Расчет и экономия места в PostgreSQL
У меня есть таблица в pg так:
CREATE TABLE t (
a BIGSERIAL NOT NULL, -- 8 b
b SMALLINT, -- 2 b
c SMALLINT, -- 2 b
d REAL, -- 4 b
e REAL, -- 4 b
f REAL, -- 4 b
g INTEGER, -- 4 b
h REAL, -- 4 b
i REAL, -- 4 b
j SMALLINT, -- 2 b
k INTEGER, -- 4 b
l INTEGER, -- 4 b
m REAL, -- 4 b
CONSTRAINT a_pkey PRIMARY KEY (a)
);
Выше добавлено до 50 байтов на строку. Мой опыт показывает, что мне нужно еще 40–50% для системных издержек, даже без каких-либо созданных пользователем индексов, описанных выше. Итак, около 75 байт на строку. У меня будет много-много строк в таблице, потенциально больше 145 миллиардов строк, поэтому таблица будет загружать 13-14 терабайт. Какие уловки, если таковые имеются, я мог бы использовать для сжатия этой таблицы? Мои возможные идеи ниже...
Преобразовать real значения для integer, Если они могут храниться как smallintэто экономия 2 байтов на поле.
Преобразуйте столбцы b.. m в массив. Мне не нужно искать по этим столбцам, но мне нужно иметь возможность возвращать значение одного столбца за раз. Итак, если мне нужен столбец g, я мог бы сделать что-то вроде
SELECT a, arr[5] FROM t;
Буду ли я экономить место с параметром массива? Будет ли штраф за скорость?
Есть другие идеи?
5 ответов
Я ничего не вижу (и что-то теряю) для хранения нескольких числовых полей в массиве.
Размер каждого числового типа четко задокументирован, вы должны просто использовать наименьший размерный тип, совместимый с вашим желаемым разрешением по диапазону; и это все, что вы можете сделать.
Я не думаю (но я не уверен), существует ли какое-либо требование выравнивания байтов для столбцов вдоль строки, в этом случае изменение порядка столбцов может изменить используемое пространство - но я так не думаю.
Кстати, в каждом ряду есть фиксированные накладные расходы, около 23 байтов.
"Колонна тетриса"
На самом деле, вы можете что- то сделать, но это требует более глубокого понимания. Ключевое слово - выравнивание выравнивания. Каждый тип данных имеет определенные требования к выравниванию.
Вы можете минимизировать пространство, потерянное для заполнения между столбцами, упорядочив их. Следующий (экстремальный) пример будет тратить много физического дискового пространства:
CREATE TABLE t (
e int2 -- 6 bytes of padding after int2
, a int8
, f int2 -- 6 bytes of padding after int2
, b int8
, g int2 -- 6 bytes of padding after int2
, c int8
, h int2 -- 6 bytes of padding after int2
, d int8)
Чтобы сохранить 24 байта на строку, используйте вместо этого:
CREATE TABLE t (
a int8
, b int8
, c int8
, d int8
, e int2
, f int2
, g int2
, h int2) -- 4 int2 occupy 8 byte (MAXALIGN), no padding at the end
Как правило, если сначала поставить 8-байтовые столбцы, а затем 4-байтовые, 2-байтовые и 1-байтовые столбцы, то вы не ошибетесь. text или же boolean не имеют ограничений на выравнивание, как у некоторых других типов. Некоторые типы могут быть сжатыми или "поджаренными" (сохраненными вне строки) или и тем, и другим.
Как правило, вы можете сохранить пару байтов на строку, в лучшем случае играя "столбец тетрис". В большинстве случаев это не нужно. Но с миллиардами строк это может означать пару гигабайт легко.
Вы можете проверить фактический размер столбца / строки с помощью функции pg_column_size(),
Имейте в виду, что некоторые типы данных могут использовать больше места в оперативной памяти, чем на диске (сжатый формат). Таким образом, вы можете получить более высокие результаты для констант (формат RAM), чем для столбцов таблицы (формат диска), когда тестируете одно и то же значение (или строку значений и строку таблицы) с pg_column_size(),
Накладные расходы на кортеж (ряд)
4 байта в строке для указателя элемента - без учета вышеуказанных соображений.
И как минимум 24 байта (23 + заполнение) для заголовка кортежа. Руководство по разметке страницы базы данных:
Существует заголовок фиксированного размера (занимающий 23 байта на большинстве машин), за которым следует необязательное нулевое растровое изображение, необязательное поле идентификатора объекта и пользовательские данные.
Для заполнения между заголовком и пользовательскими данными вам нужно знать MAXALIGN на вашем сервере - обычно 8 байтов в 64-битной ОС (или 4 байта в 32-битной ОС). Если вы не уверены, проверьте pg_controldata,
Запустите следующее в вашем двоичном каталоге Postgres, чтобы получить окончательный ответ:
./pg_controldata /path/to/my/dbcluster
Фактические данные пользователя (столбцы строки) начинаются со смещения, обозначенного
t_hoff, который всегда должен быть кратнымMAXALIGNрасстояние до платформы.
Таким образом, вы обычно получаете оптимальный объем хранения, упаковывая данные в кратные 8 байт.
В приведенном вами примере нечего получить. Это уже плотно упаковано. 2 байта заполнения после последнего int2 4 байта в конце. Вы можете объединить заполнение до 6 байтов в конце, что ничего не изменит.
Накладные расходы на страницу данных
Размер страницы данных обычно составляет 8 КБ. Некоторые издержки / раздувание на этом уровне тоже: остатки недостаточно велики для размещения другого кортежа и, что более важно, мертвые строки или процент, зарезервированный с помощью FILLFACTOR установка.
Есть несколько других факторов, влияющих на размер диска:
- Сколько записей я могу хранить в 5 МБ PostgreSQL на Heroku?
- Разве использование NULL в PostgreSQL все еще не использует растровое изображение NULL в заголовке?
- Настройка PostgreSQL для производительности чтения
Типы массивов?
С массивом, который вы оценивали, вы добавили бы 24 байта для типа массива. Плюс, элементы массива занимают пространство как обычно. Нечего там приобретать.
Из этой замечательной документации: https://www.2ndquadrant.com/en/blog/on-rocks-and-sand/
Для таблицы, которая у вас уже есть или, возможно, той, которую вы создаете в разработке, называется my_table, этот запрос даст оптимальный порядок слева направо.
SELECT a.attname, t.typname, t.typalign, t.typlen
FROM pg_class c
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE c.relname = 'my_table'
AND a.attnum >= 0
ORDER BY t.typlen DESC
Вот классный инструмент, касающийся предложения по переупорядочению столбцов Эрвина: https://github.com/NikolayS/postgres_dba .
Для этого у него есть точная команда -- p1:
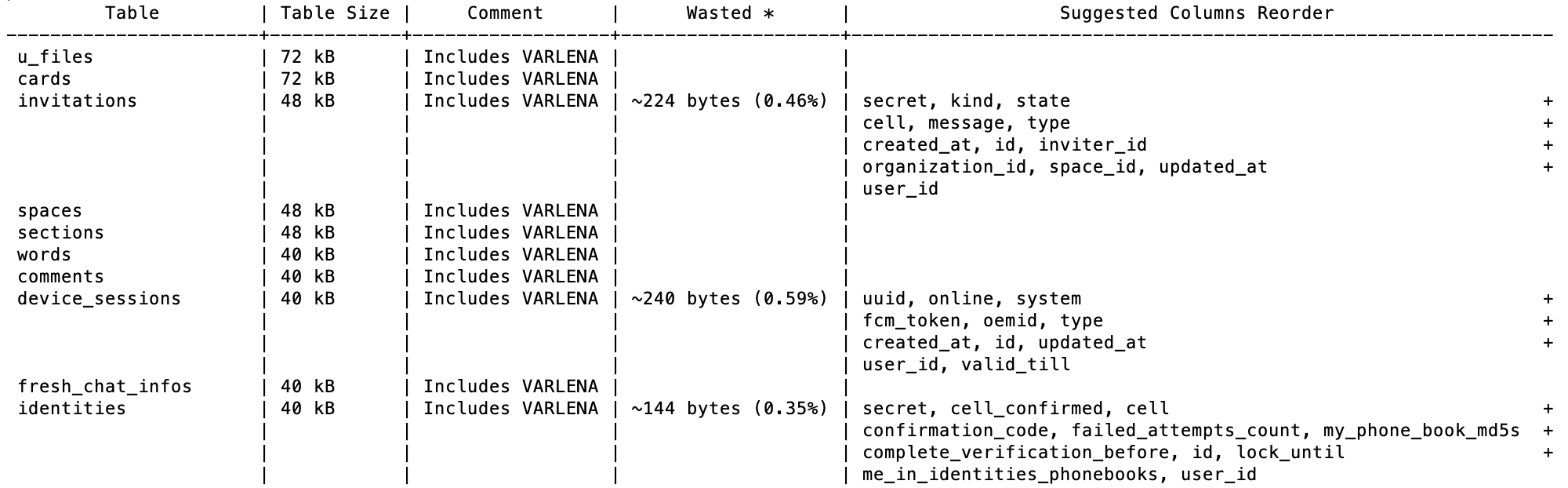
Затем он автоматически показывает реальный потенциал изменения порядка столбцов во всех ваших таблицах:
Прочитав ответы Эрвина Брандштеттера и jboxxx , а также документ, на который ссылается последний, я немного улучшил запрос, чтобы сделать его более универсальным:
-- https://www.postgresql.org/docs/current/catalog-pg-type.html
CREATE OR REPLACE VIEW tabletetris
AS SELECT n.nspname, c.relname,
a.attname, t.typname, t.typstorage, t.typalign, t.typlen
FROM pg_class c
JOIN pg_namespace n ON (n.oid = c.relnamespace)
JOIN pg_attribute a ON (a.attrelid = c.oid)
JOIN pg_type t ON (t.oid = a.atttypid)
WHERE a.attnum >= 0
ORDER BY n.nspname ASC, c.relname ASC,
t.typlen DESC, t.typalign DESC, a.attnum ASC;
Используйте так:
SELECT * FROM tabletetris WHERE relname='mytablename';
Но вы можете добавить фильтр наnspname(схема, в которой находится таблица).
Я также добавил тип хранилища, что является полезной информацией для выяснения того, какой из-1те, которые нужно встроить и/или упорядочить, и сохранить относительный порядок существующих столбцов с тем же ключом сортировки.