Как читать данные в формате UTF-8 в R?
Моя система:win7+R-3.0.2.
> Sys.getlocale()
[1] "LC_COLLATE=Chinese (Simplified)_People's Republic of China.936;LC_CTYPE=Chinese
(Simplified)_People's Republic of China.936;LC_MONETARY=Chinese (Simplified)_People's
republic of China.936;LC_NUMERIC=C;LC_TIME=Chinese (Simplified)_People's Republic of China.936"
В Microsoft Notepad сохранено два файла с одинаковым содержимым: один сохранен в формате ANSI, другой - в формате UTF8. Данные являются именем смерти в M370 Malaysia Airlines . Или вы можете создать файл таким образом.
1) скопируйте данные в блокнот Microsoft.
乘客姓名,性别,出生日期
HuangTianhui,男,1948/05/28
姜翠云,女,1952/03/27
李红晶,女,1994/12/09
2) сохранить его как test.ansi в формате ansi в блокноте.
3) сохранить его как test.utf8 в формате utf-8 в блокноте.
read.table("test.ansi",sep=",",header=TRUE) #can work fine
read.table("test.utf8",sep=",",header=TRUE) #can't work
Затем я устанавливаю кодировку в utf-8.
options(encoding="utf-8")
read.table("test.utf8",sep=",",header=TRUE,encoding="utf-8")
In read.table("test.utf8", sep = ",",header=TRUE,encoding = "utf-8") :
invalid input found on input connection 'test.utf8'
Как я могу прочитать файл данных (test.utf8)?
В питоне это так просто
rfile=open("g:\\test.utf8","r",encoding="utf-8").read()
rfile
'\ufeff乘客姓名,性别,出生日期\n\nHuangTianhui,男,1948/05/28\n\n姜翠云,女,1952/03
/27\n\n李红晶,女,1994/12/09'
rfile.replace("\n\n","\n").replace("\ufeff","").splitlines()
['乘客姓名,性别,出生日期', 'HuangTianhui,男,1948/05/28', '姜翠云,女,1952/03/27',
'李红晶,女,1994/12/09']
Python может сделать такую работу лучше, чем R.
Я делаю, как говорит Сатиш, проблема немного решена, все еще остается.
Я обнаружил, что когда данные находятся в data.frame, они не могут отображаться правильно,
когда данные являются столбцом data.frame, они могут отображаться правильно,
Как ни странно, когда данные представляют собой строку data.frame, они не могут отображаться правильно.


2 ответа
ОС: Windows-7 (64-разрядная)
Версия R:
package_version(R.version)
[1] ‘3.0.2’
Измените локаль с "китайского" на "английский_Соединения.1252"
Sys.setlocale(category="LC_ALL", locale = "English_United States.1252")
Sys.getlocale(category="LC_ALL")
[1] "LC_COLLATE=English_United States.1252;LC_CTYPE=English_United States.1252;LC_MONETARY=English_United States.1252;LC_NUMERIC=C;LC_TIME=English_United States.1252"
Читать в данных с китайской кодировкой
df_ch <- read.table("test.utf8",
sep=",",
header=FALSE,
encoding="chinese",
stringsAsFactors=FALSE
)
Считать данные в кодировке UTF-8
df_utf8 <- read.table("test.utf8",
sep=",",
header=FALSE,
encoding="UTF-8",
stringsAsFactors=FALSE
)
В RStudio версии 0.98.501
df_ch$V1[1]
[1] "乘客姓å"
df_utf8$V1[1]
[2] "乘客姓名"
df_utf8$V1
[1] "乘客姓名" "HuangTianhui" "姜翠云" "李红晶" "LuiChing" "宋飞飞"
[7] "唐旭东" "YangJiabao" "买买提江·阿布拉" "安文兰" "鲍媛华" "边亮京"
[13] "边茂勤" "曹蕊" "车俊章" "陈长军" "陈建设" "陈昀"
[19] "戴淑玲" "丁立军" "丁莹" "丁颖" "董国伟" "杜文忠"
[25] "冯栋" "冯纪新" "付宝峰" "甘福祥" "甘涛" "高歌"
[31] "管文杰" "韩静" "侯爱琴" "侯波" "胡偲婠(婴儿)" "胡效宁"
Отображение данных Unicode для строки из фрейма данных
df_utf8[1,]
V1 V2 V3
1 <U+FEFF><U+4E58><U+5BA2><U+59D3><U+540D> <U+6027><U+522B> <U+51FA><U+751F><U+65E5><U+671F>
Отображение китайских данных для строки из фрейма данных
as.character(df_utf8[1,])
[1] "乘客姓名" "性别" "出生日期"
as.character(df_utf8[2,])
[1] "HuangTianhui" "男" "1948/05/28"
Отображение нескольких столбцов данных с международными символами может быть выполнено путем преобразования фрейма данных в список и принудительного преобразования данных в символьный формат.
df_utf8_ch <- lapply(df_utf8, as.character)
df_utf8_ch
$ V1 1 "乘客 姓名" "HuangTianhui" "姜翠云" "李红晶" "LuiChing" "宋飞飞"
7 "唐旭东" "Ян Цзябао" "买买提 江 · 阿布拉" "安文兰" "鲍媛华" "边 亮 京"
[13] "边 茂 勤" "曹 蕊" "车 俊 章" "陈长军" "陈 建设" "陈 昀"
[19] "戴淑玲" "丁立军" "丁 莹" "丁颖" "董国伟" "杜文忠"
[25] "冯 栋" "冯 纪 新" "付宝峰" "甘福祥" "甘 涛" "高歌"
[31] "管 文杰" "韩 静" "侯爱琴" "侯波" "胡 偲 婠 (婴儿)" "胡 效 宁"
[37] "黄毅" "姜学仁" "姜 颖" "焦 微微" "焦 文学" "鞠 坤"
[43] "康旭" "黎明 中" "李国辉" "李洁" "李 乐" "李文博"
[49] "李燕" "李宇辰" "李志 锦" "李志欣" "李智" "栗 延 林"
[55] "梁 路 阳" "梁旭阳" "林安南" "林明峰" "刘凤英" "刘金鹏"
[61] "刘强" "刘如生" "刘顺 超" "柳忠福" "楼 宝 棠" "卢 先 初"
[67] "鹿 建华" "罗伟" "马骏" "马文芝" "毛 土 贵" "么 立 飞"
[73] "蒙 高 生" "孟 兵" "孟凡 余" "欧阳 欣" "石贤文" "宋春玲"
[79] "宋 坤" "苏 强国" "汤 雪竹" "田军伟" "田清君" "汪 厚 彬"
[85] "王春勇" "王纯华" "王丹" "王海涛" "王利军" "王 林诗"
[91] "王 墨 恒 (婴儿)" "王守宪" "王淑敏" "王献军" "王永刚"
$ V2 1 "性别" "男" "女" "女" "女" "男" "男" "女" "男" "女" "女" "男" "女" "女" "女" "男"
[17] "男" "女" "女" "男" "女" "女" "男" "男" "男" "男" "男" "男" "男" "女" "男" "女"
[33] "女" "男" "女" "男" "女" "男" "女" "女" "男" "男" "男" "男" "男" "女" "男" "女"
[49] "女" "男" "男" "男" "男" "男" "男" "男" "男" "男" "女" "男" "男" "男" "男" "男"
[65] "男" "男" "男" "男" "男" "女" "男" "男" "男" "男" "男" "女" "男"
$ V3 1 "出生 日期" "1948/05/28" "1952/03/27" "1994/12/09" "1969/08/02" "1982/03/01" "1983/08/03" " 1988/08/25 "[9]" 1979/07/10 "" 1949/10/20 "" 1951/10/21 "" 1987/06/06 "" 1947/07/19 "" 1982/02/19 "" 1946/03/20 "" 1979/06/06 "[17]" 1956/03/07 "" 1957/08/11 "" 1956/12/07 "" 1971/04/06 "" 1952/04 / 25 "" 1986/10/24 "" 1966/10/26 "" 1964/06/07 "[25]" 1993/03/09 "" 1944/01/06 "" 1986/12/06 "" 1965 / 11/21 "" 1970/01/29 "" 1987/11/16 "" 1979/10/03 "" 1961/05/28 "[33]" 1969/06/24 "" 1979/05/15 " "2011/02/25" "1980/01/01" "1984/06/18" "有待 确认" "1987/04/13" "1983/05/09" [41] "1956/12/17" " 1982/11/07 "" 1980/08/09 "" 1945/12/19 "" 1958/05/18 "" 1987/02/06 "" 1982/12/03 "" 1985/07/16 "[49 ] "1983/07/19" "1987/11/06" "1984/04/14" "1979/05/22" "1973/05/05" "1985/10/26" "1954/03/26" "1984/11/12" [57] "1987/27/27" "1980/05/25" "1949/05/10" "1981/12/26" "1974/08/13" "1938/01/ 22 "" 1968/02/29 "" 1942/05/22 "[65]" 1935/04/21 "" 1981/10/14 "" 1957/03/28 "" 1985/08/20 "" 1981 / 25/25 "" 1957/08/01 "" 1942/08/02 "" 1983/06/15 "[73]" 1950/01/0 1 "" 1974/04/26 "" 1944/08/23 "" 1976/10/12 "" 1988/01/18 "" 1954/04/06 "
View(df_ch)

View(df_utf8)
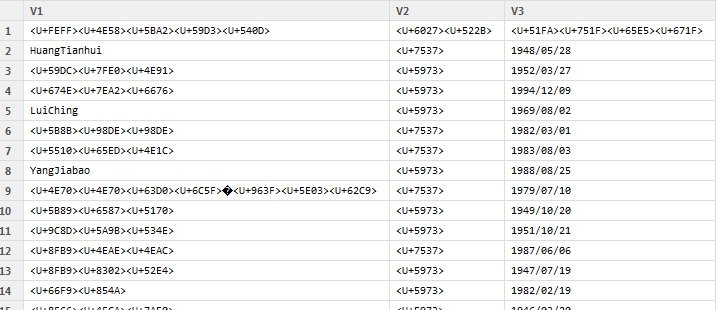
В RGui (64-битная версия)

Просмотр (df_ch)

Просмотр (df_utf8)
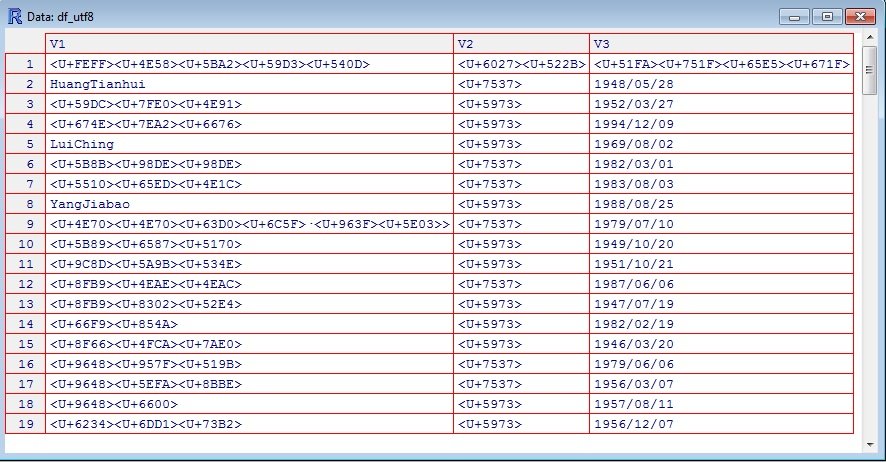
Хорошо, что у вас есть все данные в формате utf8, которые можно использовать для дальнейшего анализа данных.
Как только ваш анализ завершен, вы можете изменить локаль обратно на "китайский"
Sys.setlocale(category="LC_ALL", locale = "chinese")
Sys.getlocale(category="LC_ALL")
[1] "LC_COLLATE=Chinese (Simplified)_People's Republic of China.936;LC_CTYPE=Chinese (Simplified)_People's Republic of China.936;LC_MONETARY=Chinese (Simplified)_People's Republic of China.936;LC_NUMERIC=C;LC_TIME=Chinese (Simplified)_People's Republic of China.936"
Некоторые функции, которые вам, возможно, понадобится изучить для преобразования между кодировками символьных строк.
НТН
Попробуйте другой аргумент для read.table: fileEncoding:
read.table("test.utf8", sep = "," , header=TRUE, fileEncoding = "UTF-8")