Выводить разницу в двух кадрах данных Pandas бок о бок - выделяя разницу
Я пытаюсь выделить именно то, что изменилось между двумя кадрами.
Предположим, у меня есть два фрейма данных Python Pandas:
"StudentRoster Jan-1":
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.11 False Graduated
113 Zoe 4.12 True
"StudentRoster Jan-2":
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.21 False Graduated
113 Zoe 4.12 False On vacation
Моя цель - вывести таблицу HTML, которая:
- Идентифицирует строки, которые изменились (может быть int, float, boolean, string)
Выводит строки с одинаковыми, старыми и новыми значениями (в идеале в таблицу HTML), чтобы потребитель мог ясно видеть, что изменилось между двумя кадрами данных:
"StudentRoster Difference Jan-1 - Jan-2": id Name score isEnrolled Comment 112 Nick was 1.11| now 1.21 False Graduated 113 Zoe 4.12 was True | now False was "" | now "On vacation"
Я полагаю, я мог бы сделать сравнение строка за строкой и столбец за столбцом, но есть ли более простой способ?
16 ответов
Первая часть похожа на Константина, вы можете получить логическое значение, строки которого пусты *:
In [21]: ne = (df1 != df2).any(1)
In [22]: ne
Out[22]:
0 False
1 True
2 True
dtype: bool
Затем мы можем увидеть, какие записи изменились:
In [23]: ne_stacked = (df1 != df2).stack()
In [24]: changed = ne_stacked[ne_stacked]
In [25]: changed.index.names = ['id', 'col']
In [26]: changed
Out[26]:
id col
1 score True
2 isEnrolled True
Comment True
dtype: bool
Здесь первая запись - это индекс, а вторая - столбцы, которые были изменены.
In [27]: difference_locations = np.where(df1 != df2)
In [28]: changed_from = df1.values[difference_locations]
In [29]: changed_to = df2.values[difference_locations]
In [30]: pd.DataFrame({'from': changed_from, 'to': changed_to}, index=changed.index)
Out[30]:
from to
id col
1 score 1.11 1.21
2 isEnrolled True False
Comment None On vacation
* Примечание: важно, чтобы df1 а также df2 поделитесь тем же индексом здесь. Чтобы преодолеть эту неоднозначность, вы можете убедиться, что вы смотрите только на общие ярлыки, используя df1.index & df2.index, но я думаю, что я оставлю это как упражнение.
Подчеркивая разницу между двумя фреймами данных
Можно использовать свойство стиля DataFrame, чтобы выделить цвет фона ячеек, где есть разница.
Используя данные примера из исходного вопроса
Первым шагом является объединение DataFrames по горизонтали с concat функционировать и различать каждый кадр с keys параметр:
df_all = pd.concat([df.set_index('id'), df2.set_index('id')],
axis='columns', keys=['First', 'Second'])
df_all
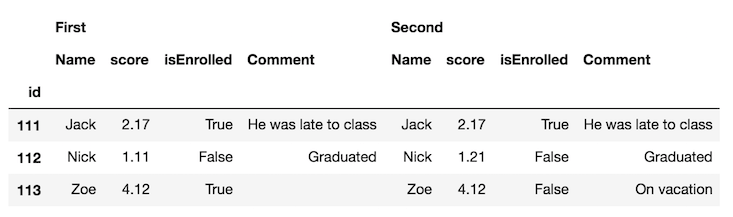
Вероятно, проще поменять местами уровни столбцов и поместить одинаковые имена столбцов рядом друг с другом:
df_final = df_all.swaplevel(axis='columns')[df.columns[1:]]
df_final
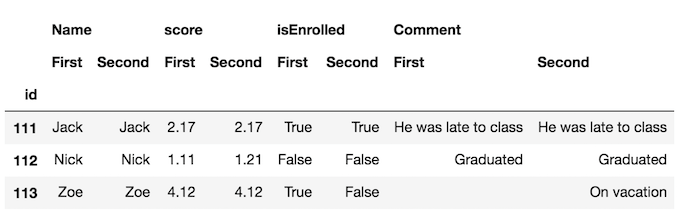
Теперь намного легче обнаружить различия в кадрах. Но мы можем пойти дальше и использовать style свойство выделять ячейки, которые отличаются. Для этого мы определяем пользовательскую функцию, которую вы можете увидеть в этой части документации.
def highlight_diff(data, color='yellow'):
attr = 'background-color: {}'.format(color)
other = data.xs('First', axis='columns', level=-1)
return pd.DataFrame(np.where(data.ne(other, level=0), attr, ''),
index=data.index, columns=data.columns)
df_final.style.apply(highlight_diff, axis=None)

Это будет подсвечивать ячейки, в которых отсутствуют значения. Вы можете либо заполнить их, либо предоставить дополнительную логику, чтобы они не выделялись.
Этот ответ просто расширяет @Andy Hayden, делая его устойчивым, когда числовые поля nanи завернуть его в функцию.
import pandas as pd
import numpy as np
def diff_pd(df1, df2):
"""Identify differences between two pandas DataFrames"""
assert (df1.columns == df2.columns).all(), \
"DataFrame column names are different"
if any(df1.dtypes != df2.dtypes):
"Data Types are different, trying to convert"
df2 = df2.astype(df1.dtypes)
if df1.equals(df2):
return None
else:
# need to account for np.nan != np.nan returning True
diff_mask = (df1 != df2) & ~(df1.isnull() & df2.isnull())
ne_stacked = diff_mask.stack()
changed = ne_stacked[ne_stacked]
changed.index.names = ['id', 'col']
difference_locations = np.where(diff_mask)
changed_from = df1.values[difference_locations]
changed_to = df2.values[difference_locations]
return pd.DataFrame({'from': changed_from, 'to': changed_to},
index=changed.index)
Итак, с вашими данными (слегка отредактировано, чтобы иметь NaN в столбце оценки):
import sys
if sys.version_info[0] < 3:
from StringIO import StringIO
else:
from io import StringIO
DF1 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.11 False "Graduated"
113 Zoe NaN True " "
""")
DF2 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.21 False "Graduated"
113 Zoe NaN False "On vacation" """)
df1 = pd.read_table(DF1, sep='\s+', index_col='id')
df2 = pd.read_table(DF2, sep='\s+', index_col='id')
diff_pd(df1, df2)
Выход:
from to
id col
112 score 1.11 1.21
113 isEnrolled True False
Comment On vacation
import pandas as pd
import io
texts = ['''\
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.11 False Graduated
113 Zoe 4.12 True ''',
'''\
id Name score isEnrolled Comment
111 Jack 2.17 True He was late to class
112 Nick 1.21 False Graduated
113 Zoe 4.12 False On vacation''']
df1 = pd.read_fwf(io.BytesIO(texts[0]), widths=[5,7,25,21,20])
df2 = pd.read_fwf(io.BytesIO(texts[1]), widths=[5,7,25,21,20])
df = pd.concat([df1,df2])
print(df)
# id Name score isEnrolled Comment
# 0 111 Jack 2.17 True He was late to class
# 1 112 Nick 1.11 False Graduated
# 2 113 Zoe 4.12 True NaN
# 0 111 Jack 2.17 True He was late to class
# 1 112 Nick 1.21 False Graduated
# 2 113 Zoe 4.12 False On vacation
df.set_index(['id', 'Name'], inplace=True)
print(df)
# score isEnrolled Comment
# id Name
# 111 Jack 2.17 True He was late to class
# 112 Nick 1.11 False Graduated
# 113 Zoe 4.12 True NaN
# 111 Jack 2.17 True He was late to class
# 112 Nick 1.21 False Graduated
# 113 Zoe 4.12 False On vacation
def report_diff(x):
return x[0] if x[0] == x[1] else '{} | {}'.format(*x)
changes = df.groupby(level=['id', 'Name']).agg(report_diff)
print(changes)
печать
score isEnrolled Comment
id Name
111 Jack 2.17 True He was late to class
112 Nick 1.11 | 1.21 False Graduated
113 Zoe 4.12 True | False nan | On vacation
панды>= 1.1: DataFrame.compare
С помощью pandas 1.1 вы могли практически воспроизвести вывод Теда Петру с помощью одного вызова функции. Пример взят из документации:
pd.__version__
# '1.1.0'
df1.compare(df2)
score isEnrolled Comment
self other self other self other
1 1.11 1.21 NaN NaN NaN NaN
2 NaN NaN 1.0 0.0 NaN On vacation
Здесь "я" относится к кадру данных LHS, а "другое" - к кадру данных RHS. По умолчанию равные значения заменяются NaN, поэтому вы можете сосредоточиться только на различиях. Если вы хотите показать равные значения, используйте
df1.compare(df2, keep_equal=True, keep_shape=True)
score isEnrolled Comment
self other self other self other
1 1.11 1.21 False False Graduated Graduated
2 4.12 4.12 True False NaN On vacation
Вы также можете изменить ось сравнения, используя align_axis:
df1.compare(df2, align_axis='index')
score isEnrolled Comment
1 self 1.11 NaN NaN
other 1.21 NaN NaN
2 self NaN 1.0 NaN
other NaN 0.0 On vacation
При этом значения сравниваются по строкам, а не по столбцам.
Я столкнулся с этой проблемой, но нашел ответ, прежде чем найти этот пост:
На основании ответа unutbu загрузите ваши данные...
import pandas as pd
import io
texts = ['''\
id Name score isEnrolled Date
111 Jack True 2013-05-01 12:00:00
112 Nick 1.11 False 2013-05-12 15:05:23
Zoe 4.12 True ''',
'''\
id Name score isEnrolled Date
111 Jack 2.17 True 2013-05-01 12:00:00
112 Nick 1.21 False
Zoe 4.12 False 2013-05-01 12:00:00''']
df1 = pd.read_fwf(io.BytesIO(texts[0]), widths=[5,7,25,17,20], parse_dates=[4])
df2 = pd.read_fwf(io.BytesIO(texts[1]), widths=[5,7,25,17,20], parse_dates=[4])
... определить вашу функцию сравнения...
def report_diff(x):
return x[0] if x[0] == x[1] else '{} | {}'.format(*x)
Затем вы можете просто использовать Panel для вывода:
my_panel = pd.Panel(dict(df1=df1,df2=df2))
print my_panel.apply(report_diff, axis=0)
# id Name score isEnrolled Date
#0 111 Jack nan | 2.17 True 2013-05-01 12:00:00
#1 112 Nick 1.11 | 1.21 False 2013-05-12 15:05:23 | NaT
#2 nan | nan Zoe 4.12 True | False NaT | 2013-05-01 12:00:00
Кстати, если вы находитесь в IPython Notebook, вы можете использовать цветную функцию сравнения, чтобы задавать цвета в зависимости от того, являются ли ячейки различными, равными или левыми / правыми нулевыми:
from IPython.display import HTML
pd.options.display.max_colwidth = 500 # You need this, otherwise pandas
# will limit your HTML strings to 50 characters
def report_diff(x):
if x[0]==x[1]:
return unicode(x[0].__str__())
elif pd.isnull(x[0]) and pd.isnull(x[1]):
return u'<table style="background-color:#00ff00;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % ('nan', 'nan')
elif pd.isnull(x[0]) and ~pd.isnull(x[1]):
return u'<table style="background-color:#ffff00;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % ('nan', x[1])
elif ~pd.isnull(x[0]) and pd.isnull(x[1]):
return u'<table style="background-color:#0000ff;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % (x[0],'nan')
else:
return u'<table style="background-color:#ff0000;font-weight:bold;">'+\
'<tr><td>%s</td></tr><tr><td>%s</td></tr></table>' % (x[0], x[1])
HTML(my_panel.apply(report_diff, axis=0).to_html(escape=False))
Другой подход с использованием concat и drop_duplicates:
import sys
if sys.version_info[0] < 3:
from StringIO import StringIO
else:
from io import StringIO
import pandas as pd
DF1 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.11 False "Graduated"
113 Zoe NaN True " "
""")
DF2 = StringIO("""id Name score isEnrolled Comment
111 Jack 2.17 True "He was late to class"
112 Nick 1.21 False "Graduated"
113 Zoe NaN False "On vacation" """)
df1 = pd.read_table(DF1, sep='\s+', index_col='id')
df2 = pd.read_table(DF2, sep='\s+', index_col='id')
#%%
dictionary = {1:df1,2:df2}
df=pd.concat(dictionary)
df.drop_duplicates(keep=False)
Выход:
Name score isEnrolled Comment
id
1 112 Nick 1.11 False Graduated
113 Zoe NaN True
2 112 Nick 1.21 False Graduated
113 Zoe NaN False On vacation
Если у ваших двух фреймов данных одинаковые идентификаторы, то выяснить, что изменилось, довольно просто. Просто делаю frame1 != frame2 даст вам логический DataFrame, где каждый True это данные, которые изменились. Исходя из этого, вы можете легко получить индекс каждой измененной строки, выполнив changedids = frame1.index[np.any(frame1 != frame2,axis=1)],
После возни с ответом @journois, я смог заставить его работать, используя MultiIndex вместо Panel из-за ограничения Panel.
Сначала создайте несколько фиктивных данных:
df1 = pd.DataFrame({
'id': ['111', '222', '333', '444', '555'],
'let': ['a', 'b', 'c', 'd', 'e'],
'num': ['1', '2', '3', '4', '5']
})
df2 = pd.DataFrame({
'id': ['111', '222', '333', '444', '666'],
'let': ['a', 'b', 'c', 'D', 'f'],
'num': ['1', '2', 'Three', '4', '6'],
})
Затем определите свою функцию сравнения, в этом случае я буду использовать один из его ответа report_diff остается такой же:
def report_diff(x):
return x[0] if x[0] == x[1] else '{} | {}'.format(*x)
Затем я собираюсь объединить данные в фрейм данных MultiIndex:
df_all = pd.concat(
[df1.set_index('id'), df2.set_index('id')],
axis='columns',
keys=['df1', 'df2'],
join='outer'
)
df_all = df_all.swaplevel(axis='columns')[df1.columns[1:]]
И, наконец, я собираюсь применить report_diff вниз по каждой группе столбцов:
df_final.groupby(level=0, axis=1).apply(lambda frame: frame.apply(report_diff, axis=1))
Это выводит:
let num
111 a 1
222 b 2
333 c 3 | Three
444 d | D 4
555 e | nan 5 | nan
666 nan | f nan | 6
И это все!
Расширение ответа @cge, что довольно круто для большей читабельности результата:
a[a != b][np.any(a != b, axis=1)].join(DataFrame('a<->b', index=a.index, columns=['a<=>b'])).join(
b[a != b][np.any(a != b, axis=1)]
,rsuffix='_b', how='outer'
).fillna('')
Полный демонстрационный пример:
a = DataFrame(np.random.randn(7,3), columns=list('ABC'))
b = a.copy()
b.iloc[0,2] = np.nan
b.iloc[1,0] = 7
b.iloc[3,1] = 77
b.iloc[4,2] = 777
a[a != b][np.any(a != b, axis=1)].join(DataFrame('a<->b', index=a.index, columns=['a<=>b'])).join(
b[a != b][np.any(a != b, axis=1)]
,rsuffix='_b', how='outer'
).fillna('')
Вот еще один способ с помощью выбора и слияния:
In [6]: # first lets create some dummy dataframes with some column(s) different
...: df1 = pd.DataFrame({'a': range(-5,0), 'b': range(10,15), 'c': range(20,25)})
...: df2 = pd.DataFrame({'a': range(-5,0), 'b': range(10,15), 'c': [20] + list(range(101,105))})
In [7]: df1
Out[7]:
a b c
0 -5 10 20
1 -4 11 21
2 -3 12 22
3 -2 13 23
4 -1 14 24
In [8]: df2
Out[8]:
a b c
0 -5 10 20
1 -4 11 101
2 -3 12 102
3 -2 13 103
4 -1 14 104
In [10]: # make condition over the columns you want to comapre
...: condition = df1['c'] != df2['c']
...:
...: # select rows from each dataframe where the condition holds
...: diff1 = df1[condition]
...: diff2 = df2[condition]
In [11]: # merge the selected rows (dataframes) with some suffixes (optional)
...: diff1.merge(diff2, on=['a','b'], suffixes=('_before', '_after'))
Out[11]:
a b c_before c_after
0 -4 11 21 101
1 -3 12 22 102
2 -2 13 23 103
3 -1 14 24 104
Вот то же самое из скриншота Jupyter:
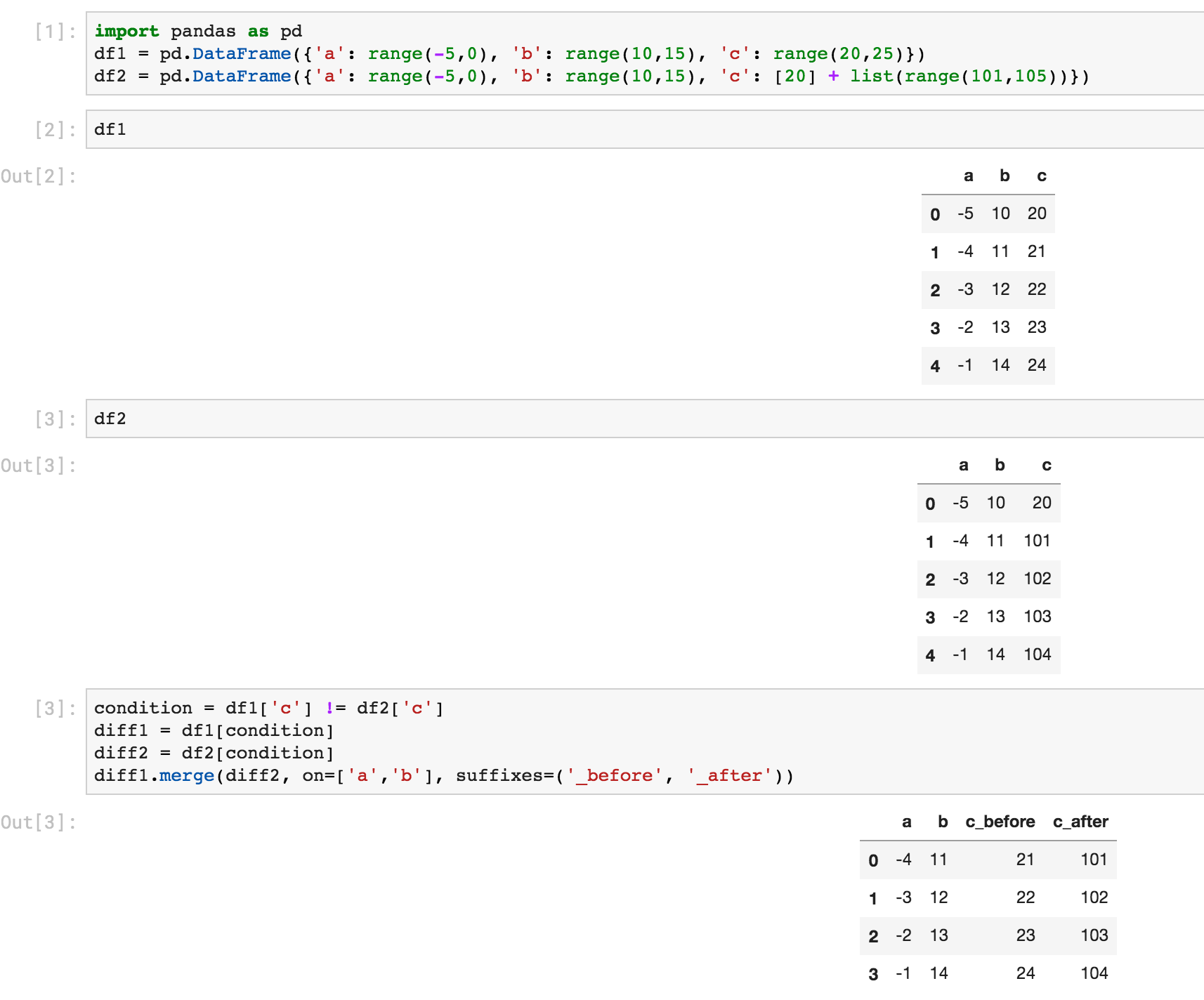
Если вы обнаружили, что эта ветка пытается сравнить данные в тестах, взгляните на assert_frame_equalметод: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.testing.assert_frame_equal.html
Этот ответ о том, как получить простой фрейм данных, в этом разница между двумя другими, что чем-то похоже на вопрос об операциях, но не совсем то же самое.
подходы
Подробно есть 2 варианта:
- Вы получаете фрейм данных со всеми строками из первого фрейма данных, которые не содержатся во втором фрейме данных.
- Вы получаете фрейм данных со всеми строками из второго фрейма данных, которые не содержатся в первом фрейме данных.
- Вы получаете кадр данных со всеми строками из варианта 1 и варианта 2.
код
# option 1
def diff_pd(df1: pd.DataFrame, df2: pd.DataFrame) -> pd.DataFrame:
common_rows = df1[df1.isin(df2.to_dict(orient='list')).all(axis=1)]
return = df1[~df1.isin(common_rows.to_dict(orient='list')).all(axis=1)]
# option 2
def diff_pd(df1: pd.DataFrame, df2: pd.DataFrame) -> pd.DataFrame:
common_rows = df1[df1.isin(df2.to_dict(orient='list')).all(axis=1)]
return = df2[~df2.isin(common_rows.to_dict(orient='list')).all(axis=1)]
Для третьего и самого сложного варианта вы просто объединяете результаты вариантов 1 и 2.
# option 3
def diff_pd(df1: pd.DataFrame, df2: pd.DataFrame) -> pd.DataFrame:
common_rows = df1[df1.isin(df2.to_dict(orient='list')).all(axis=1)]
df1 = df1[~df1.isin(common_rows.to_dict(orient='list')).all(axis=1)]
df2 = df2[~df2.isin(common_rows.to_dict(orient='list')).all(axis=1)]
return pd.concat([df1, df2])
Вы сможете использовать Dataframe.compare для этого сейчас, начиная с версии 1.1.0.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.compare.html
Функция, которая находит несимметричное различие между двумя фреймами данных, реализована ниже: (на основе разницы в наборах для панд) GIST: https://gist.github.com/oneryalcin/68cf25f536a25e65f0b3c84f9c118e03
def diff_df(df1, df2, how="left"):
"""
Find Difference of rows for given two dataframes
this function is not symmetric, means
diff(x, y) != diff(y, x)
however
diff(x, y, how='left') == diff(y, x, how='right')
Ref: https://stackru.com/questions/18180763/set-difference-for-pandas/40209800#40209800
"""
if (df1.columns != df2.columns).any():
raise ValueError("Two dataframe columns must match")
if df1.equals(df2):
return None
elif how == 'right':
return pd.concat([df2, df1, df1]).drop_duplicates(keep=False)
elif how == 'left':
return pd.concat([df1, df2, df2]).drop_duplicates(keep=False)
else:
raise ValueError('how parameter supports only "left" or "right keywords"')
Пример:
df1 = pd.DataFrame(d1)
Out[1]:
Comment Name isEnrolled score
0 He was late to class Jack True 2.17
1 Graduated Nick False 1.11
2 Zoe True 4.12
df2 = pd.DataFrame(d2)
Out[2]:
Comment Name isEnrolled score
0 He was late to class Jack True 2.17
1 On vacation Zoe True 4.12
diff_df(df1, df2)
Out[3]:
Comment Name isEnrolled score
1 Graduated Nick False 1.11
2 Zoe True 4.12
diff_df(df2, df1)
Out[4]:
Comment Name isEnrolled score
1 On vacation Zoe True 4.12
# This gives the same result as above
diff_df(df1, df2, how='right')
Out[22]:
Comment Name isEnrolled score
1 On vacation Zoe True 4.12
Импортировать панды как pd импортировать numpy как np
df = pd.read_excel('D:\HARISH\DATA SCIENCE\1 MY Training\SAMPLE DATA & projs\CRICKET DATA\IPL PLAYER LIST\IPL PLAYER LIST _ harish.xlsx')
df1= srh = df[df['TEAM'].str.contains("SRH")]df2 = csk = df[df['TEAM'].str.contains("CSK")]
srh = srh.iloc[:,0:2]csk = csk.iloc[:,0:2]
csk = csk.reset_index(drop = True)csk
srh = srh.reset_index(drop = True) srh
new = pd.concat([srh, csk], axis = 1)
new.head()
** ТИП ИГРОКА ТИП ИГРОКА
0 Дэвид Уорнер Бэтсмен... Капитан MS Dhoni
1 Бхуванешвар Кумар Боулер... Равиндра Джадеджа Универсал
2 Маниш Пандей Бэтсмен... Суреш Райна Универсал
3 Рашид Хан, Арман Боулер... Кедар Джадхав Универсал
4 Шикхар Дхаван Бэтсмен.... Дуэйн Браво Универсал