Hadoop namenode метаданные
Я немного смущен архитектурой Hadoop.
Какие метаданные файла хранятся в Hadoop Namenode? В вики Hadoop говорится, что Namenode хранит все пространство имен системы. Хранится ли в Namenode информация, такая как время последнего изменения, время создания, размер файла, владелец, разрешения и т. Д.?
Хранит ли датоде какую-либо информацию метаданных?
Существует только один Namenode, могут ли данные метаданных превышать лимит сервера?
Если пользователь хочет загрузить файл из Hadoop, должен ли он загрузить его из Namenode? Я обнаружил нижеприведенную фотографию архитектуры, которая показывает, что клиент может напрямую записывать данные в датодан? Это правда?
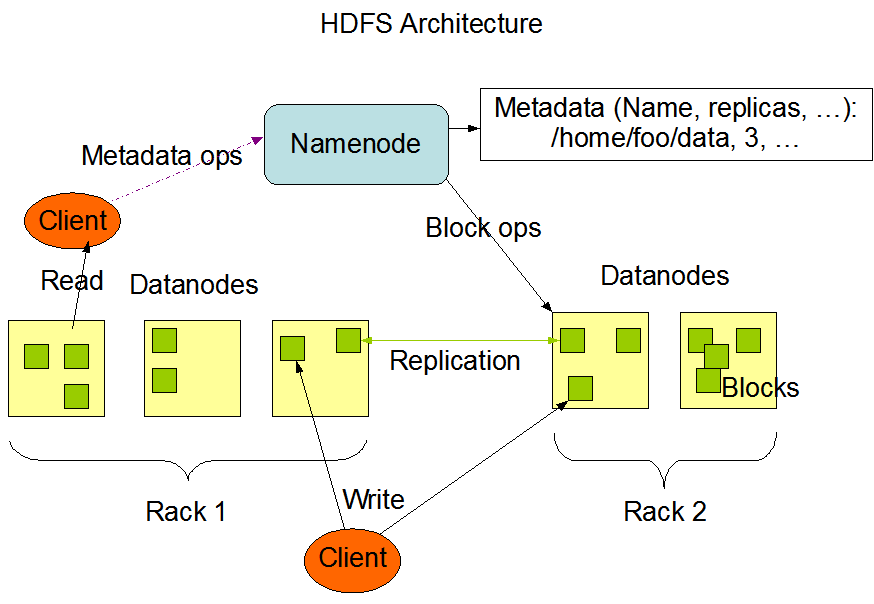
Спасибо!!!!!!!
6 ответов
Я думаю, что следующее объяснение может помочь вам лучше понять архитектуру HDFS. Вы можете считать узел Name похожим на FAT (таблица размещения файлов) + данные каталога и узлы данных как устройства с немым блоком. Если вы хотите прочитать файл из обычной файловой системы, вы должны перейти в каталог, затем перейти к FAT, получить расположение всех соответствующих блоков и прочитать их. То же самое происходит с HDFS. Когда вы хотите прочитать файл, вы идете в Namenode, получите список блоков, которые есть у данного файла. Эта информация о блоках будет содержать список датоделей, где эта информация находится. После этого вы идете к датоде и получаете от них соответствующие блоки.
- Fsimage на узле имени находится в двоичном формате. Используйте "Offline Image Viewer" для выгрузки fsimage в удобочитаемом формате. Выходные данные этого инструмента могут быть дополнительно проанализированы с помощью свиньи или другого инструмента, чтобы получить более значимые данные.
http://hadoop.apache.org/hdfs/docs/r0.21.0/hdfs_imageviewer.html
- да
- нет, кроме самих блоков
- да, если у вас много маленьких файлов
- нет, информация о файле находится в Namenode, сам файл находится в Datanodes (теоретически, datanode может быть на той же машине, и часто на меньших кластерах)
3) Когда файлы no.of настолько велики, один Namenode не сможет сохранить все метаданные. На самом деле это одно из ограничений HDFS . Вы можете проверить федерацию HDFS, которая направлена на решение этой проблемы, разбившись на разные пространства имен, обслуживаемые разными наменодами.
4)
Read process :
a) Client first gets the datanodes where the actual data is located from the namenode
b) Then it directly contacts the datanodes to read the data
Write process :
a) Client asks namenode for some datanodes to write the data and if available Namenode gives them
b)Client goes directly to the datanodes and write
На вопрос № 4. Клиент записывает данные непосредственно в Datanode. Однако, прежде чем он сможет записать в DataNode, он должен поговорить с Namenode, чтобы получить метаданные, например, какой Datanode и в какой блок записывать.
Да, NameNode управляет этим. Также часто эти данные будут сохраняться в fsimage и редактировать файлы, которые будут на локальном диске.
Нет, все метаданные будут поддерживаться NameNode. Из-за чего нагрузка на датодель будет меньше для поддержки метаданных.
Там будет только один основной NameNode. Как я уже говорил, для управления лимитом размера метаданных данные будут часто сохраняться в fsimage и редактироваться через контрольные точки.
Клиент может связаться с DataNode, как только он получает информацию о файле от NameNode.