КОЛЛАДА: Обратная позиция связывания в неправильном пространстве?
Я работаю над написанием своего собственного импортера COLLADA. Я продвинулся довольно далеко, загружая сетки, материалы и тому подобное. Но я столкнулся с проблемой анимации, а именно: совместных вращений.
Формула, которую я использую для снятия шкур с моей сетки, проста:
weighted;
for (i = 0; i < joint_influences; i++)
{
weighted +=
joint[joint_index[i]]->parent->local_matrix *
joint[joint_index[i]]->local_matrix *
skin->inverse_bind_pose[joint_index[i]] *
position *
skin->weight[j];
}
position = weighted;
А что касается литературы, это правильная формула. Теперь COLLADA определяет два типа поворотов для суставов: локальный и глобальный. Вы должны объединить вращения вместе, чтобы получить локальное преобразование для соединения.
То, что документация COLLADA не различает, является локальной ротацией соединения и глобальной ротацией соединения. Но в большинстве моделей, которые я видел, у вращений может быть rotate (глобальный) или jointOrient (местный).
Когда я игнорирую глобальные повороты и использую только локальные, я получаю позу привязки для модели. Но когда я добавляю глобальное вращение к локальной трансформации сустава, начинают происходить странные вещи.
Это без использования глобальных вращений:

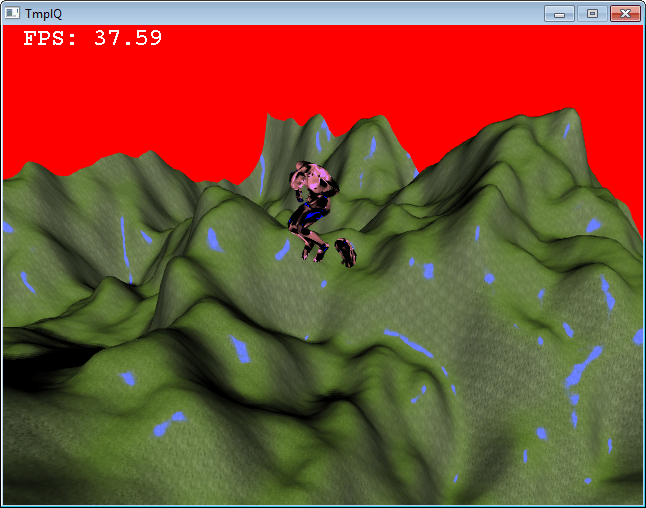
И это с глобальными вращениями:

На обоих скриншотах я рисую скелет, используя линии, но на первом он невидим, потому что соединения находятся внутри сетки. На втором скриншоте вершины повсюду!
Для сравнения, вот так должен выглядеть второй скриншот:

Это трудно увидеть, но вы можете видеть, что суставы находятся в правильном положении на втором скриншоте.
Но теперь странная вещь. Если я игнорирую обратную позу связывания, указанную COLLADA, и вместо этого возьму обратное значение локального преобразования родительского соединения, умноженное на локальное преобразование соединения, я получу следующее:

На этом скриншоте я рисую линию от каждой вершины до соединений, которые имеют влияние. То, что я получаю позу связывания, не так странно, потому что формула теперь становится:
world_matrix * inverse_world_matrix * position * weight
Но это заставляет меня подозревать, что обратная поза связывания COLLADA находится не в том месте.
Поэтому мой вопрос: в каком пространстве COLLADA определяет свою обратную позицию связывания? И как я могу преобразовать обратную позу связывания в нужное мне пространство?
2 ответа
Я начал со сравнения моих значений со значениями, которые я прочитал из Assimp (загрузчик моделей с открытым исходным кодом). Пошагово просматривая код, я посмотрел, где они построили свои матрицы связывания и обратные матрицы связывания.
В конце концов я оказался в SceneAnimator::GetBoneMatrices, который содержит следующее:
// Bone matrices transform from mesh coordinates in bind pose to mesh coordinates in skinned pose
// Therefore the formula is offsetMatrix * currentGlobalTransform * inverseCurrentMeshTransform
for( size_t a = 0; a < mesh->mNumBones; ++a)
{
const aiBone* bone = mesh->mBones[a];
const aiMatrix4x4& currentGlobalTransform
= GetGlobalTransform( mBoneNodesByName[ bone->mName.data ]);
mTransforms[a] = globalInverseMeshTransform * currentGlobalTransform * bone->mOffsetMatrix;
}
globalInverseMeshTransform всегда идентичность, потому что меш ничего не трансформирует. currentGlobalTransform является матрицей связывания, локальными матрицами родительского соединения, соединенными с локальной матрицей соединения. А также mOffsetMatrix является обратной матрицей связывания, которая поступает непосредственно из кожи.
Я проверил значения этих матриц самостоятельно (да, я сравнил их в окне наблюдения), и они были точно такими же, возможно, на 0,0001%, но это несущественно. Так почему же версия Assimp работает, а моя - нет, хотя формула одна и та же?
Вот что я получил:

Когда Assimp, наконец, загружает матрицы в шейдер скининга, они делают следующее:
helper->piEffect->SetMatrixTransposeArray( "gBoneMatrix", (D3DXMATRIX*)matrices, 60);
Ваааааит секунду. Они загружают их транспонированными? Это не может быть так просто. Ни за что.
Ага.
Что-то еще я делал неправильно: я преобразовывал координаты нужной системы (сантиметры в метры), прежде чем применять матрицы скинов. Это приводит к полностью искаженным моделям, потому что матрицы предназначены для исходной системы координат.
БУДУЩИЕ ГАГЛЕРЫ
- Прочитайте все преобразования узлов (вращение, перевод, масштабирование и т. Д.) В порядке их получения.
- Объединить их в локальную матрицу соединения.
- Возьмите родителя сустава и умножьте его на локальную матрицу.
- Сохраните это как матрицу связывания.
- Прочитайте информацию о скине.
- Сохраните обратную позу матрицы соединения.
- Сохраните веса суставов для каждой вершины.
- Умножьте матрицу связывания с обратной матрицей позы связывания и транспонируйте ее, назовите ее матрицей скиннинга.
- Умножьте матрицу скинов на позицию, умноженную на вес сустава, и добавьте ее к взвешенной позиции.
- Используйте взвешенную позицию для рендеринга.
Готово!
Кстати, если вы транспонируете матрицы при их загрузке, а не транспонируете матрицу в конце (что может быть проблематично при анимации), вы хотите выполнить умножение по-другому (метод, который вы используете выше, кажется, используется для использования скинов в DirectX при использовании OpenGL дружественные матрицы - значит транспонировать.)
В DirectX я транспонирую матрицы, когда они загружаются из файла, а затем использую их (в приведенном ниже примере я просто применяю позу связывания для простоты):
XMMATRIX l_oWorldMatrix = XMMatrixMultiply (l_oBindPose, in_oParentWorldMatrix);
XMMATRIX l_oMatrixPallette = XMMatrixMultiply (l_oInverseBindPose, l_oWorldMatrix);
XMMATRIX l_oFinalMatrix = XMMatrixMultiply (l_oBindShapeMatrix, l_oMatrixPallette);