Преобразовать строку в C++ в верхний регистр
Как можно преобразовать строку в верхний регистр. Примеры, которые я нашел из поиска в Google, имеют дело только с символами.
33 ответа
Алгоритмы ускорения строк:
#include <boost/algorithm/string.hpp>
#include <string>
std::string str = "Hello World";
boost::to_upper(str);
std::string newstr = boost::to_upper_copy<std::string>("Hello World");
#include <algorithm>
#include <string>
std::string str = "Hello World";
std::transform(str.begin(), str.end(),str.begin(), ::toupper);
Краткое решение с использованием C++11 и toupper().
for (auto & c: str) c = toupper(c);
Эта проблема векторизована с SIMD для набора символов ASCII.
Ускорение сравнений:
Предварительное тестирование с x86-64 gcc 5.2 -O3 -march=native на Core2Duo (Мером). Одна и та же строка из 120 символов (смешанный строчный и нестрочный ASCII), преобразованная в цикле 40M раз (без встраивания между файлами, поэтому компилятор не может оптимизировать или вывести любую из нее из цикла). Одинаковые исходные и целевые буферы, поэтому никаких накладных расходов malloc или эффектов памяти / кэша: данные все время находятся в кеше L1, и мы просто привязаны к процессору.
boost::to_upper_copy<char*, std::string>(): 198.0с. Да, Boost 1.58 на Ubuntu 15.10 действительно такой медленный. Я профилировал и пошагово выполнял ассемблер в отладчике, и это очень, очень плохо: есть динамическая переменная локали для каждого символа!!! (dynamic_cast принимает несколько вызовов strcmp). Это происходит сLANG=Cи сLANG=en_CA.UTF-8,Я не тестировал использование RangeT, кроме std::string. Может быть, другая форма
to_upper_copyоптимизирует лучше, но я думаю, что это будет всегдаnew/mallocместо для копии, поэтому его сложнее проверить. Может быть, что-то, что я сделал, отличается от обычного варианта использования, и, возможно, обычно остановленный g++ может вывести настройки локали из цикла за символ. Мой цикл чтения изstd::stringи писать вchar dstbuf[4096]имеет смысл для тестирования.вызов цикла glibc
toupper: 6.67с (без проверкиintрезультат для потенциального многобайтового UTF-8, хотя. Это важно для турецкого языка.)- ASCII-only loop: 8.79s (моя базовая версия для результатов ниже.) Видимо, поиск в таблице быстрее, чем
cmovв любом случае со столом горячим в L1. - ASCII-только авто-векторизация: 2,51 с. (120 символов - это половина пути между наихудшим и лучшим случаями, см. Ниже)
- ASCII-только вручную векторизация: 1,35 с
Смотрите также этот вопрос о toupper() медленный в Windows, когда задан языковой стандарт.
Я был шокирован, что Boost на порядок медленнее, чем другие варианты. Я дважды проверил, что у меня было -O3 включен, и даже пошагово asm, чтобы увидеть, что он делает. Это почти точно такая же скорость с Clang++ 3.8. Это имеет огромные накладные расходы внутри цикла за символ. perf record / report результат (для cycles Перф событие) - это:
32.87% flipcase-clang- libstdc++.so.6.0.21 [.] _ZNK10__cxxabiv121__vmi_class_type_info12__do_dyncastElNS_17__class_type_info10__sub_kindEPKS1_PKvS4_S6_RNS1_16
21.90% flipcase-clang- libstdc++.so.6.0.21 [.] __dynamic_cast
16.06% flipcase-clang- libc-2.21.so [.] __GI___strcmp_ssse3
8.16% flipcase-clang- libstdc++.so.6.0.21 [.] _ZSt9use_facetISt5ctypeIcEERKT_RKSt6locale
7.84% flipcase-clang- flipcase-clang-boost [.] _Z16strtoupper_boostPcRKNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE
2.20% flipcase-clang- libstdc++.so.6.0.21 [.] strcmp@plt
2.15% flipcase-clang- libstdc++.so.6.0.21 [.] __dynamic_cast@plt
2.14% flipcase-clang- libstdc++.so.6.0.21 [.] _ZNKSt6locale2id5_M_idEv
2.11% flipcase-clang- libstdc++.so.6.0.21 [.] _ZNKSt6locale2id5_M_idEv@plt
2.08% flipcase-clang- libstdc++.so.6.0.21 [.] _ZNKSt5ctypeIcE10do_toupperEc
2.03% flipcase-clang- flipcase-clang-boost [.] _ZSt9use_facetISt5ctypeIcEERKT_RKSt6locale@plt
0.08% ...
Автовекторизация
Gcc и clang будут автоматически векторизовывать циклы только тогда, когда счетчик итераций известен перед циклом. (то есть поисковые циклы, такие как реализация на обычном C strlen не будет автовекторизоваться.)
Таким образом, для строк, достаточно маленьких, чтобы поместиться в кэш, мы получаем значительное ускорение для строк длиной ~128 символов strlen первый. Это не будет необходимо для строк с явной длиной (например, C++ std::string).
// char, not int, is essential: otherwise gcc unpacks to vectors of int! Huge slowdown.
char ascii_toupper_char(char c) {
return ('a' <= c && c <= 'z') ? c^0x20 : c; // ^ autovectorizes to PXOR: runs on more ports than paddb
}
// gcc can only auto-vectorize loops when the number of iterations is known before the first iteration. strlen gives us that
size_t strtoupper_autovec(char *dst, const char *src) {
size_t len = strlen(src);
for (size_t i=0 ; i<len ; ++i) {
dst[i] = ascii_toupper_char(src[i]); // gcc does the vector range check with psubusb / pcmpeqb instead of pcmpgtb
}
return len;
}
Любой приличный libc будет иметь эффективный strlen это намного быстрее, чем зацикливание байта за раз, поэтому отдельные векторизованные циклы strlen и toupper быстрее.
Базовая линия: цикл, который проверяет завершающий 0 на лету.
Время для 40M итераций на Core2 (Merom) 2,4 ГГц. GCC 5.2 -O3 -march=native, (Ubuntu 15.10). dst != src (поэтому мы делаем копию), но они не пересекаются (и не находятся рядом). Оба выровнены.
- 15 символьная строка: базовая линия: 1,08 с. Autovec: 1,34 с
- 16 символьная строка: базовая линия: 1,16 с. Autovec: 1,52 с
- 127 символьная строка: базовый уровень: 8,91 с. autovec: 2.98s // не векторная очистка имеет 15 символов для обработки
- 128 символьная строка: базовый уровень: 9,00 с. Autovec: 2.06s
- 129 символьная строка: базовая линия: 9,04. autovec: 2.07s // не векторная очистка имеет 1 символ для обработки
Некоторые результаты немного отличаются от Clang.
Цикл микробенчмарка, который вызывает функцию, находится в отдельном файле. В противном случае он встроен и strlen() выходит из цикла, и он работает значительно быстрее, особенно для 16 символьных струн (0,187 с).
Это имеет основное преимущество, заключающееся в том, что gcc может автоматически векторизовать его для любой архитектуры, но главный недостаток в том, что он медленнее для обычно распространенного случая небольших строк.
Так что есть большие ускорения, но автоматическая векторизация компилятора не делает хороший код, особенно. для очистки последних до 15 символов.
Ручная векторизация с использованием SSE:
Основан на моей функции case-flip, которая инвертирует регистр каждого буквенного символа. Он использует "беззнаковый трюк сравнения", где вы можете сделать low < a && a <= high с одним беззнаковым сравнением путем сдвига диапазона, так что любое значение меньше low оборачивается до значения, которое больше high, (Это работает, если low а также high не слишком далеко друг от друга.)
SSE имеет только знаковое сравнение-большее, но мы все равно можем использовать трюк "беззнаковое сравнение", сдвигая диапазон к нижней части подписанного диапазона: вычтите "a" +128, чтобы алфавитные символы варьировались от -128 до -128+25 (-128+'z'-'a')
Обратите внимание, что сложение 128 и вычитание 128 - это то же самое для 8-битных целых чисел. Керри некуда идти, так что это просто xor (безвоздушное добавление), переворачивающее старшие биты.
#include <immintrin.h>
__m128i upcase_si128(__m128i src) {
// The above 2 paragraphs were comments here
__m128i rangeshift = _mm_sub_epi8(src, _mm_set1_epi8('a'+128));
__m128i nomodify = _mm_cmpgt_epi8(rangeshift, _mm_set1_epi8(-128 + 25)); // 0:lower case -1:anything else (upper case or non-alphabetic). 25 = 'z' - 'a'
__m128i flip = _mm_andnot_si128(nomodify, _mm_set1_epi8(0x20)); // 0x20:lcase 0:non-lcase
// just mask the XOR-mask so elements are XORed with 0 instead of 0x20
return _mm_xor_si128(src, flip);
// it's easier to xor with 0x20 or 0 than to AND with ~0x20 or 0xFF
}
Учитывая, что эта функция работает для одного вектора, мы можем вызвать ее в цикле для обработки всей строки. Поскольку мы уже нацелены на SSE2, мы можем одновременно выполнять векторизованную проверку конца строки.
Мы также можем сделать намного лучше для "очистки" последних до 15 байтов, оставшихся после выполнения векторов 16B: верхний регистр является идемпотентным, поэтому повторная обработка некоторых входных байтов в порядке. Мы делаем невыровненную загрузку последних 16B источника и сохраняем ее в буфере dest, перекрывающем последнее 16B хранилище из цикла.
Единственный раз, когда это не работает, это когда вся строка меньше 16В: даже когда dst=src неатомарное чтение-изменение-запись - это не то же самое, что совсем не затрагивать некоторые байты, и может нарушать многопоточный код.
У нас есть скалярная петля для этого, а также, чтобы получить src выровнены. Поскольку мы не знаем, где будет завершающий 0, выровненная загрузка из src может перейти на следующую страницу и segfault. Если нам нужны какие-либо байты в выровненном фрагменте 16B, всегда безопасно загрузить весь выровненный фрагмент 16B.
Полный источник: в GitHub Gist.
// FIXME: doesn't always copy the terminating 0.
// microbenchmarks are for this version of the code (with _mm_store in the loop, instead of storeu, for Merom).
size_t strtoupper_sse2(char *dst, const char *src_begin) {
const char *src = src_begin;
// scalar until the src pointer is aligned
while ( (0xf & (uintptr_t)src) && *src ) {
*(dst++) = ascii_toupper(*(src++));
}
if (!*src)
return src - src_begin;
// current position (p) is now 16B-aligned, and we're not at the end
int zero_positions;
do {
__m128i sv = _mm_load_si128( (const __m128i*)src );
// TODO: SSE4.2 PCMPISTRI or PCMPISTRM version to combine the lower-case and '\0' detection?
__m128i nullcheck = _mm_cmpeq_epi8(_mm_setzero_si128(), sv);
zero_positions = _mm_movemask_epi8(nullcheck);
// TODO: unroll so the null-byte check takes less overhead
if (zero_positions)
break;
__m128i upcased = upcase_si128(sv); // doing this before the loop break lets gcc realize that the constants are still in registers for the unaligned cleanup version. But it leads to more wasted insns in the early-out case
_mm_storeu_si128((__m128i*)dst, upcased);
//_mm_store_si128((__m128i*)dst, upcased); // for testing on CPUs where storeu is slow
src += 16;
dst += 16;
} while(1);
// handle the last few bytes. Options: scalar loop, masked store, or unaligned 16B.
// rewriting some bytes beyond the end of the string would be easy,
// but doing a non-atomic read-modify-write outside of the string is not safe.
// Upcasing is idempotent, so unaligned potentially-overlapping is a good option.
unsigned int cleanup_bytes = ffs(zero_positions) - 1; // excluding the trailing null
const char* last_byte = src + cleanup_bytes; // points at the terminating '\0'
// FIXME: copy the terminating 0 when we end at an aligned vector boundary
// optionally special-case cleanup_bytes == 15: final aligned vector can be used.
if (cleanup_bytes > 0) {
if (last_byte - src_begin >= 16) {
// if src==dest, this load overlaps with the last store: store-forwarding stall. Hopefully OOO execution hides it
__m128i sv = _mm_loadu_si128( (const __m128i*)(last_byte-15) ); // includes the \0
_mm_storeu_si128((__m128i*)(dst + cleanup_bytes - 15), upcase_si128(sv));
} else {
// whole string less than 16B
// if this is common, try 64b or even 32b cleanup with movq / movd and upcase_si128
#if 1
for (unsigned int i = 0 ; i <= cleanup_bytes ; ++i) {
dst[i] = ascii_toupper(src[i]);
}
#else
// gcc stupidly auto-vectorizes this, resulting in huge code bloat, but no measurable slowdown because it never runs
for (int i = cleanup_bytes - 1 ; i >= 0 ; --i) {
dst[i] = ascii_toupper(src[i]);
}
#endif
}
}
return last_byte - src_begin;
}
Время для 40M итераций на Core2 (Merom) 2,4 ГГц. GCC 5.2 -O3 -march=native, (Ubuntu 15.10). dst != src (поэтому мы делаем копию), но они не пересекаются (и не находятся рядом). Оба выровнены.
- 15 символьная строка: базовая линия: 1,08 с. Autovec: 1,34 с. руководство: 1.29 с
- 16 символьная строка: базовая линия: 1,16 с. Autovec: 1,52 с. руководство: 0.335 с
- 31 символьная строка: руководство: 0,479 с
- 127 символьная строка: базовый уровень: 8,91 с. Autovec: 2,98 с. руководство: 0,925 с
- 128 символьная строка: базовый уровень: 9,00 с. Autovec: 2,06 с. руководство: 0,931 с
- 129 символьная строка: базовая линия: 9,04. Autovec: 2,07 с. руководство: 1.02 с
(На самом деле приурочен с _mm_store в петле, а не _mm_storeu потому что storeu медленнее на Merom, даже когда адрес выровнен. Это нормально на Нехалеме и позже. На данный момент я также оставил код как есть, вместо того, чтобы исправить ошибку в некоторых случаях, когда не копировался завершающий 0, потому что я не хочу переназначать все.)
Так что для коротких строк длиннее 16В это значительно быстрее, чем векторизация. Длина на единицу меньше ширины вектора не представляет проблемы. Они могут быть проблемой при работе на месте из-за остановки магазина. (Но обратите внимание, что все еще хорошо обрабатывать наш собственный вывод, а не исходный ввод, потому что toupper является идемпотентом).
Существует много возможностей для настройки этого для различных вариантов использования, в зависимости от того, что хочет окружающий код, и целевой микроархитектуры. Заставить компилятор выдавать хороший код для части очистки довольно сложно. С помощью ffs(3) (который компилируется в bsf или tzcnt на x86) кажется хорошим, но очевидно, что этот бит нуждается в переосмыслении, так как я заметил ошибку после написания большей части этого ответа (см. комментарии FIXME).
Векторные ускорения для еще меньших струн можно получить с помощью movq или же movd грузы / магазины. Настройте по мере необходимости для вашего варианта использования.
UTF-8:
Мы можем определить, есть ли в нашем векторе байты с установленным старшим битом, и в этом случае вернуться к скалярному циклу с поддержкой utf-8 для этого вектора. dst точка может продвинуться на другую сумму, чем src указатель, но как только мы вернемся к выровненным src указатель, мы все еще будем делать не выровненные векторные хранилища dst,
Для текста, который является UTF-8, но в основном состоит из подмножества ASCII UTF-8, это может быть хорошо: высокая производительность в общем случае с корректным поведением во всех случаях. Когда много не ASCII, это, вероятно, будет хуже, чем оставаться в скалярном цикле с поддержкой UTF-8 все же.
Ускорение английского за счет других языков не является решением на будущее, если недостаток существенный.
Локали известно:
В турецком языке (tr_TR), правильный результат из toupper('i') является 'İ' (U0130), не 'I' (простой ASCII). См . Комментарии Мартина Боннера по вопросу о tolower() быть медленным на Windows.
Мы также можем проверить список исключений и откат к скаляру, например, для многобайтовых символов ввода UTF8.
С такой большой сложностью SSE4.2 PCMPISTRM или что-то может быть в состоянии сделать много наших проверок за один раз.
struct convert {
void operator()(char& c) { c = toupper((unsigned char)c); }
};
// ...
string uc_str;
for_each(uc_str.begin(), uc_str.end(), convert());
Примечание: пара проблем с лучшим решением:
21.5 Утилиты с нулевой терминальной последовательностью
Содержимое этих заголовков должно совпадать с заголовками стандартной библиотеки C
, , , и [...]
Это означает, что
cctypeчлены вполне могут быть макросами, не подходящими для прямого потребления в стандартных алгоритмах.Другая проблема с тем же примером заключается в том, что он не приводит аргумент и не проверяет, что он неотрицательный; это особенно опасно для систем, где равнина
charподписан (Причина в том, что если это реализовано в виде макроса, он, вероятно, будет использовать таблицу поиска и ваши индексы аргументов в этой таблице. Отрицательный индекс даст вам UB.)
string StringToUpper(string strToConvert)
{
for (std::string::iterator p = strToConvert.begin(); strToConvert.end() != p; ++p)
*p = toupper(*p);
return p;
}
Или же,
string StringToUpper(string strToConvert)
{
std::transform(strToConvert.begin(), strToConvert.end(), strToConvert.begin(), ::toupper);
return strToConvert;
}
Следующее работает для меня.
#include <algorithm>
void toUpperCase(std::string& str)
{
std::transform(str.begin(), str.end(), str.begin(), ::toupper);
}
int main()
{
std::string str = "hello";
toUpperCase(&str);
}
У вас есть ASCII или международные символы в строках?
Если это последний случай, "верхний регистр" не так прост, и это зависит от используемого алфавита. Существуют двухпалатные и однопалатные алфавиты. Только двухпалатные алфавиты имеют разные символы для верхнего и нижнего регистра. Кроме того, существуют составные символы, например латинская заглавная буква "DZ" (\u01F1 "DZ"), которые используют так называемый регистр заглавия. Это означает, что изменяется только первый символ (D).
Я предлагаю вам взглянуть на отделение интенсивной терапии и разницу между простым и полным отображением случаев. Это может помочь:
Более быстрый, если вы используете только символы ASCII:
for(i=0;str[i]!=0;i++)
if(str[i]<='z' && str[i]>='a')
str[i]-=32;
Обратите внимание, что этот код работает быстрее, но работает только в ASCII и не является "абстрактным" решением.
Если вам нужны решения UNICODE или более традиционные и абстрактные решения, найдите другие ответы и поработайте с методами строк C++.
Используйте лямбду.
std::string s("change my case");
auto to_upper = [] (char_t ch) { return std::use_facet<std::ctype<char_t>>(std::locale()).toupper(ch); };
std::transform(s.begin(), s.end(), s.begin(), to_upper);
Пока вы в порядке с ASCII-only и можете предоставить действительный указатель на RW-память, в C есть простая и очень эффективная однострочная строка:
void strtoupper(char* str)
{
while (*str) *(str++) = toupper((unsigned char)*str);
}
Это особенно хорошо для простых строк, таких как идентификаторы ASCII, которые вы хотите нормализовать в том же регистре символов. Затем вы можете использовать буфер для создания экземпляра std:string.
#include <string>
#include <locale>
std::string str = "Hello World!";
auto & f = std::use_facet<std::ctype<char>>(std::locale());
f.toupper(str.data(), str.data() + str.size());
Это будет работать лучше, чем все ответы, которые используют глобальную функцию toupper, и, вероятно, это то, что делает boost::to_upper ниже.
Это потому, что::toupper должен искать локаль - потому что она могла быть изменена другим потоком - для каждого вызова, тогда как здесь только вызов locale() имеет это наказание. И поиск локали обычно включает взятие блокировки.
Это также работает с C++98 после замены auto, использования нового неконстантного str.data() и добавления пробела, чтобы прервать закрытие шаблона (">>" до "> >") следующим образом:
std::use_facet<std::ctype<char> > & f =
std::use_facet<std::ctype<char> >(std::locale());
f.toupper(const_cast<char *>(str.data()), str.data() + str.size());
//works for ASCII -- no clear advantage over what is already posted...
std::string toupper(const std::string & s)
{
std::string ret(s.size(), char());
for(unsigned int i = 0; i < s.size(); ++i)
ret[i] = (s[i] <= 'z' && s[i] >= 'a') ? s[i]-('a'-'A') : s[i];
return ret;
}
std::string str = "STriNg oF mIxID CasE lETteRS"
C++ 11
Использование for_each
std::for_each(str.begin(), str.end(), [](char & c){ c = ::toupper(c); });Использование преобразования
std::transform(str.begin(), str.end(), str.begin(), ::toupper);
C++ (только Winodws)
_strupr_s(str, str.length());
C++ (с использованием библиотеки ускорения)
boost::to_upper_copy(str)
typedef std::string::value_type char_t;
char_t up_char( char_t ch )
{
return std::use_facet< std::ctype< char_t > >( std::locale() ).toupper( ch );
}
std::string toupper( const std::string &src )
{
std::string result;
std::transform( src.begin(), src.end(), std::back_inserter( result ), up_char );
return result;
}
const std::string src = "test test TEST";
std::cout << toupper( src );
Ответ на dirkgently очень вдохновляет, но я хочу подчеркнуть, что в связи с озабоченностью, как будет показано ниже,
Как и все другие функции from, поведение std:: toupper не определено, если значение аргумента не может быть представлено как символ без знака и не равно EOF. Чтобы безопасно использовать эти функции с обычными символами (или знаками со знаком), аргумент должен сначала быть преобразован в символ без знака.
Ссылка: std:: toupper
правильное использование std::toupper должно быть:
#include <algorithm>
#include <cctype>
#include <iostream>
#include <iterator>
#include <string>
void ToUpper(std::string& input)
{
std::for_each(std::begin(input), std::end(input), [](char& c) {
c = static_cast<char>(std::toupper(static_cast<unsigned char>(c)));
});
}
int main()
{
std::string s{ "Hello world!" };
std::cout << s << std::endl;
::ToUpper(s);
std::cout << s << std::endl;
return 0;
}
Выход:
Hello world!
HELLO WORLD!
std::string value;
for (std::string::iterator p = value.begin(); value.end() != p; ++p)
*p = toupper(*p);
//Since I work on a MAC, and Windows methods mentioned do not work for me, I //just built this quick method.
string str;
str = "This String Will Print Out in all CAPS";
int len = str.size();
char b;
for (int i = 0; i < len; i++){
b = str[i];
b = toupper(b);
// b = to lower(b); //alternately
str[i] = b;
}
cout<<str;
Попробуйте toupper() функция (#include <ctype.h>). он принимает символы в качестве аргументов, строки состоят из символов, поэтому вам придется перебирать каждый отдельный символ, который при объединении составляет строку
Вот последний код с C++11
std::string cmd = "Hello World";
for_each(cmd.begin(), cmd.end(), [](char& in){ in = ::toupper(in); });
Использование Boost.Text, которое будет работать для текста Unicode
boost::text::text t = "Hello World";
boost::text::text uppered;
boost::text::to_title(t, std::inserter(uppered, uppered.end()));
std::string newstr = uppered.extract();
Мое решение
На основании Kyle_the_hacker -----> Ответ с моими статистами.
Ubuntu
В терминале Список всех языков
locale -a
Установить все локали
sudo apt-get install -y locales locales-all
Скомпилируйте main.cpp
$ g++ main.cpp
Запустить скомпилированную программу
$ ./a.out
Полученные результаты
Zoë Saldaña played in La maldición del padre Cardona. ëèñ αω óóChloë
Zoë Saldaña played in La maldición del padre Cardona. ëèñ αω óóChloë
ZOË SALDAÑA PLAYED IN LA MALDICIÓN DEL PADRE CARDONA. ËÈÑ ΑΩ ÓÓCHLOË
ZOË SALDAÑA PLAYED IN LA MALDICIÓN DEL PADRE CARDONA. ËÈÑ ΑΩ ÓÓCHLOË
zoë saldaña played in la maldición del padre cardona. ëèñ αω óóchloë
zoë saldaña played in la maldición del padre cardona. ëèñ αω óóchloë
WSL от VSCODE 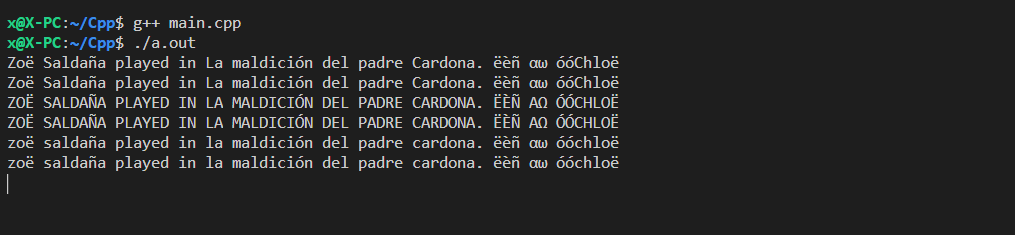
WSL 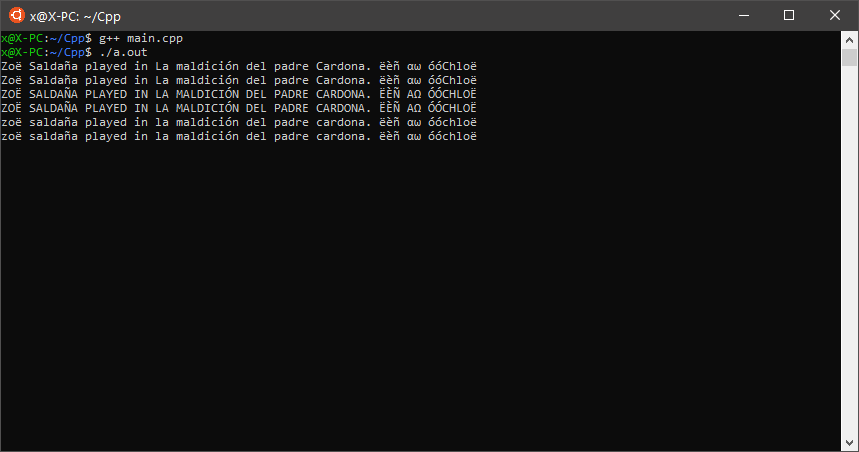
Виртуальная машина Ubuntu 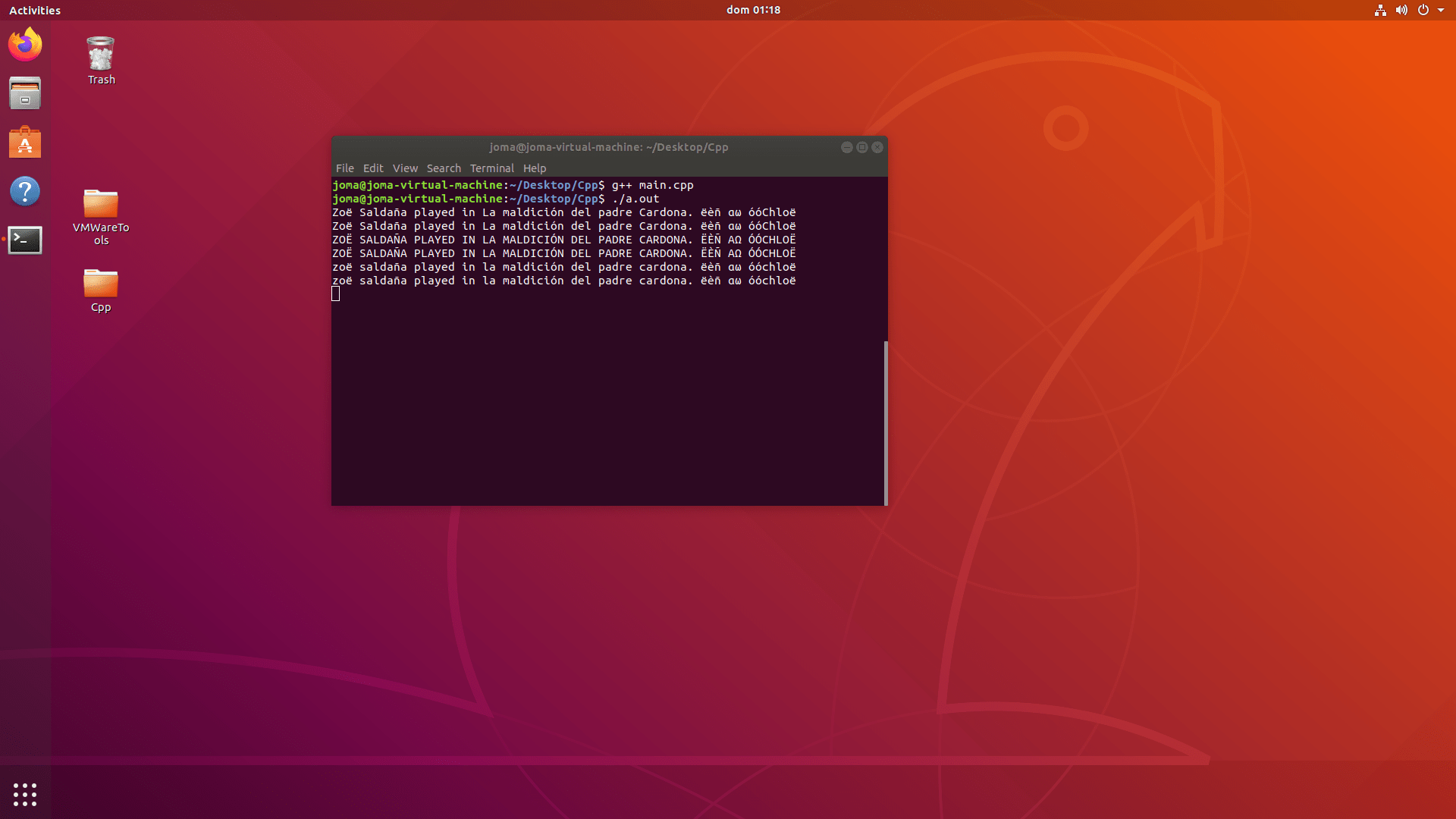
Windows
В cmd запустите инструменты разработчика VCVARS
"C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\Build\vcvars64.bat"
Скомпилируйте main.cpp
> cl /EHa main.cpp /D "_DEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /std:c++17 /DYNAMICBASE "kernel32.lib" "user32.lib" "gdi32.lib" "winspool.lib" "comdlg32.lib" "advapi32.lib" "shell32.lib" "ole32.lib" "oleaut32.lib" "uuid.lib" "odbc32.lib" "odbccp32.lib" /MTd
Compilador de optimización de C/C++ de Microsoft (R) versión 19.27.29111 para x64
(C) Microsoft Corporation. Todos los derechos reservados.
main.cpp
Microsoft (R) Incremental Linker Version 14.27.29111.0
Copyright (C) Microsoft Corporation. All rights reserved.
/out:main.exe
main.obj
kernel32.lib
user32.lib
gdi32.lib
winspool.lib
comdlg32.lib
advapi32.lib
shell32.lib
ole32.lib
oleaut32.lib
uuid.lib
odbc32.lib
odbccp32.lib
Запускаем main.exe
>main.exe
Полученные результаты
Zoë Saldaña played in La maldición del padre Cardona. ëèñ αω óóChloë
Zoë Saldaña played in La maldición del padre Cardona. ëèñ αω óóChloë
ZOË SALDAÑA PLAYED IN LA MALDICIÓN DEL PADRE CARDONA. ËÈÑ ΑΩ ÓÓCHLOË
ZOË SALDAÑA PLAYED IN LA MALDICIÓN DEL PADRE CARDONA. ËÈÑ ΑΩ ÓÓCHLOË
zoë saldaña played in la maldición del padre cardona. ëèñ αω óóchloë
zoë saldaña played in la maldición del padre cardona. ëèñ αω óóchloë
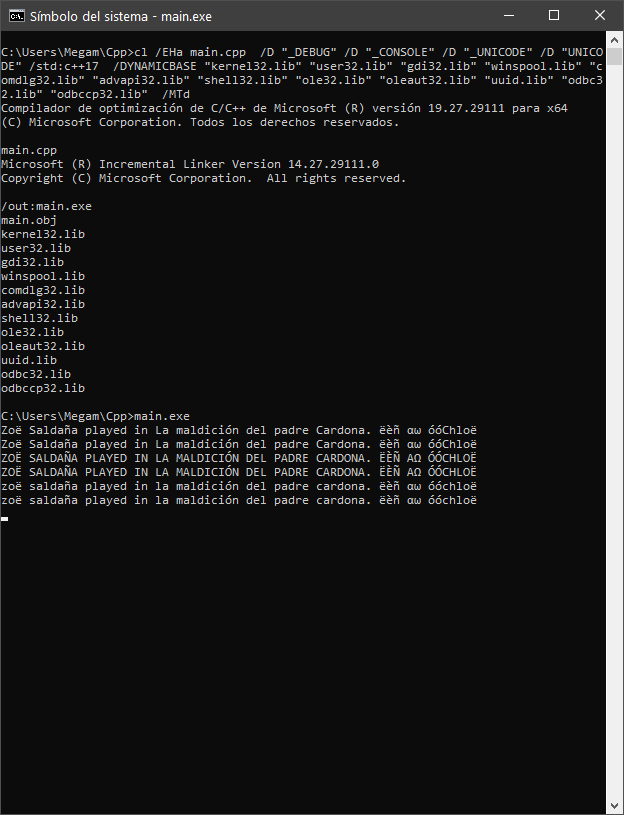
Код - main.cpp
Этот код был протестирован только в Windows x64 и Ubuntu Linux x64.
/*
* Filename: c:\Users\x\Cpp\main.cpp
* Path: c:\Users\x\Cpp
* Filename: /home/x/Cpp/main.cpp
* Path: /home/x/Cpp
* Created Date: Saturday, October 17th 2020, 10:43:31 pm
* Author: Joma
*
* No Copyright 2020
*/
#include <iostream>
#include <locale>
#include <string>
#include <algorithm>
#include <set>
#include <cstdlib>
#include <clocale>
#if defined(_WIN32)
#define WINDOWSLIB 1
#define DLLCALL STDCALL
#define DLLIMPORT _declspec(dllimport)
#define DLLEXPORT _declspec(dllexport)
#define DLLPRIVATE
#define NOMINMAX
#include <Windows.h>
#include <objbase.h>
#include <filesystem>
#include <intrin.h>
#include <conio.h>
#elif defined(__ANDROID__) || defined(ANDROID) //Android
#define ANDROIDLIB 1
#define DLLCALL CDECL
#define DLLIMPORT
#define DLLEXPORT __attribute__((visibility("default")))
#define DLLPRIVATE __attribute__((visibility("hidden")))
#elif defined(__APPLE__) //iOS, Mac OS
#define MACOSLIB 1
#define DLLCALL CDECL
#define DLLIMPORT
#define DLLEXPORT __attribute__((visibility("default")))
#define DLLPRIVATE __attribute__((visibility("hidden")))
#elif defined(__LINUX__) || defined(__gnu_linux__) || defined(__linux__) || defined(__linux) || defined(linux) //_Ubuntu - Fedora - Centos - RedHat
#define LINUXLIB 1
#include <cpuid.h>
#include <experimental/filesystem>
#include <unistd.h>
#include <termios.h>
#define DLLCALL CDECL
#define DLLIMPORT
#define DLLEXPORT __attribute__((visibility("default")))
#define DLLPRIVATE __attribute__((visibility("hidden")))
#define CoTaskMemAlloc(p) malloc(p)
#define CoTaskMemFree(p) free(p)
#elif defined(__EMSCRIPTEN__)
#define EMSCRIPTENLIB 1
#include <unistd.h>
#include <termios.h>
#define DLLCALL
#define DLLIMPORT
#define DLLEXPORT __attribute__((visibility("default")))
#define DLLPRIVATE __attribute__((visibility("hidden")))
#endif
typedef std::string String;
typedef std::wstring WString;
#define LINE_FEED_CHAR (static_cast<char>(10))
enum class ConsoleTextStyle
{
DEFAULT = 0,
BOLD = 1,
FAINT = 2,
ITALIC = 3,
UNDERLINE = 4,
SLOW_BLINK = 5,
RAPID_BLINK = 6,
REVERSE = 7,
};
enum class ConsoleForeground
{
DEFAULT = 39,
BLACK = 30,
DARK_RED = 31,
DARK_GREEN = 32,
DARK_YELLOW = 33,
DARK_BLUE = 34,
DARK_MAGENTA = 35,
DARK_CYAN = 36,
GRAY = 37,
DARK_GRAY = 90,
RED = 91,
GREEN = 92,
YELLOW = 93,
BLUE = 94,
MAGENTA = 95,
CYAN = 96,
WHITE = 97
};
enum class ConsoleBackground
{
DEFAULT = 49,
BLACK = 40,
DARK_RED = 41,
DARK_GREEN = 42,
DARK_YELLOW = 43,
DARK_BLUE = 44,
DARK_MAGENTA = 45,
DARK_CYAN = 46,
GRAY = 47,
DARK_GRAY = 100,
RED = 101,
GREEN = 102,
YELLOW = 103,
BLUE = 104,
MAGENTA = 105,
CYAN = 106,
WHITE = 107
};
class Console
{
public:
static void Clear();
static void WriteLine(const String &s, ConsoleForeground foreground = ConsoleForeground::DEFAULT, ConsoleBackground background = ConsoleBackground::DEFAULT, std::set<ConsoleTextStyle> styles = {});
static void Write(const String &s, ConsoleForeground foreground = ConsoleForeground::DEFAULT, ConsoleBackground background = ConsoleBackground::DEFAULT, std::set<ConsoleTextStyle> styles = {});
static void WriteLine(const WString &s, ConsoleForeground foreground = ConsoleForeground::DEFAULT, ConsoleBackground background = ConsoleBackground::DEFAULT, std::set<ConsoleTextStyle> styles = {});
static void Write(const WString &s, ConsoleForeground foreground = ConsoleForeground::DEFAULT, ConsoleBackground background = ConsoleBackground::DEFAULT, std::set<ConsoleTextStyle> styles = {});
static void WriteLine();
static void Pause();
static int PauseAny(bool printWhenPressed = false);
private:
static void EnableVirtualTermimalProcessing();
static void SetVirtualTerminalFormat(ConsoleForeground foreground, ConsoleBackground background, std::set<ConsoleTextStyle> styles);
static void ResetTerminalFormat();
};
class Strings
{
public:
static String WideStringToString(const WString &wstr);
static WString StringToWideString(const String &str);
static WString ToUpper(const WString &data);
static String ToUpper(const String &data);
static WString ToLower(const WString &data);
static String ToLower(const String &data);
};
String Strings::WideStringToString(const WString &wstr)
{
if (wstr.empty())
{
return String();
}
size_t pos;
size_t begin = 0;
String ret;
size_t size;
#ifdef WINDOWSLIB
pos = wstr.find(static_cast<wchar_t>(0), begin);
while (pos != WString::npos && begin < wstr.length())
{
WString segment = WString(&wstr[begin], pos - begin);
wcstombs_s(&size, nullptr, 0, &segment[0], _TRUNCATE);
String converted = String(size, 0);
wcstombs_s(&size, &converted[0], size, &segment[0], _TRUNCATE);
ret.append(converted);
begin = pos + 1;
pos = wstr.find(static_cast<wchar_t>(0), begin);
}
if (begin <= wstr.length())
{
WString segment = WString(&wstr[begin], wstr.length() - begin);
wcstombs_s(&size, nullptr, 0, &segment[0], _TRUNCATE);
String converted = String(size, 0);
wcstombs_s(&size, &converted[0], size, &segment[0], _TRUNCATE);
converted.resize(size - 1);
ret.append(converted);
}
#elif defined LINUXLIB
pos = wstr.find(static_cast<wchar_t>(0), begin);
while (pos != WString::npos && begin < wstr.length())
{
WString segment = WString(&wstr[begin], pos - begin);
size = wcstombs(nullptr, segment.c_str(), 0);
String converted = String(size, 0);
wcstombs(&converted[0], segment.c_str(), converted.size());
ret.append(converted);
ret.append({0});
begin = pos + 1;
pos = wstr.find(static_cast<wchar_t>(0), begin);
}
if (begin <= wstr.length())
{
WString segment = WString(&wstr[begin], wstr.length() - begin);
size = wcstombs(nullptr, segment.c_str(), 0);
String converted = String(size, 0);
wcstombs(&converted[0], segment.c_str(), converted.size());
ret.append(converted);
}
#elif defined MACOSLIB
#endif
return ret;
}
WString Strings::StringToWideString(const String &str)
{
if (str.empty())
{
return WString();
}
size_t pos;
size_t begin = 0;
WString ret;
size_t size;
#ifdef WINDOWSLIB
pos = str.find(static_cast<char>(0), begin);
while (pos != String::npos)
{
String segment = String(&str[begin], pos - begin);
WString converted = WString(segment.size() + 1, 0);
mbstowcs_s(&size, &converted[0], converted.size(), &segment[0], _TRUNCATE);
converted.resize(size - 1);
ret.append(converted);
ret.append({0});
begin = pos + 1;
pos = str.find(static_cast<char>(0), begin);
}
if (begin < str.length())
{
String segment = String(&str[begin], str.length() - begin);
WString converted = WString(segment.size() + 1, 0);
mbstowcs_s(&size, &converted[0], converted.size(), &segment[0], _TRUNCATE);
converted.resize(size - 1);
ret.append(converted);
}
#elif defined LINUXLIB
pos = str.find(static_cast<char>(0), begin);
while (pos != String::npos)
{
String segment = String(&str[begin], pos - begin);
WString converted = WString(segment.size(), 0);
size = mbstowcs(&converted[0], &segment[0], converted.size());
converted.resize(size);
ret.append(converted);
ret.append({0});
begin = pos + 1;
pos = str.find(static_cast<char>(0), begin);
}
if (begin < str.length())
{
String segment = String(&str[begin], str.length() - begin);
WString converted = WString(segment.size(), 0);
size = mbstowcs(&converted[0], &segment[0], converted.size());
converted.resize(size);
ret.append(converted);
}
#elif defined MACOSLIB
#endif
return ret;
}
WString Strings::ToUpper(const WString &data)
{
WString result = data;
auto &f = std::use_facet<std::ctype<wchar_t>>(std::locale());
f.toupper(&result[0], &result[0] + result.size());
return result;
}
String Strings::ToUpper(const String &data)
{
return WideStringToString(ToUpper(StringToWideString(data)));
}
WString Strings::ToLower(const WString &data)
{
WString result = data;
auto &f = std::use_facet<std::ctype<wchar_t>>(std::locale());
f.tolower(&result[0], &result[0] + result.size());
return result;
}
String Strings::ToLower(const String &data)
{
return WideStringToString(ToLower(StringToWideString(data)));
}
void Console::Clear()
{
#ifdef WINDOWSLIB
std::system(u8"cls");
#elif defined LINUXLIB
std::system(u8"clear");
#elif defined EMSCRIPTENLIB
emscripten::val::global()["console"].call<void>(u8"clear");
#elif defined MACOSLIB
#endif
}
void Console::Pause()
{
char c;
do
{
c = getchar();
} while (c != LINE_FEED_CHAR);
}
int Console::PauseAny(bool printWhenPressed)
{
int ch;
#ifdef WINDOWSLIB
ch = _getch();
#elif defined LINUXLIB
struct termios oldt, newt;
tcgetattr(STDIN_FILENO, &oldt);
newt = oldt;
newt.c_lflag &= ~(ICANON | ECHO);
tcsetattr(STDIN_FILENO, TCSANOW, &newt);
ch = getchar();
tcsetattr(STDIN_FILENO, TCSANOW, &oldt);
#elif defined MACOSLIB
#endif
return ch;
}
void Console::EnableVirtualTermimalProcessing()
{
#if defined WINDOWSLIB
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE);
DWORD dwMode = 0;
GetConsoleMode(hOut, &dwMode);
if (!(dwMode & ENABLE_VIRTUAL_TERMINAL_PROCESSING))
{
dwMode |= ENABLE_VIRTUAL_TERMINAL_PROCESSING;
SetConsoleMode(hOut, dwMode);
}
#endif
}
void Console::ResetTerminalFormat()
{
std::cout << u8"\033[0m";
}
void Console::SetVirtualTerminalFormat(ConsoleForeground foreground, ConsoleBackground background, std::set<ConsoleTextStyle> styles)
{
String format = u8"\033[";
format.append(std::to_string(static_cast<int>(foreground)));
format.append(u8";");
format.append(std::to_string(static_cast<int>(background)));
if (styles.size() > 0)
{
for (auto it = styles.begin(); it != styles.end(); ++it)
{
format.append(u8";");
format.append(std::to_string(static_cast<int>(*it)));
}
}
format.append(u8"m");
std::cout << format;
}
void Console::Write(const String &s, ConsoleForeground foreground, ConsoleBackground background, std::set<ConsoleTextStyle> styles)
{
EnableVirtualTermimalProcessing();
SetVirtualTerminalFormat(foreground, background, styles);
String str = s;
#ifdef WINDOWSLIB
WString unicode = Strings::StringToWideString(str);
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), unicode.c_str(), static_cast<DWORD>(unicode.length()), nullptr, nullptr);
#elif defined LINUXLIB
std::cout << str;
#elif defined MACOSLIB
#endif
ResetTerminalFormat();
}
void Console::WriteLine(const String &s, ConsoleForeground foreground, ConsoleBackground background, std::set<ConsoleTextStyle> styles)
{
Write(s, foreground, background, styles);
std::cout << std::endl;
}
void Console::Write(const WString &s, ConsoleForeground foreground, ConsoleBackground background, std::set<ConsoleTextStyle> styles)
{
EnableVirtualTermimalProcessing();
SetVirtualTerminalFormat(foreground, background, styles);
WString str = s;
#ifdef WINDOWSLIB
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), str.c_str(), static_cast<DWORD>(str.length()), nullptr, nullptr);
#elif defined LINUXLIB
std::cout << Strings::WideStringToString(str); //NEED TO BE FIXED. ADD locale parameter
#elif defined MACOSLIB
#endif
ResetTerminalFormat();
}
void Console::WriteLine(const WString &s, ConsoleForeground foreground, ConsoleBackground background, std::set<ConsoleTextStyle> styles)
{
Write(s, foreground, background, styles);
std::cout << std::endl;
}
int main()
{
std::locale::global(std::locale(u8"en_US.UTF-8"));
String dataStr = u8"Zoë Saldaña played in La maldición del padre Cardona. ëèñ αω óóChloë";
WString dataWStr = L"Zoë Saldaña played in La maldición del padre Cardona. ëèñ αω óóChloë";
std::string locale = u8"";
//std::string locale = u8"de_DE.UTF-8";
//std::string locale = u8"en_US.UTF-8";
Console::WriteLine(dataStr);
Console::WriteLine(dataWStr);
dataStr = Strings::ToUpper(dataStr);
dataWStr = Strings::ToUpper(dataWStr);
Console::WriteLine(dataStr);
Console::WriteLine(dataWStr);
dataStr = Strings::ToLower(dataStr);
dataWStr = Strings::ToLower(dataWStr);
Console::WriteLine(dataStr);
Console::WriteLine(dataWStr);
Console::PauseAny();
return 0;
}
Если вы хотите использовать только заглавные буквы, попробуйте эту функцию.
#include <iostream>
using namespace std;
string upper(string text){
string upperCase;
for(int it : text){
if(it>96&&it<123){
upperCase += char(it-32);
}else{
upperCase += char(it);
}
}
return upperCase;
}
int main() {
string text = "^_abcdfghopqrvmwxyz{|}";
cout<<text<<"/";
text = upper(text);
cout<<text;
return 0;
}
Ошибка: циклы for на основе диапазона недопустимы в режиме C++98
Не уверен, что есть встроенная функция. Попробуй это:
Включите библиотеки ctype.h ИЛИ cctype, а также stdlib.h как часть директив препроцессора.
string StringToUpper(string strToConvert)
{//change each element of the string to upper case
for(unsigned int i=0;i<strToConvert.length();i++)
{
strToConvert[i] = toupper(strToConvert[i]);
}
return strToConvert;//return the converted string
}
string StringToLower(string strToConvert)
{//change each element of the string to lower case
for(unsigned int i=0;i<strToConvert.length();i++)
{
strToConvert[i] = tolower(strToConvert[i]);
}
return strToConvert;//return the converted string
}
Мое решение (очистка 6-го бита для альфы):
#include <ctype.h>
inline void toupper(char* str)
{
while (str[i]) {
if (islower(str[i]))
str[i] &= ~32; // Clear bit 6 as it is what differs (32) between Upper and Lowercases
i++;
}
}
template<size_t size>
char* toupper(char (&dst)[size], const char* src) {
// generate mapping table once
static char maptable[256];
static bool mapped;
if (!mapped) {
for (char c = 0; c < 256; c++) {
if (c >= 'a' && c <= 'z')
maptable[c] = c & 0xdf;
else
maptable[c] = c;
}
mapped = true;
}
// use mapping table to quickly transform text
for (int i = 0; *src && i < size; i++) {
dst[i] = maptable[*(src++)];
}
return dst;
}
Без использования каких-либо библиотек:
std::string YourClass::Uppercase(const std::string & Text)
{
std::string UppperCaseString;
UppperCaseString.reserve(Text.size());
for (std::string::const_iterator it=Text.begin(); it<Text.end(); ++it)
{
UppperCaseString.push_back(((0x60 < *it) && (*it < 0x7B)) ? (*it - static_cast<char>(0x20)) : *it);
}
return UppperCaseString;
}
Эта функция C++ всегда возвращает строку верхнего регистра...
#include <locale>
#include <string>
using namespace std;
string toUpper (string str){
locale loc;
string n;
for (string::size_type i=0; i<str.length(); ++i)
n += toupper(str[i], loc);
return n;
}
Все эти решения на этой странице сложнее, чем они должны быть.
Сделай это
RegName = "SomE StRing That you wAnt ConvErTed";
NameLength = RegName.Size();
for (int forLoop = 0; forLoop < NameLength; ++forLoop)
{
RegName[forLoop] = tolower(RegName[forLoop]);
}
RegName твой string, Получите ваш размер строки не используйте string.size() как ваш настоящий тестер, очень грязный и может вызвать проблемы. затем. самый основной for петля.
помните, что размер строки тоже возвращает разделитель, поэтому используйте <, а не <= в тесте цикла.
вывод будет: некоторая строка, которую вы хотите преобразовать
Вы можете просто использовать это в C++17
for(auto i : str) putchar(toupper(i));