Поиск в одном фрейме / словаре данных Python нечетких совпадений в другом фрейме данных
У меня есть следующий фрейм данных pandas с 50000 уникальных строк и 20 столбцов (в том числе фрагмент соответствующих столбцов):
df1:
PRODUCT_ID PRODUCT_DESCRIPTION
0 165985858958 "Fish Burger with Lettuce"
1 185965653252 "Chicken Salad with Dressing"
2 165958565556 "Pork and Honey Rissoles"
3 655262522233 "Cheese, Ham and Tomato Sandwich"
4 857485966653 "Coleslaw with Yoghurt Dressing"
5 524156285551 "Lemon and Raspberry Cheesecake"
У меня также есть следующий фрейм данных (который я также сохранил в виде словаря), который имеет 2 столбца и 20000 уникальных строк:
df2 (также сохраняется как dict_2)
PROD_ID PROD_DESCRIPTION
0 548576 "Fish Burger"
1 156956 "Chckn Salad w/Ranch Dressing"
2 257848 "Rissoles - Lamb & Rosemary"
3 298770 "Lemn C-cake"
4 651452 "Potato Salad with Bacon"
5 100256 "Cheese Cake - Lemon Raspberry Coulis"
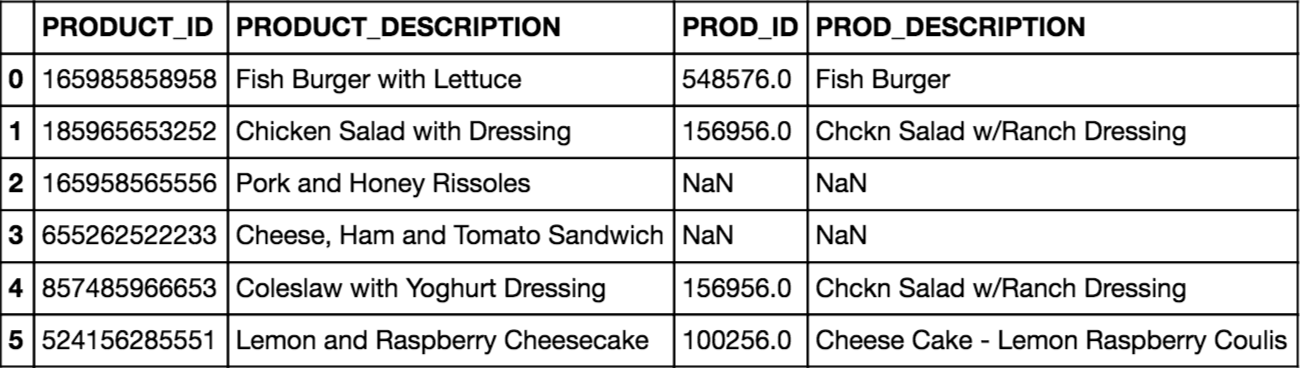
То, что я хочу сделать, это сравнить поле "PRODUCT_DESCRIPTION" в df1 с полем "PROD_DESCRIPTION" в df2 и найти самое близкое совпадение / совпадения, чтобы помочь с тяжелой подъемной частью. Затем мне нужно было бы вручную проверить совпадения, но это было бы намного быстрее. Идеальный результат выглядел бы так, например, с одним или несколькими отмеченными совпадениями:
PRODUCT_ID PRODUCT_DESCRIPTION PROD_ID PROD_DESCRIPTION
0 165985858958 "Fish Burger with Lettuce" 548576 "Fish Burger"
1 185965653252 "Chicken Salad with Dressing" 156956 "Chckn Salad w/Ranch Dressing"
2 165958565556 "Pork and Honey Rissoles" 257848 "Rissoles - Lamb & Rosemary"
3 655262522233 "Cheese, Ham and Tomato Sandwich" NaN NaN
4 857485966653 "Coleslaw with Yoghurt Dressing" NaN NaN
5 524156285551 "Lemon and Raspberry Cheesecake" 298770 "Lemn C-cake"
6 524156285551 "Lemon and Raspberry Cheesecake" 100256 "Cheese Cake - Lemon Raspberry Coulis"
Я уже завершил соединение, которое определило точные совпадения. Не важно, что индекс сохраняется, так как идентификаторы продукта в каждом файле DF уникальны. Результаты также могут быть сохранены в новом фрейме данных, поскольку затем они будут применены к третьему фрейму данных, который содержит около 14 миллионов строк.
Я использовал следующие вопросы и ответы (среди прочих):
Возможно ли сделать нечеткое слияние с пандами питона?
Нечеткое совпадение слияния с дубликатами, включая пробный модуль медузы, как предложено в одном из ответов
Нечеткое соответствие Python fuzzywuzzy сохранить только лучший матч
Нечеткие совпадения элементов в столбце массива
а также различные циклы / функции / отображения и т. д., но они не увенчались успехом, либо получили первое "нечеткое совпадение", которое имеет низкий балл, либо совпадений не обнаружено.
Мне нравится идея создания столбца оценки соответствия / расстояния, как здесь, так как это позволило бы мне ускорить процесс ручной проверки.
Я использую Python 2.7, панды и у меня установлен fuzzywuzzy.
3 ответа
С помощью fuzz.ratio в качестве моей метрики расстояния, вычислите мою матрицу расстояний следующим образом
df3 = pd.DataFrame(index=df.index, columns=df2.index)
for i in df3.index:
for j in df3.columns:
vi = df.get_value(i, 'PRODUCT_DESCRIPTION')
vj = df2.get_value(j, 'PROD_DESCRIPTION')
df3.set_value(
i, j, fuzz.ratio(vi, vj))
print(df3)
0 1 2 3 4 5
0 63 15 24 23 34 27
1 26 84 19 21 52 32
2 18 31 33 12 35 34
3 10 31 35 10 41 42
4 29 52 32 10 42 12
5 15 28 21 49 8 55
Установите порог для приемлемого расстояния. Я поставил 50
Найти значение индекса (для df2), который имеет максимальное значение для каждой строки.
threshold = df3.max(1) > 50
idxmax = df3.idxmax(1)
Делать назначения
df['PROD_ID'] = np.where(threshold, df2.loc[idxmax, 'PROD_ID'].values, np.nan)
df['PROD_DESCRIPTION'] = np.where(threshold, df2.loc[idxmax, 'PROD_DESCRIPTION'].values, np.nan)
df
Вы должны иметь возможность выполнять итерации по обоим фреймам данных и заполнять любой из 3-х фреймов данных желаемой информацией:
d = {
'df1_id': [],
'df1_prod_desc': [],
'df2_id': [],
'df2_prod_desc': [],
'fuzzywuzzy_sim': []
}
for _, df1_row in df1.iterrows():
for _, df2_row in df2.iterrows():
d['df1_id'] = df1_row['PRODUCT_ID']
...
df3 = pd.DataFrame.from_dict(d)
У меня недостаточно репутации, чтобы прокомментировать ответ @piRSquared. Отсюда и такой ответ.
- Определение vi и vj не прошло с ошибкой (
AttributeError: 'DataFrame' object has no attribute 'get_value'). Это сработало, когда я вставил «подчеркивание». Напримерvi = df._get_value(i, 'PRODUCT_DESCRIPTION') - Аналогичная проблема сохранялась для '
set_value'и там тоже работало то же решение. Напримерdf3._set_value(i, j, fuzz.ratio(vi, vj)) - Создание
idxmaxвозникла еще одна ошибка (TypeError: reduction operation 'argmax' not allowed for this dtype), что было связано с тем, что содержимое df3 (нечеткие отношения) было типа 'object'. Я преобразовал их все в числовые непосредственно перед определениемthresholdи это сработало. Напримерdf3 = df3.apply(pd.to_numeric)
Миллион спасибо @piRSquared за решение. Для такого новичка в Python, как я, это сработало как шарм. Я публикую этот ответ, чтобы упростить работу другим новичкам, таким как я.