Внутренняя работа Spark - Связь / Синхронизация
Я совершенно новичок в Spark, но уже имею опыт программирования в модели BSP. В модели BSP (например, Apache Hama) мы должны самостоятельно обрабатывать все коммуникации и синхронизацию узлов. Что хорошо с одной стороны, потому что у нас есть более точный контроль над тем, чего мы хотим достичь, но с другой стороны, это добавляет больше сложности.
Spark, с другой стороны, берет на себя все управление и обрабатывает все самостоятельно (что здорово), но я не понимаю, как это работает внутри, особенно в тех случаях, когда у нас много данных и сообщений, передаваемых между узлами. Позвольте мне привести пример
zb = sc.broadcast(z)
r_i = x_i.map(x => Math.pow(norm(x - zb.value), 2))
r_i.checkpoint()
u_i = u_i.zip(x_i).map(ux => ux._1 + ux._2 - zb.value)
u_i.checkpoint()
x_i = f.prox(u_i.map(ui => {zb.value - ui}), rho)
x_i.checkpoint()
x = x_i.reduce(_+_) / f.numSplits.toDouble
u = u_i.reduce(_+_) / f.numSplits.toDouble
z = g.prox(x+u, f.numSplits*rho)
r = Math.sqrt(r_i.reduce(_+_))
Это метод, взятый отсюда, который выполняется в цикле (скажем, 200 раз). x_i содержит наши данные (скажем, 100 000 записей).
В программе стиля BSP, если нам нужно обработать эту операцию карты, мы разделим эти данные и распределим их по нескольким узлам. Каждый узел обработает часть данных (операцияотображения) и вернет результат мастеру (после синхронизации барьера). Так как мастер-узел хочет обработать каждый возвращенный отдельный результат (централизованный мастер - см. Рисунок ниже), мы отправляем результат каждой записи в мастер (сокращение оператора в искре). Таким образом, (только) мастер получает 100 000 сообщений после каждой итерации. Он обрабатывает эти данные и снова отправляет новые значения ведомым, которые снова начинают обработку для следующей итерации.
Теперь, так как Spark получает контроль от пользователя и выполняет все внутренне, я не могу понять, как Spark собирает все данные после операций с картой (асинхронная передача сообщений? Я слышал, что у него есть передача p2p-сообщений? Как насчет синхронизации между задачами карты? Если это происходит синхронизация, тогда правильно ли говорить, что Spark на самом деле является моделью BSP?). Затем, чтобы применить функцию сокращения, собирает ли она все данные на центральном компьютере (если да, получает ли она 100 000 сообщений на одном компьютере?) Или распределяет ее распределенным образом (если да, то как это может быть выполнила?)
На следующем рисунке показана моя функция уменьшения на мастере. x_i ^ k-1 представляет собой i-е значение, вычисленное (в предыдущей итерации) относительно ввода данных x_i моего ввода. x_i ^ k представляет значение x_i, вычисленное в текущей итерации. Понятно, что это уравнение требует сбора результатов.
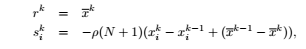
Я на самом деле хочу сравнить оба стиля распределенного программирования, чтобы понять, когда использовать Spark, а когда переходить на BSP. Кроме того, я много смотрел в интернете, все, что я нахожу, это как работает карта / уменьшение, но ничего полезного не было в реальной связи / синхронизации. Любой полезный материал будет полезен.