Время рандомизированного алгоритма
У меня есть рандомизированный алгоритм рекурсивного возврата для генерации головоломок судоку (см. Здесь). В среднем он работает достаточно быстро, но в худшем случае время выполнения неприемлемо медленно. Вот гистограмма времени выполнения в миллисекундах для 100 испытаний ("Больше" составляет около 200000 мс!):
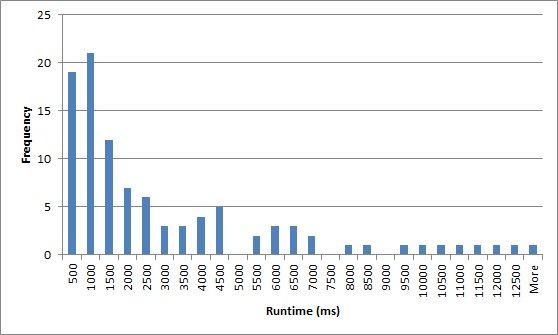
Я хотел бы улучшить алгоритм, просто рассчитав его по истечении t мс, и перезапустив с новым случайным начальным числом. Чтобы это не повторялось бесконечно, я бы либо останавливался после n попыток, либо увеличивал t после каждой неудачной попытки. Если t намного больше, чем медиана, есть хороший шанс получить более быстрый бег при следующей попытке.
Вопросы:
- Как я могу настроить время ожидания t для разных процессоров? Существует ли быстрый и надежный способ оценки производительности процессора перед каждым запуском? Или я должен адаптироваться к процессору за несколько прогонов, например, используя среднее время выполнения всех предыдущих прогонов? Я запускаю это на Android, если это актуально.
- Есть ли лучшая стратегия, чтобы полностью избежать длинного хвоста в распределении времени выполнения?
2 ответа
Поскольку ваш алгоритм рекурсивный, почему бы не установить максимальную глубину рекурсии? Если конкретное случайное семя приводит к глубине рекурсии, которая, как вы эмпирически установили, достаточно высока, чтобы вы могли попасть в длинный хвост, прервите ее в этой точке.
С точки зрения визуальной аппроксимации, после 4500 мс вы не получите значительную отдачу от своих инвестиций для данного семени. Повторите этот тест, также отслеживая глубину рекурсии, и посмотрите, что это за число. Я бы запустил более 100 сэмплов.
Это решение не зависит от скорости процессора.
Да, это называется доверительным интервалом. Запустив алгоритм несколько раз в предварительной обработке (или на лету), вы можете с уверенностью определить x% (где
xявляется параметром) каков интервал, в котором лежит медиана времени бега.
Вы можете уменьшить размер интервала, уменьшивxили увеличение количества раз выполнения алгоритма.
Конечно, если вы действительно не можете запустить сам алгоритм, вы можете попробовать сравнить его на некотором компьютере и найти доверительный интервал (пусть это будетI), и создайте некоторую функциюf(I,s)что с учетом синхронизации другого алгоритма (его синхронизации) на другой машине (M), предсказывает, каким должен быть интервал для машины М.
обнаружениеsделается аналогичным образом - с использованием доверительного интервала.Ваш подход выглядит хорошо, я бы, наверное, сделал то же самое - сначала я настрою небольшой фактор и увеличиваю его после каждой неудачной попытки. Обратите внимание, что это как-то похоже на управление перегрузкой в протоколе TCP (из области сетей) для определения допустимой скорости передачи пакетов по сети.