Scikit LDA: выбор оптимального количества тем - оценка недоумения
Этот пост рассматривается как вклад и попытка разработать скрипт для выбора оптимального количества тем в модели LDA в Scikit-Learn.
По сравнению с gensim, у меня было немного проблем с поиском метода для определения оптимального числа. Согласно литературным данным и этому посту, более низкий показатель недоумения указывает на лучшую эффективность обобщения. Недоумение обратно пропорционально логарифмической вероятности и может быть вычислено в Scikit через lda.perplexity(),
Я написал следующий скрипт для вычисления недоумения и логарифмической вероятности:
import numpy as np
import pandas as pd
np.random.seed(1)
from sklearn.datasets import fetch_20newsgroups
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med', 'sci.space']
train = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, random_state=7)
test = fetch_20newsgroups(subset='test', categories=categories, shuffle=True, random_state=7)
X_train, y_train = train.data, train.target
X_test, y_test = test.data, test.target
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
topics = range(5, 51, 5)
perplexities = []
loglikelihood = []
for i in topics:
print('Computing perplexity and log likelihood for #topics: {}'.format(i))
lda = LatentDirichletAllocation(n_components=i, max_iter=5, learning_method='online', random_state=1)
vec = CountVectorizer(stop_words='english')
tf = vec.fit_transform(X_train)
lda.fit(tf)
perplexities.append(np.log(lda.perplexity(tf)))
loglikelihood.append(lda.score(tf))
from matplotlib import pyplot as plt
plt.figure(figsize=(8, 3))
plt.subplot(1, 2, 1)
plt.plot(topics,loglikelihood)
plt.xlabel('Topics')
plt.ylabel('Log Likelihood')
plt.subplot(1, 2, 2)
plt.plot(topics,perplexities)
plt.xlabel('Topics')
plt.ylabel('Perplexity')
plt.show()
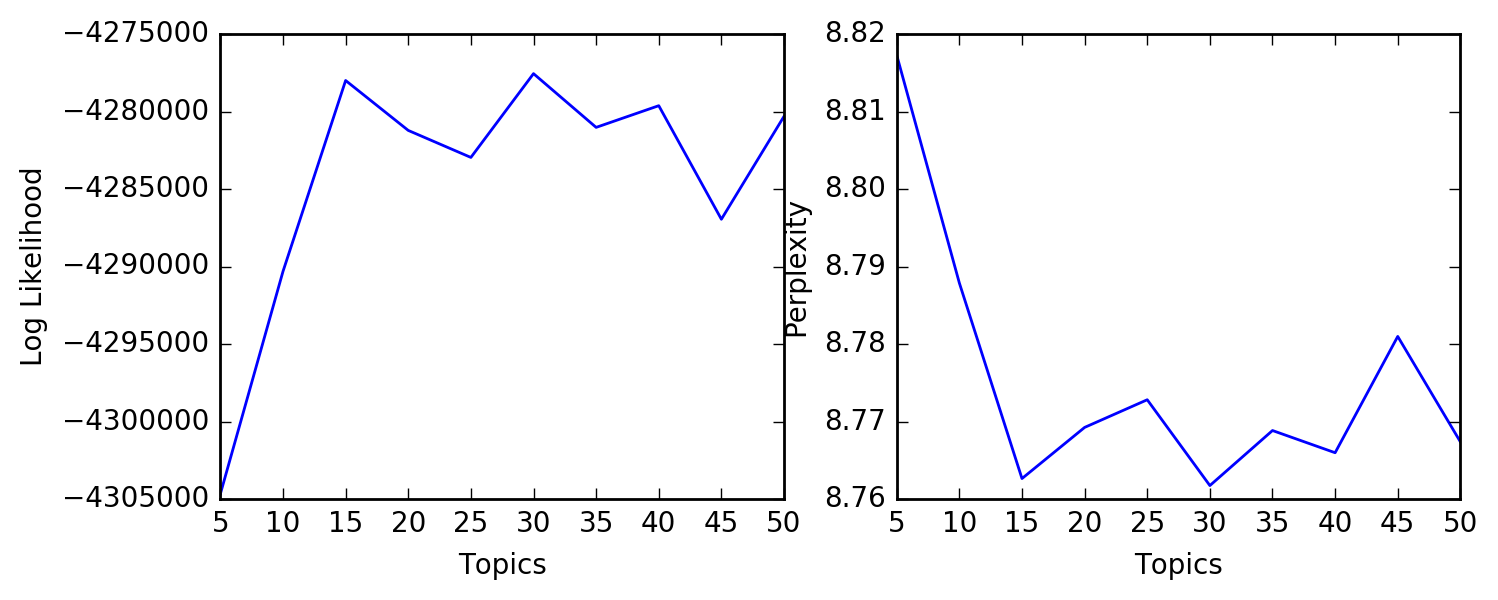
Вопросы:
- Можете ли вы воспроизвести данные?
- Будут ли 15 тем в данном случае оптимальным выбором?