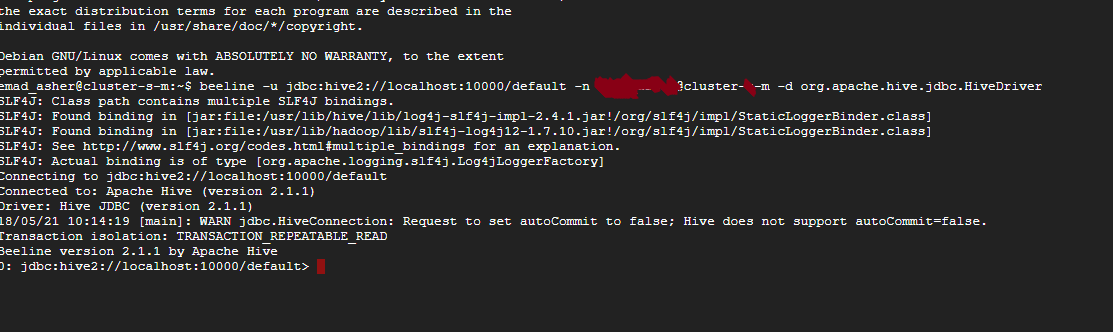
Мы импортируем данные в Hive из нашей HDFS, то есть из облачного хранилища Google. Здесь мы просто копируем данные из нашей корзины в нашу таблицу улья. Введите команду:
CREATE EXTERNAL TABLE <giveatablename>
(location CHAR(1),
dept CHAR(1),
eid INT,
emanager VARCHAR(6))
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION 'gs://<yourgooglestoragebucket>/<foldername>/<filename.csv>';
Теперь у вас есть таблица в Hive yourtablename с функциями -> location, dept, eid и emanager -> из файла csv в облачном хранилище google -> gs://
Теперь выйдите из улья (CTRL+Z) и введите:
ln -s /etc/hive/conf/hive-site.xml /etc/spark/conf/hive-site.xml
Это ссылка на ваш файл конфигурации в кусте для искры. Лучше сделать это, чем скопировать файлы в папку. Как может быть путаница.
Искра:
Войдите в spark-shell, набрав:
spark-shell
Теперь введите:
spark.catalog.listTables.show
Чтобы проверить, есть ли таблица из вашего HiveDb или нет.
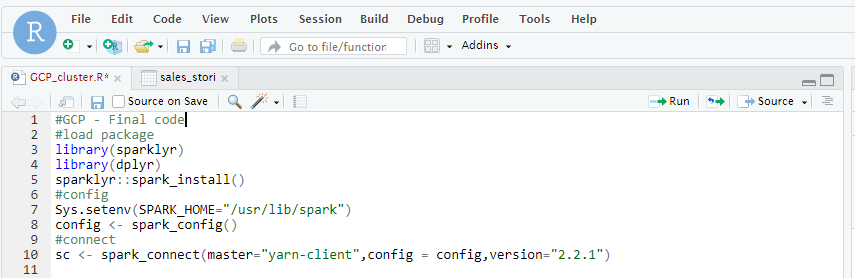
Теперь перейдите в браузер сервера Rstudio и выполните следующие команды:
library(sparklyr)
library(dplyr)
sparklyr::spark_install()
#config
Sys.setenv(SPARK_HOME="/usr/lib/spark")
config <- spark_config()
#connect
sc <- spark_connect(master="yarn-client",config = config,version="2.2.1")
Теперь с правой стороны вы увидите новую вкладку под названием "Соединение" рядом со Средой. Это соединение с вашим искровым кластером, нажмите на него, и оно должно показать ваше имя из Hive.