MalformedByteSequenceException, анализирующий RSS-канал с ROME
Я получаю исключение MalformedByteSequenceException, работающее с приложением JSF, которое использует Римский Rss-синтаксический анализ Lib:
[2017-08-31T15:54:01.241+0200] [glassfish 5.0] [SEVERE] [] [] [tid: _ThreadID=101 _ThreadName=Thread-9] [timeMillis: 1504187641241] [levelValue: 1000] [[
com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: Ungültiges Byte 1 von 1-Byte-UTF-8-Sequenz.
at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.invalidByte(UTF8Reader.java:701)
at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.read(UTF8Reader.java:567)
at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.load(XMLEntityScanner.java:1793)
at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.skipChar(XMLEntityScanner.java:1463)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(XMLDocumentFragmentScannerImpl.java:2824)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:606)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:510)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:848)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:777)
at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:141)
at com.sun.org.apache.xerces.internal.parsers.DOMParser.parse(DOMParser.java:243)
at com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderImpl.parse(DocumentBuilderImpl.java:339)
at javax.xml.parsers.DocumentBuilder.parse(DocumentBuilder.java:121)
at main.java.tools.RssAggregator.searchAggregatedFeeds(RssAggregator.java:119)
at main.java.jobs.ApplicationRunnable.lambda$execute$0(ApplicationRunnable.java:45)
at java.lang.Iterable.forEach(Iterable.java:75)
at main.java.jobs.ApplicationRunnable.execute(ApplicationRunnable.java:43)
at org.quartz.core.JobRunShell.run(JobRunShell.java:213)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:557)
]]
Ошибка выдается в строке RssAggregator.searchAggregatedFeeds() 119:
public List<Feed> searchAggregatedFeeds(String keyword) {
keyword = keyword.toLowerCase();
List<Feed> results = new LinkedList<>();
Document document = null;
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
//document = builder.parse(IOUtils.toInputStream(this.aggregatedRssString);
InputStream stream = new ByteArrayInputStream(this.aggregatedRssString.getBytes());
document = builder.parse(stream); //TODO HERE We have the Problem
stream.close();
//Normalize the XML Structure; It's just too important !!
document.getDocumentElement().normalize();
} catch (ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
//Here comes the root node
if (document != null) {
//Element root = document.getDocumentElement();
//Get all
NodeList nList = document.getElementsByTagName("item");
for (int i = 0; i < nList.getLength(); i++) {
Node node = nList.item(i);
Element ele = (Element) node;
Feed feed = new Feed();
feed.setDate(ele.getElementsByTagName("dc:date").item(0).getTextContent());
feed.setDescription(ele.getElementsByTagName("description").item(0).getTextContent());
feed.setLink(ele.getElementsByTagName("link").item(0).getTextContent());
feed.setSubject(ele.getElementsByTagName("title").item(0).getTextContent());
feed.setId(getIdCounter()); //set the id. This increments also
/* now the searching ... */
if (feed.getSubject().toLowerCase().contains(keyword) || feed.getDescription().toLowerCase().contains(keyword))
results.add(feed);
}
}
return results;
}
Я не могу понять, что должно быть не так с линией document = builder.parse(stream); //TODO HERE We have the Problem?
Что меня поражает, так это то, что при тестировании с помощью junit-теста все идет хорошо:
@Test
public void searchTest() throws Exception {
List<Feed> results = rssAggregator.searchAggregatedFeeds("a");
System.out.println("Hits: " + results.size());
List<Feed> results2 = rssAggregator.searchAggregatedFeeds("z");
System.out.println("Hits: " + results2.size());
List<Feed> results3 = rssAggregator.searchAggregatedFeeds("x");
System.out.println("Hits: " + results3.size());
}
в результате, как и ожидалось: 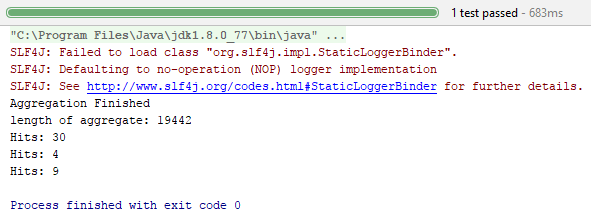
... в то время как вызов из циклического задания не
List<Feed> allResults = new LinkedList<>();
/* for each WORD search the aggregatedfeed for matches and add them to allResults */
configBean.words.forEach(w -> {
System.out.println("current searched for Word: " + w);
List<Feed> wResults = aggregator.searchAggregatedFeeds(w); // :(
allResults.addAll(wResults);
});
Вопрос: почему работает junit-тест, а вызов из приложения - нет? Агрегированные каналы точно такие же.
1 ответ
Ваши rss данные в кодировке UTF-8? Вызов версии без параметров String.getBytes() будет использовать кодировку платформы по умолчанию, и это может быть не UTF-8. Вот почему ваш тест может работать на Linux, но не на Windows. Пытаться String.getBytes(Charset charset) вместо.