Обход графика Neo4j в порядке возрастания весов отношений с использованием Cypher
Представьте, что у меня есть следующий график с весами ребер:
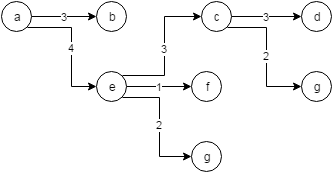
Я хочу знать, могу ли я выполнить обход, начинающийся в узле a и следующих ребрах с увеличением порядка их веса, используя CYPHER. То есть выше должно вернуться (a)-4->(e)-3->(c)-3->(d)
Возможно ли это с помощью шифра?
2 ответа
Ваше описание немного неверно (на основе вашего примера), так как вы не хотите проходить отношения с возрастающим весом, вы хотите проходить отношения (отношения) с максимальным весом на каждом шаге.
Вы не можете сделать это универсальным способом в Cypher, потому что результат создается итеративно, и вы не можете знать максимальную длину пути результата.
В Cypher вам придется
- построить все пути
- отфильтровать их по весу первого отношения
- отфильтруйте оставшиеся по весу второго отношения (если оно существует)
- и т.п.
Декларативная природа Cypher на самом деле не совместима: она будет громоздкой и, вероятно, медленной. Было бы намного проще построить процедуру или функцию (в предстоящем Neo4j 3.1), проходящую самый длинный путь (пути), с PathExpander возвращает только отношения с максимальным весом из текущего узла.
Как заявил @FrankPavageau, кодирование решения на Java может быть менее громоздким и быстрым. Тем не менее, используя преимущества существующей процедуры APOC apoc.periodic.commit, вам не нужно ничего реализовывать в Java.
apoc.periodic.commit будет многократно выполнять запрос Cypher, пока не вернет значение 0 или не даст результатов вообще. Вот пример того, как использовать его для решения вашей проблемы.
Во-первых, давайте создадим ваши образцы данных:
CREATE (a:Foo {id: 'a'}), (b:Foo {id: 'b'}), (c:Foo {id: 'c'}), (d:Foo {id: 'd'}), (e:Foo {id: 'e'}), (f:Foo {id: 'f'}), (g:Foo {id: 'g'}),
(a)-[:NEXT {value: 3}]->(b),
(a)-[:NEXT {value: 4}]->(e),
(e)-[:NEXT {value: 3}]->(c),
(e)-[:NEXT {value: 1}]->(f),
(e)-[:NEXT {value: 2}]->(g),
(c)-[:NEXT {value: 3}]->(d),
(c)-[:NEXT {value: 2}]->(g);
Эта техника включает в себя 3 запроса с вашей стороны:
Запрос на создание временного узла с
Tempметка (для сохранения состояния между повторными выполнениями, выполненными на шаге 2 ниже, и для сохранения окончательных результатов). (В примерах данных начальный узел имеетidизa.)MERGE (temp:Temp) SET temp = {values: [], ids: ['a']};Запрос для вызова
apoc.periodic.commitвыполнять повторные исполнения переданного оператора Cypher. Каждый раз, когда выполняется оператор Cypher, он начинается с последнего найденного узла (тот, чейidнаходится в хвостовой частиtemp.ids) и пытается найти следующий узел, отношение которого имеет наибольшееvalueзначение. Если последний узел был листовым, то оператор Cypher ничего не возвращает (так как второйMATCHпотерпит неудачу, прерывая утверждение) - что приведет к прекращению процедуры; в противном случае, заявление Cypher добавитmaxзначение дляtemp.valuesи соответствующий узелidвtemp.idsи верните 1.CALL apoc.periodic.commit(" MATCH (temp:Temp) MATCH (:Foo {id: LAST(temp.ids)})-[n:NEXT]->(f:Foo) WITH temp, REDUCE(s = {max: 0}, x IN COLLECT({v: n.value, id: f.id}) | CASE WHEN x.v > s.max THEN {max: x.v, id: x.id} ELSE s END ) AS curr SET temp.values = temp.values + curr.max, temp.ids = temp.ids + curr.id RETURN 1; ", NULL);Запрос для получения окончательных результатов.
idsКоллекция будет идентификаторы узлов по "максимальному пути", аvaluesколлекция будетvaluesизNEXTотношения по тому же пути.MATCH (temp:Temp) RETURN temp;
Вот результат:
╒══════════════════════════════════════╕
│temp │
╞══════════════════════════════════════╡
│{values: [4, 3, 3], ids: [a, e, c, d]}│
└──────────────────────────────────────┘