Выводить строки юникода в консольное приложение Windows
Привет, я пытался вывести строку Unicode на консоль с iostreams и не удалось.
Я нашел это: Использование шрифта Unicode в консольном приложении C++, и этот фрагмент работает.
SetConsoleOutputCP(CP_UTF8);
wchar_t s[] = L"èéøÞǽлљΣæča";
int bufferSize = WideCharToMultiByte(CP_UTF8, 0, s, -1, NULL, 0, NULL, NULL);
char* m = new char[bufferSize];
WideCharToMultiByte(CP_UTF8, 0, s, -1, m, bufferSize, NULL, NULL);
wprintf(L"%S", m);
Однако я не нашел способа правильно выводить юникод с помощью iostreams. Какие-либо предложения?
Это не работает:
SetConsoleOutputCP(CP_UTF8);
utf8_locale = locale(old_locale,new boost::program_options::detail::utf8_codecvt_facet());
wcout.imbue(utf8_locale);
wcout << L"¡Hola!" << endl;
РЕДАКТИРОВАТЬ Я не мог найти никакого другого решения, кроме как обернуть этот фрагмент в потоке. Надеюсь, у кого-то есть идеи получше.
//Unicode output for a Windows console
ostream &operator-(ostream &stream, const wchar_t *s)
{
int bufSize = WideCharToMultiByte(CP_UTF8, 0, s, -1, NULL, 0, NULL, NULL);
char *buf = new char[bufSize];
WideCharToMultiByte(CP_UTF8, 0, s, -1, buf, bufSize, NULL, NULL);
wprintf(L"%S", buf);
delete[] buf;
return stream;
}
ostream &operator-(ostream &stream, const wstring &s)
{
stream - s.c_str();
return stream;
}
18 ответов
Я проверил решение здесь, используя Visual Studio 2010. Через эту статью MSDN и сообщение в блоге MSDN. Хитрость - это неясный призыв к _setmode(..., _O_U16TEXT),
Решение:
#include <iostream>
#include <io.h>
#include <fcntl.h>
int wmain(int argc, wchar_t* argv[])
{
_setmode(_fileno(stdout), _O_U16TEXT);
std::wcout << L"Testing unicode -- English -- Ελληνικά -- Español." << std::endl;
}
Скриншот:

Вы можете использовать библиотеку с открытым исходным кодом {fmt} для переносимой печати текста Unicode, в том числе в Windows, например:
#include <fmt/core.h>
int main() {
fmt::print("èéøÞǽлљΣæča");
}
Выход:
èéøÞǽлљΣæča
Это требует компиляции с
/utf-8 вариант компилятора в MSVC.
Я не рекомендую использовать
wcout потому что он непереносимый и даже не работает в Windows без дополнительных усилий, например:
std::wcout << L"èéøÞǽлљΣæča";
напечатает:
├и├й├╕├Ю╟╜╨╗╤Щ╬г├ж─Нa
в русской Windows (ACP 1251, консоль CP 866).
Отказ от ответственности: я являюсь автором {fmt}.
Юникод Hello World на китайском языке
Вот Hello World на китайском языке. На самом деле это просто "Привет". Я проверил это на Windows 10, но я думаю, что это может работать с Windows Vista. До Windows Vista будет сложно, если вам нужно программное решение, вместо настройки консоли / реестра и т. Д. Может быть, посмотрите здесь, если вам действительно нужно сделать это в Windows 7: Изменить шрифт консоли Windows 7
Я не хочу утверждать, что это единственное решение, но это то, что сработало для меня.
Контур
- Настройка проекта Unicode
- Установите кодовую страницу консоли в Юникод
- Найдите и используйте шрифт, который поддерживает символы, которые вы хотите отобразить
- Используйте язык, который вы хотите отобразить
- Используйте вывод широких символов, т.е.
std::wcout
1 Настройка проекта
Я использую Visual Studio 2017 CE. Я создал пустое консольное приложение. Настройки по умолчанию в порядке. Но если у вас возникли проблемы или вы используете другой ide, вы можете проверить это:
В свойствах вашего проекта найдите свойства конфигурации -> Общие -> Стандартные настройки проекта -> Набор символов. Это должно быть "Использовать набор символов Юникода", а не "Многобайтовый". Это определит _UNICODE а также UNICODE макросы препроцессора для вас.
int wmain(int argc, wchar_t* argv[])
Также я думаю, что мы должны использовать wmain функция вместо main, Они оба работают, но в среде Unicode wmain может быть удобнее
Также мои исходные файлы имеют кодировку UTF-16-LE, которая, по-видимому, используется по умолчанию в Visual Studio 2017.
2. Консольная кодовая страница
Это совершенно очевидно. Нам нужна кодовая страница Unicode в консоли. Если вы хотите проверить кодовую страницу по умолчанию, просто откройте консоль и введите chcp без каких-либо аргументов. Мы должны изменить его на 65001, который является кодовой страницей UTF-8. Идентификаторы кодовой страницы Windows Для этой кодовой страницы есть макрос препроцессора: CP_UTF8, Мне нужно было установить и кодовую страницу ввода и вывода. Когда я пропустил любой из них, вывод был неверным.
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
Вы также можете проверить логические возвращаемые значения этих функций.
3. Выберите шрифт
До сих пор я не нашел консольный шрифт, который поддерживает каждый символ. Поэтому мне пришлось выбрать один. Если вы хотите вывести символы, которые частично доступны только одним шрифтом и частично другим шрифтом, то я считаю, что найти решение невозможно. Только возможно, если есть шрифт, который поддерживает каждый символ. Но также я не смотрел, как установить шрифт.
Я думаю, что невозможно использовать два разных шрифта в одном и том же окне консоли одновременно.
Как найти совместимый шрифт? Откройте консоль, перейдите в свойства окна консоли, нажав на значок в левом верхнем углу окна. Перейдите на вкладку "Шрифты", выберите шрифт и нажмите "ОК". Затем попробуйте ввести свои символы в окне консоли. Повторяйте это, пока не найдете шрифт, с которым вы можете работать. Затем запишите название шрифта.
Также вы можете изменить размер шрифта в окне свойств. Если вы нашли нужный вам размер, запишите значения размеров, которые отображаются в окне свойств в разделе "выбранный шрифт". Он покажет ширину и высоту в пикселях.
Чтобы фактически установить шрифт программно, вы используете:
CONSOLE_FONT_INFOEX fontInfo;
// ... configure fontInfo
SetCurrentConsoleFontEx(hConsole, false, &fontInfo);
Смотрите мой пример в конце этого ответа для деталей. Или посмотрите это в прекрасном руководстве: SetCurrentConsoleFont. Эта функция существует только с Windows Vista.
4. Установите локаль
Вам нужно будет установить языковой стандарт на язык, символы которого вы хотите напечатать.
char* a = setlocale(LC_ALL, "chinese");
Возвращаемое значение интересно. Он будет содержать строку для точного описания выбранной локали. Просто попробуйте:-) Я проверил с chinese а также german, Больше информации: setlocale
5. Используйте широкий вывод символов
Не так много, чтобы сказать здесь. Если вы хотите выводить широкие символы, используйте это, например:
std::wcout << L"你好" << std::endl;
Ох, и не забывайте L префикс для широких символов! И если вы набираете буквальные символы Unicode, подобные этим, в исходном файле, исходный файл должен быть в кодировке Unicode. Как по умолчанию в Visual Studio UTF-16-LE. Или, возможно, используйте notepad++ и установите кодировку UCS-2 LE BOM,
пример
Наконец я собрал все это в качестве примера:
#include <Windows.h>
#include <iostream>
#include <io.h>
#include <fcntl.h>
#include <locale.h>
#include <wincon.h>
int wmain(int argc, wchar_t* argv[])
{
SetConsoleTitle(L"My Console Window - 你好");
HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDLE);
char* a = setlocale(LC_ALL, "chinese");
SetConsoleOutputCP(CP_UTF8);
SetConsoleCP(CP_UTF8);
CONSOLE_FONT_INFOEX fontInfo;
fontInfo.cbSize = sizeof(fontInfo);
fontInfo.FontFamily = 54;
fontInfo.FontWeight = 400;
fontInfo.nFont = 0;
const wchar_t myFont[] = L"KaiTi";
fontInfo.dwFontSize = { 18, 41 };
std::copy(myFont, myFont + (sizeof(myFont) / sizeof(wchar_t)), fontInfo.FaceName);
SetCurrentConsoleFontEx(hConsole, false, &fontInfo);
std::wcout << L"Hello World!" << std::endl;
std::wcout << L"你好!" << std::endl;
return 0;
}
Ура!
Я использовал слово-палиндром на иврите, поскольку консольное приложение может отображать строки, написанные справа налево, в обратном порядке.
Вот мой мультиплатформенный код:
#include <iostream>
#ifdef _WIN32 // #A
#include <io.h> // #B
#include <fcntl.h> // #C
#else // #D
#include <locale> // #E
#endif
int main()
{
#ifdef _WIN32 // #A
_setmode(_fileno(stdout), _O_U16TEXT); // #F
std::wcout << L"אבא" << std::endl; // #G
#else // #D
std::locale::global(std::locale("")); // #H
std::wcout.imbue(std::locale()); // #I
std::wcout << L"אבא" << std::endl; // #G
#endif
}
#A — директива препроцессора для кода, специфичного для Windows.
#B — включить библиотеку io.h для низкоуровневых операций ввода-вывода.
#C — включить библиотеку fcntl.h для операций управления файлами.
#D — директива препроцессора для кода, отличного от Windows.
#E — включить библиотеку локали для операций, специфичных для локали.
#F — установить режим стандартного вывода для использования Unicode.
#G — вывести на консоль слово на иврите
#H — установить глобальную локаль на предпочитаемую пользователем локаль.
#I — установить локаль wcout на глобальную локаль
У wcout должен быть языковой стандарт, отличный от CRT. Вот как это можно исправить:
int _tmain(int argc, _TCHAR* argv[])
{
char* locale = setlocale(LC_ALL, "English"); // Get the CRT's current locale.
std::locale lollocale(locale);
setlocale(LC_ALL, locale); // Restore the CRT.
std::wcout.imbue(lollocale); // Now set the std::wcout to have the locale that we got from the CRT.
std::wcout << L"¡Hola!";
std::cin.get();
return 0;
}
Я только что проверил это, и он показывает строку здесь абсолютно нормально.
SetConsoleCP() и chcp не совпадают!
Возьмите этот фрагмент программы:
SetConsoleCP(65001) // 65001 = UTF-8
static const char s[]="tränenüberströmt™\n";
DWORD slen=lstrlen(s);
WriteConsoleA(GetStdHandle(STD_OUTPUT_HANDLE),s,slen,&slen,NULL);
Исходный код должен быть сохранен как UTF-8 без спецификации (Метка порядка байтов; Подпись). Затем компилятор Microsoft cl.exe принимает строки UTF-8 как есть.
Если этот код сохраняется с BOM, cl.exe перекодирует строку в ANSI (т. Е. CP1252), что не соответствует CP65001 (= UTF-8).
Измените шрифт дисплея на Lucidia Console, иначе вывод UTF-8 не будет работать вообще.
- Тип:
chcp - Ответ:
850 - Тип:
test.exe - Ответ:
tr├ñnen├╝berstr├ÂmtÔäó - Тип:
chcp - Ответ:
65001- Этот параметр был измененSetConsoleCP()но без полезного эффекта. - Тип:
chcp 65001 - Тип:
test.exe - Ответ:
tränenüberströmt™- Теперь все в порядке.
Протестировано с: немецкий Windows XP SP3
Решение 1: используйте WCHAR
Одна вещь, которая всегда работает: используйте широкий символ везде. Нравиться,
const wchar_t* str = L"你好\n";
DWORD nwritten = 0;
WriteConsoleW(GetStdHandle(STD_OUTPUT_HANDLE), str, 3, &nwritten, NULL);
Юникод не зависит от языка. Вы можете использовать любой язык, и у вас не будет проблем с кодировкой. Вы хотите использовать UTF-8? Отлично. Используйте MultiByteToWideChar, чтобы сначала преобразовать широкую строку char.
Прежде чем продолжить чтение другого решения ниже, обратите внимание, что оно имеет уникальное преимущество: оно не зависит от системы или настроек локали пользователя.
Решение 2. Правильно установите языковой стандарт системы и языковой стандарт пользователя. И они должны быть одинаковыми.
Я предполагаю, что локаль UTF-8 для Windows еще не представлена. Затем вам нужно знать, какой язык (китайский, французский?) вы бы использовали, и изменить настройки системы, чтобы они соответствовали ему. Есть настройка системного уровня: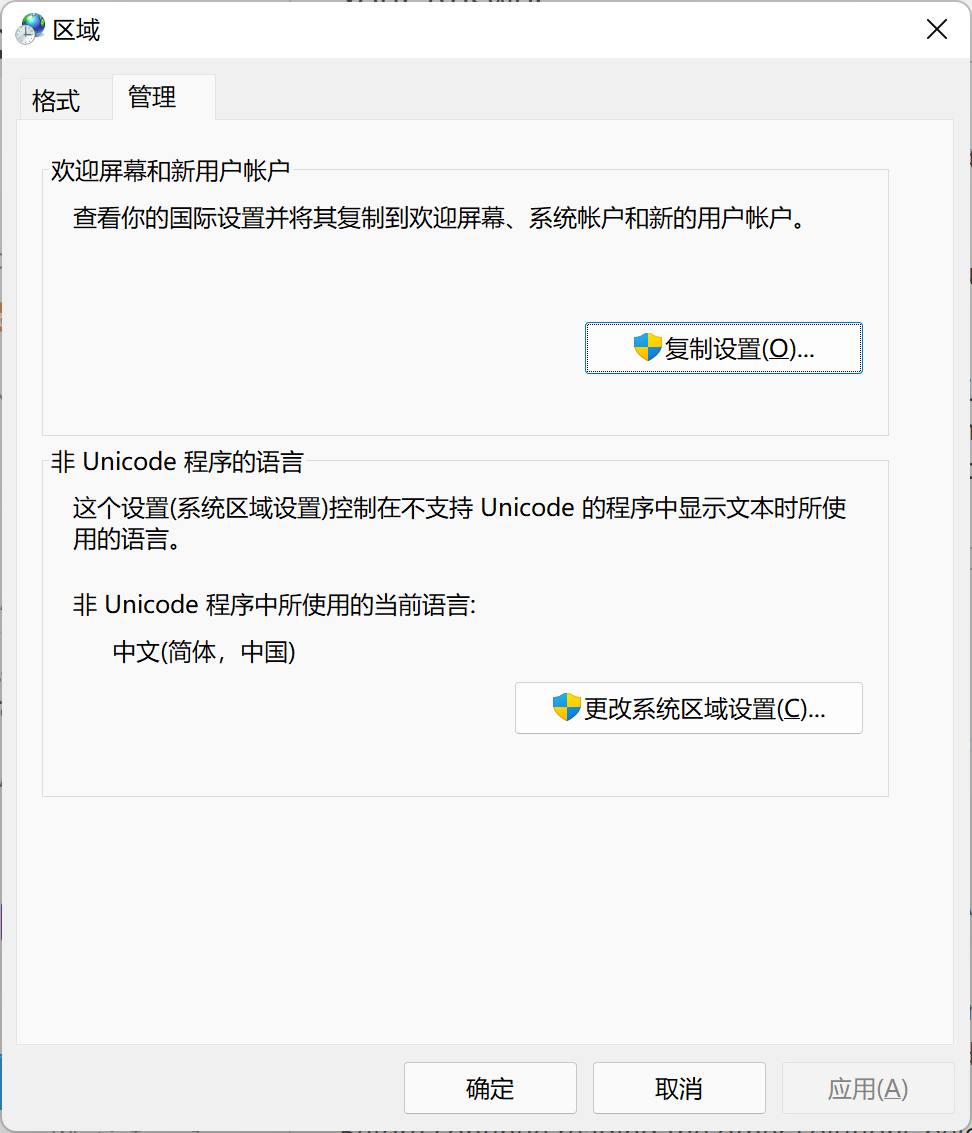
И настройка уровня пользователя: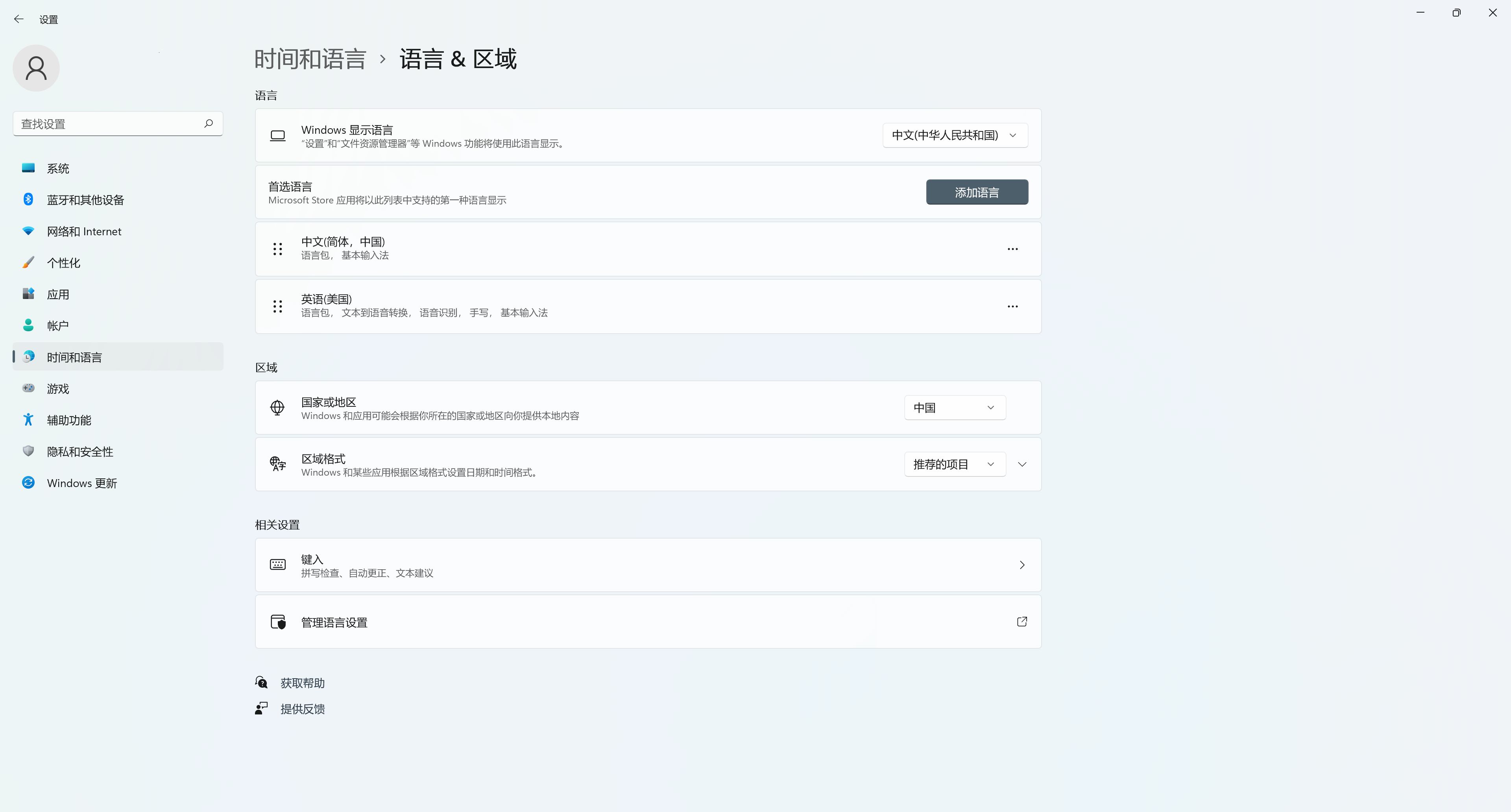
Пожалуйста, установите для них один и тот же язык.
Затем вставьте в свою программу "setlocale(LC_ALL, "");" к вашей основной функции. Это универсальное правило: независимо от того, какую ОС вы используете, всякий раз, когда вы хотите использовать стандартную библиотеку для обработки наборов символов, отличных от ASCII, у вас должна быть эта строка кода. В противном случае локаль по умолчанию "C" и содержит только ASCII. Затем вы можете начать использовать std::wcout и функции C, такие как fputws.
Если вы искали портативное решение, которое, к сожалению, все еще не входит в стандарт C++20, я могу порекомендовать библиотеку nowide . Он поставляется либо отдельно, либо как часть наддува. Вы найдете там множество стандартных аналогов, потребляющих или испускающих кодировку utf-8. Да, с, не с (пока). Не стесняйтесь использовать утилиты char8_t-correiation для интерпретации
char8_ts как
chars, если они уже есть в вашей программе.
Запрошенный фрагмент кода будет выглядеть так:
#include <boost/nowide/iostream.hpp>
#include <char8_t-remediation.h>
int main()
{
using boost::nowide::cout;
cout << U8("¡Hola!") << std::endl;
}
Примечание. Помните о проблеме ориентации потоков . Краткая рекомендация в контексте моего ответа: используйте исключительно ненаправленные потоки для ввода / вывода и данных в кодировке utf-8 .
При тестировании VS2019 с консольным приложением UNICODE в Win10 были обнаружены следующие тесты на испанском и японском языках:
Если вы просто
использование: устанавливает правильную кодовую страницу на CP1252 при использовании испанского (мексиканского) языкового параметра Windows и хорошего вывода (шрифт консоли lucida). Однако вывод на японский язык (с использованием японского языка Windows) подавляется (что означает отсутствие вывода для этих символов, выводятся обычные латинские символы).
использование: '_setmode(_fileno(stdout), _O_U16TEXT);` вывод работает правильно для всех. Однако весь вывод является 16-битным, поэтому перенаправление в файл выводит 16-битные символы.
с использованием:
Шрифты: для азиатских символов используйте MS Mincho, для остальных можно использовать консоль Lucida.
Кодировка по умолчанию:
- Windows UTF-16.
- Linux UTF-8.
- MacOS UTF-8.
Мое решение Шаги, содержит нулевые символы \0 (избегать усеченных). Без использования функций в заголовке windows.h:
- Добавьте макросы для обнаружения платформы.
#if defined (_WIN32)
#define WINDOWSLIB 1
#elif defined (__ANDROID__) || defined(ANDROID)//Android
#define ANDROIDLIB 1
#elif defined (__APPLE__)//iOS, Mac OS
#define MACOSLIB 1
#elif defined (__LINUX__) || defined(__gnu_linux__) || defined(__linux__)//_Ubuntu - Fedora - Centos - RedHat
#define LINUXLIB 1
#endif
- Создание функций преобразования std:: w string в std:: string или наоборот.
#include <locale>
#include <iostream>
#include <string>
#ifdef WINDOWSLIB
#include <Windows.h>
#endif
using namespace std::literals::string_literals;
// Convert std::wstring to std::string
std::string WidestringToString(const std::wstring& wstr, const std::string& locale)
{
if (wstr.empty())
{
return std::string();
}
size_t pos;
size_t begin = 0;
std::string ret;
size_t size;
#ifdef WINDOWSLIB
_locale_t lc = _create_locale(LC_ALL, locale.c_str());
pos = wstr.find(static_cast<wchar_t>(0), begin);
while (pos != std::wstring::npos && begin < wstr.length())
{
std::wstring segment = std::wstring(&wstr[begin], pos - begin);
_wcstombs_s_l(&size, nullptr, 0, &segment[0], _TRUNCATE, lc);
std::string converted = std::string(size, 0);
_wcstombs_s_l(&size, &converted[0], size, &segment[0], _TRUNCATE, lc);
ret.append(converted);
begin = pos + 1;
pos = wstr.find(static_cast<wchar_t>(0), begin);
}
if (begin <= wstr.length()) {
std::wstring segment = std::wstring(&wstr[begin], wstr.length() - begin);
_wcstombs_s_l(&size, nullptr, 0, &segment[0], _TRUNCATE, lc);
std::string converted = std::string(size, 0);
_wcstombs_s_l(&size, &converted[0], size, &segment[0], _TRUNCATE, lc);
converted.resize(size - 1);
ret.append(converted);
}
_free_locale(lc);
#elif defined LINUXLIB
std::string currentLocale = setlocale(LC_ALL, nullptr);
setlocale(LC_ALL, locale.c_str());
pos = wstr.find(static_cast<wchar_t>(0), begin);
while (pos != std::wstring::npos && begin < wstr.length())
{
std::wstring segment = std::wstring(&wstr[begin], pos - begin);
size = wcstombs(nullptr, segment.c_str(), 0);
std::string converted = std::string(size, 0);
wcstombs(&converted[0], segment.c_str(), converted.size());
ret.append(converted);
ret.append({ 0 });
begin = pos + 1;
pos = wstr.find(static_cast<wchar_t>(0), begin);
}
if (begin <= wstr.length()) {
std::wstring segment = std::wstring(&wstr[begin], wstr.length() - begin);
size = wcstombs(nullptr, segment.c_str(), 0);
std::string converted = std::string(size, 0);
wcstombs(&converted[0], segment.c_str(), converted.size());
ret.append(converted);
}
setlocale(LC_ALL, currentLocale.c_str());
#elif defined MACOSLIB
#endif
return ret;
}
// Convert std::string to std::wstring
std::wstring StringToWideString(const std::string& str, const std::string& locale)
{
if (str.empty())
{
return std::wstring();
}
size_t pos;
size_t begin = 0;
std::wstring ret;
size_t size;
#ifdef WINDOWSLIB
_locale_t lc = _create_locale(LC_ALL, locale.c_str());
pos = str.find(static_cast<char>(0), begin);
while (pos != std::string::npos) {
std::string segment = std::string(&str[begin], pos - begin);
std::wstring converted = std::wstring(segment.size() + 1, 0);
_mbstowcs_s_l(&size, &converted[0], converted.size(), &segment[0], _TRUNCATE, lc);
converted.resize(size - 1);
ret.append(converted);
ret.append({ 0 });
begin = pos + 1;
pos = str.find(static_cast<char>(0), begin);
}
if (begin < str.length()) {
std::string segment = std::string(&str[begin], str.length() - begin);
std::wstring converted = std::wstring(segment.size() + 1, 0);
_mbstowcs_s_l(&size, &converted[0], converted.size(), &segment[0], _TRUNCATE, lc);
converted.resize(size - 1);
ret.append(converted);
}
_free_locale(lc);
#elif defined LINUXLIB
std::string currentLocale = setlocale(LC_ALL, nullptr);
setlocale(LC_ALL, locale.c_str());
pos = str.find(static_cast<char>(0), begin);
while (pos != std::string::npos) {
std::string segment = std::string(&str[begin], pos - begin);
std::wstring converted = std::wstring(segment.size(), 0);
size = mbstowcs(&converted[0], &segment[0], converted.size());
converted.resize(size);
ret.append(converted);
ret.append({ 0 });
begin = pos + 1;
pos = str.find(static_cast<char>(0), begin);
}
if (begin < str.length()) {
std::string segment = std::string(&str[begin], str.length() - begin);
std::wstring converted = std::wstring(segment.size(), 0);
size = mbstowcs(&converted[0], &segment[0], converted.size());
converted.resize(size);
ret.append(converted);
}
setlocale(LC_ALL, currentLocale.c_str());
#elif defined MACOSLIB
#endif
return ret;
}
- Распечатать std:: string. Проверьте суффикс RawString.
Код Linux. Напечатайте непосредственно std:: string, используя std:: cout.
Если у вас есть std:: wstring.
1. Преобразовать в std:: string.
2. Распечатайте с помощью std:: cout.
std::wstring x = L"\0\001日本ABC\0DE\0F\0G\0"s;
std::string result = WidestringToString(x, "en_US.UTF-8");
std::cout << "RESULT=" << result << std::endl;
std::cout << "RESULT_SIZE=" << result.size() << std::endl;
В Windows, если вам нужно распечатать Unicode. Нам нужно использовать WriteConsole для печати символов Юникода из std:: wstring или std:: string.
void WriteUnicodeLine(const std::string& s)
{
#ifdef WINDOWSLIB
WriteUnicode(s);
std::cout << std::endl;
#elif defined LINUXLIB
std::cout << s << std::endl;
#elif defined MACOSLIB
#endif
}
void WriteUnicode(const std::string& s)
{
#ifdef WINDOWSLIB
std::wstring unicode = Insane::String::Strings::StringToWideString(s);
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), unicode.c_str(), static_cast<DWORD>(unicode.length()), nullptr, nullptr);
#elif defined LINUXLIB
std::cout << s;
#elif defined MACOSLIB
#endif
}
void WriteUnicodeLineW(const std::wstring& ws)
{
#ifdef WINDOWSLIB
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), ws.c_str(), static_cast<DWORD>(ws.length()), nullptr, nullptr);
std::cout << std::endl;
#elif defined LINUXLIB
std::cout << String::Strings::WidestringToString(ws)<<std::endl;
#elif defined MACOSLIB
#endif
}
void WriteUnicodeW(const std::wstring& ws)
{
#ifdef WINDOWSLIB
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), ws.c_str(), static_cast<DWORD>(ws.length()), nullptr, nullptr);
#elif defined LINUXLIB
std::cout << String::Strings::WidestringToString(ws);
#elif defined MACOSLIB
#endif
}
Код Windows. Использование функции WriteLineUnicode или WriteUnicode. Тот же код может быть использован для Linux.
std::wstring x = L"\0\001日本ABC\0DE\0F\0G\0"s;
std::string result = WidestringToString(x, "en_US.UTF-8");
WriteLineUnicode(u8"RESULT" + result);
WriteLineUnicode(u8"RESULT_SIZE" + std::to_string(result.size()));
Наконец-то на Windows. Вам нужна мощная и полная поддержка символов юникода в консоли. Я рекомендую ConEmu и установить в качестве терминала по умолчанию в Windows.
Тест на Microsoft Visual Studio и Jetbrains Clion.
- Протестировано на Microsoft Visual Studio 2017 с VC++; станд = C++17. (Проект Windows)
- Протестировано на Microsoft Visual Studio 2017 с g++; станд = C++17. (Проект Linux)
- Проверено на Jetbrains Clion 2018.3 с g++; станд = C++17. (Linux Toolchain / Remote)
контроль качества
В. Почему вы не используете
<codecvt>функции заголовка и классы?
А. Устаревшие Удаленные или устаревшие функции невозможно построить на VC++, но нет проблем на g ++. Я предпочитаю 0 предупреждений и головных болей.Q. wstring в Windows является interchan.
А. Устаревшие Удаленные или устаревшие функции невозможно построить на VC++, но нет проблем на g ++. Я предпочитаю 0 предупреждений и головных болей.Q. std:: wstring является кроссплатформенным?
A. Нет. Std:: wstring использует элементы wchar_t. В Windows размер wchar_t составляет 2 байта, каждый символ хранится в единицах UTF-16, если символ больше, чем U+FFFF, символ представляется в двух единицах UTF-16 (2 элемента wchar_t), называемых суррогатными парами. В Linux размер wchar_t составляет 4 байта, каждый символ хранится в одном элементе wchar_t, без суррогатных пар. Проверьте стандартные типы данных в UNIX, Linux и Windows.Q. std:: string является кроссплатформенным?
А. Да. std:: string использует элементы char. Гарантируется, что тип char одинакового размера во всех компиляторах. Размер шрифта составляет 1 байт. Проверьте стандартные типы данных в UNIX, Linux и Windows.
Я не думаю, что есть простой ответ. Глядя на кодовые страницы консоли и функцию SetConsoleCP, кажется, что вам потребуется настроить соответствующую кодовую страницу для набора символов, который вы собираетесь вывести.
Во-первых, извините, у меня, вероятно, нет необходимых шрифтов, поэтому я пока не могу это проверить.
Здесь что-то выглядит немного подозрительно
// the following is said to be working
SetConsoleOutputCP(CP_UTF8); // output is in UTF8
wchar_t s[] = L"èéøÞǽлљΣæča";
int bufferSize = WideCharToMultiByte(CP_UTF8, 0, s, -1, NULL, 0, NULL, NULL);
char* m = new char[bufferSize];
WideCharToMultiByte(CP_UTF8, 0, s, -1, m, bufferSize, NULL, NULL);
wprintf(L"%S", m); // <-- upper case %S in wprintf() is used for MultiByte/utf-8
// lower case %s in wprintf() is used for WideChar
printf("%s", m); // <-- does this work as well? try it to verify my assumption
в то время как
// the following is said to have problem
SetConsoleOutputCP(CP_UTF8);
utf8_locale = locale(old_locale,
new boost::program_options::detail::utf8_codecvt_facet());
wcout.imbue(utf8_locale);
wcout << L"¡Hola!" << endl; // <-- you are passing wide char.
// have you tried passing the multibyte equivalent by converting to utf8 first?
int bufferSize = WideCharToMultiByte(CP_UTF8, 0, s, -1, NULL, 0, NULL, NULL);
char* m = new char[bufferSize];
WideCharToMultiByte(CP_UTF8, 0, s, -1, m, bufferSize, NULL, NULL);
cout << m << endl;
как насчет
// without setting locale to UTF8, you pass WideChars
wcout << L"¡Hola!" << endl;
// set locale to UTF8 and use cout
SetConsoleOutputCP(CP_UTF8);
cout << utf8_encoded_by_converting_using_WideCharToMultiByte << endl;
Недавно я хотел транслировать Unicode из Python на консоль Windows, и вот минимум, что мне нужно сделать:
- Вы должны установить консольный шрифт на тот, который покрывает символы Unicode. Выбор не очень широк: Свойства консоли> Шрифт> Консоль Lucida
- Вы должны изменить текущую кодовую страницу консоли: запустить
chcp 65001в консоли или используйте соответствующий метод в коде C++ - запись в консоль с помощью WriteConsoleW
Посмотрите интересную статью о Java Unicode на консоли Windows
Кроме того, в Python вы не можете записать в sys.stdout по умолчанию в этом случае, вам нужно будет заменить его чем-нибудь, используя os.write(1, binarystring) или прямой вызов оболочки вокруг WriteConsoleW. Похоже, в C++ вам нужно будет сделать то же самое.
Есть несколько проблем с потоками mswcrt и io.
- Трюк _setmode(_fileno(stdout), _O_U16TEXT); работает только для MS VC++, а не MinGW-GCC. Более того, иногда это приводит к сбоям в зависимости от конфигурации Windows.
- SetConsoleCP (65001) для UTF-8. Может не работать во многих многобайтовых символьных сценариях, но это всегда нормально для UTF-16LE
- Вам необходимо восстановить кодовую страницу консоли предварительного просмотра при выходе из приложения.
Консоль Windows поддерживает UNICODE с функциями ReadConsole и WriteConsole в режиме UTF-16LE. Фоновый эффект - в этом случае трубопровод не будет работать. Т.е. myapp.exe >> ret.log приводит к 0-байтовому файлу ret.log. Если вы согласны с этим, попробуйте мою библиотеку следующим образом.
const char* umessage = "Hello!\nПривет!\nПривіт!\nΧαιρετίσματα!\nHelló!\nHallå!\n";
...
#include <console.hpp>
#include <ios>
...
std::ostream& cout = io::console::out_stream();
cout << umessage
<< 1234567890ull << '\n'
<< 123456.78e+09 << '\n'
<< 12356.789e+10L << '\n'
<< std::hex << 0xCAFEBABE
<< std::endl;
Библиотека автоматически преобразует ваш UTF-8 в UTF-16LE и запишет его в консоль с помощью WriteConsole. Как и есть ошибки и входные потоки. Еще одно преимущество библиотеки - цвета.
Ссылка на пример приложения: https://github.com/incoder1/IO/tree/master/examples/iostreams
Домашняя страница библиотеки: https://github.com/incoder1/IO
запуск консольного приложения из VS2017 под Win10 с региональными настройками Великобритании потребовал от меня:
- установите инструменты VS2017> Среда> Шрифты и цвета> Шрифт: например, 'Lucida'
- сохраните исходные файлы C++ с кодировкой «Unicode (UTF-8 с подписью) - Codepage 650001», чтобы вы могли вводить буквы L с акцентом на символы L «âéïôù» без предупреждений компилятора, но избегайте везде двухбайтовых символов
- скомпилировать с помощью свойств конфигурации> Общие> Набор символов> "Использовать многобайтовый .." и Свойства конфигурации> C / C++> Все параметры> Дополнительные параметры> флаг "/utf-8"
- #include <iostream>, <io.h> и <fcntl.h>
- выполнить непонятный '_setmode(_fileno(stdout), _O_WTEXT);' один раз при запуске приложения
- забудьте 'cout <<...;' и используйте только 'wcout << ...;'
Для заметок VS2015 на Win7 требовался SetConsoleOutputCP(65001); и позволял микшировать выходы через wcout и cout.
В моем случае я читаю файл UTF-8 и печатаю в
Console, Я нахожу
wifstreamработает очень хорошо, даже в отладчике Visual Studio правильно отображаются слова UTF-8 (я читаю традиционный китайский), из этого сообщения:
#include <sstream>
#include <fstream>
#include <codecvt>
std::wstring readFile(const char* filename)
{
std::wifstream wif(filename);
wif.imbue(std::locale(std::locale::empty(), new std::codecvt_utf8<wchar_t>));
std::wstringstream wss;
wss << wif.rdbuf();
return wss.str();
}
// usage
std::wstring wstr2;
wstr2 = readFile("C:\\yourUtf8File.txt");
wcout << wstr2;
Правильное отображение западноевропейских символов в консоли Windows
Короче:
- использование
chcpчтобы найти, какая кодовая страница работает для вас. В моем случае это былоchcp 28591для Западной Европы. - при желании сделать его по умолчанию:
REG ADD HKCU\Console /v CodePage /t REG_DWORD /d 28591
История открытия
У меня была похожая проблема с Java. Это просто косметика, так как включает в себя строки журнала, отправленные на консоль; но это все равно раздражает.
Вывод из нашего Java-приложения должен быть в формате UTF-8, и он правильно отображается в консоли eclipse. Но в консоли Windows, он просто показывает символы рисования ASCII: Inicializaci├│n а также art├¡culos вместо Inicialización а также artículos,
Я наткнулся на связанный вопрос и смешал некоторые ответы, чтобы найти решение, которое сработало для меня. Решением является изменение кодовой страницы, используемой консолью, и использование шрифта, поддерживающего UNICODE (например, consolas или же lucida console). Шрифт, который вы можете выбрать в системном меню Windows cosole:
- Запустите консоль любым из
Win + Rзатем введитеcmdи ударилReturnключ.- Ударь
Winключ и типcmdс последующимreturnключ.
- Откройте системное меню любым из
- щелкните значок в верхнем левом углу
- Ударь
Alt + Spaceкомбинация клавиш
- затем выберите "По умолчанию", чтобы изменить поведение всех последующих окон консоли
- нажмите вкладку "Шрифт"
- Выбрать
Consolasили жеLucida console - Нажмите
OK
Что касается кодовой страницы, для разового случая вы можете сделать это с помощью команды chcp а затем вы должны выяснить, какая кодовая страница подходит для вашего набора символов. Несколько ответов предлагали кодовую страницу UTF-8, то есть 65001, но эта кодовая страница не работала для моих испанских символов.
В другом ответе предлагался пакетный скрипт для интерактивного выбора нужной кодовой страницы из списка. Там я нашел кодовую страницу для ISO-8859-1, которая мне была нужна: 28591. Чтобы вы могли выполнить
chcp 28591
перед каждым исполнением вашей заявки. Вы можете проверить, какая кодовая страница подходит вам на странице идентификаторов кодовых страниц MSDN.
Еще один ответ показал, как сохранить выбранную кодовую страницу как заданную по умолчанию для консоли Windows. Это включает в себя изменение реестра, так что считайте себя предупрежденным о том, что с помощью этого решения вы можете сделать кирпич своей машиной.
REG ADD HKCU\Console /v CodePage /t REG_DWORD /d 28591
Это создает CodePage значение с 28591 данные внутри раздела реестра HKCU\Console. И это сработало для меня.
Обратите внимание, что HKCU ("HKEY_CURRENT_USER") только для текущего пользователя. Если вы хотите изменить его для всех пользователей на этом компьютере, вам необходимо использовать regedit утилита и найти / создать соответствующий Console ключ (вероятно, вам придется создать Console ключ внутри HKEY_USERS\.DEFAULT)
У меня была похожая проблема: вывод Unicode на консоль с использованием C++, в Windows содержится гем, который вам нужно сделать chcp 65001 в консоли перед запуском вашей программы.
Там может быть какой-то способ сделать это программно, но я не знаю, что это такое.