Проблемы с надежностью Checkpointing/WAL в Spark Streaming 1.6.0
Описание
У нас есть приложение Spark Streaming 1.5.2 в Scala, которое считывает события JSON из потока Kinesis, выполняет некоторые преобразования / агрегации и записывает результаты в различные префиксы S3. Текущий интервал между партиями составляет 60 секунд. У нас 3000-7000 событий / сек. Мы используем контрольные точки, чтобы защитить нас от потери агрегатов.
Некоторое время он работал хорошо, восстанавливался после исключений и даже перезапуска кластера. Недавно мы перекомпилировали код для Spark Streaming 1.6.0, изменив только библиотечные зависимости в файле build.sbt. После запуска кода в кластере Spark 1.6.0 в течение нескольких часов мы заметили следующее:
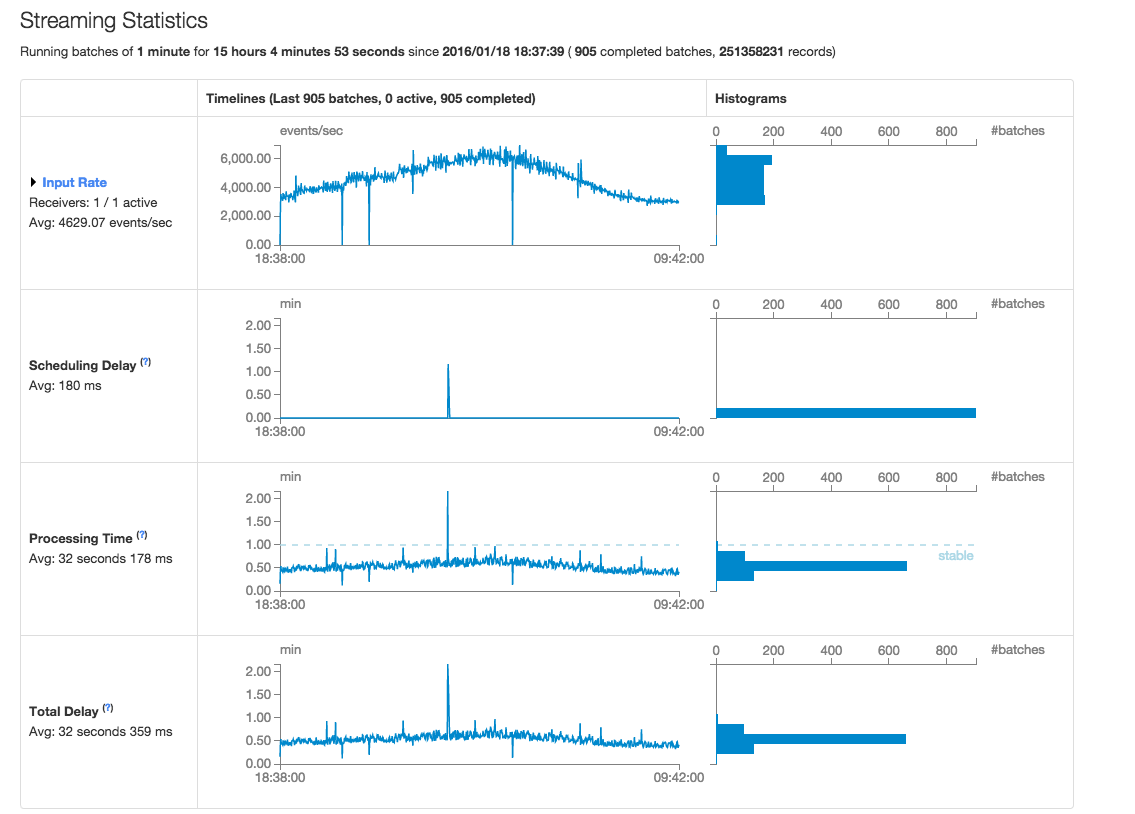
- Волатильность "Input Rate" и "Processing Time" существенно увеличилась (см. Скриншоты ниже) в 1.6.0.
- Каждые несколько часов при записи записи генерируется исключение: BlockAdditionEvent … в WriteAheadLog. java.util.concurrent.TimeoutException: тайм-аут фьючерса после исключения [5000 миллисекунд] "(см. полную трассировку стека ниже), совпадающего со снижением до 0 событий / сек для определенных пакетов (минут).
После некоторых копаний, я думаю, что вторая проблема выглядит связанной с этим запросом на извлечение. Первоначальная цель PR: "При использовании S3 в качестве каталога для WAL запись занимает слишком много времени. Драйвер очень легко становится узким местом, когда несколько получателей отправляют события AddBlock в ReceiverTracker. Этот PR добавляет пакет событий в ReceivedBlockTracker, чтобы драйверы не блокировались драйвером слишком долго ".
Мы проверяем S3 в Spark 1.5.2, и проблем с производительностью и надежностью нет. Мы проверили контрольные точки в Spark 1.6.0 в S3 и локальном NAS, и в обоих случаях мы получаем это исключение. Похоже, когда требуется более 5 секунд для контрольной точки пакета, возникает это исключение, и мы проверили, что события для этого пакета потеряны навсегда.
Вопросы
Ожидается ли увеличение волатильности "Входная скорость" и "Время обработки" в Spark Streaming 1.6.0 и существует ли какой-либо известный способ его улучшения?
Знаете ли вы какой-нибудь обходной путь, кроме этих 2?
1) Чтобы гарантировать, что приемник контрольных точек записывает все файлы менее чем за 5 секунд. По моему опыту, вы не можете гарантировать, что с S3, даже для небольших партий. Для локального NAS это зависит от того, кто отвечает за инфраструктуру (сложно с облачными провайдерами).
2) Увеличьте значение свойства spark.streaming.driver.writeAheadLog.batchingTimeout.
Ожидаете ли вы проиграть какие-либо события в описанном сценарии? Я думаю, что если контрольная точка пакета не будет выполнена, номера последовательности шарда / получателя не будут увеличены, и они будут повторены позже.
Статистика Spark 1.5.2 - Скриншот

Статистика Spark 1.6.0 - Скриншот
Полная трассировка стека
16/01/19 03:25:03 WARN ReceivedBlockTracker: Exception thrown while writing record: BlockAdditionEvent(ReceivedBlockInfo(0,Some(3521),Some(SequenceNumberRanges(SequenceNumberRange(StreamEventsPRD,shardId-000000000003,49558087746891612304997255299934807015508295035511636018,49558087746891612304997255303224294170679701088606617650), SequenceNumberRange(StreamEventsPRD,shardId-000000000004,49558087949939897337618579003482122196174788079896232002,49558087949939897337618579006984380295598368799020023874), SequenceNumberRange(StreamEventsPRD,shardId-000000000001,49558087735072217349776025034858012188384702720257294354,49558087735072217349776025038332464993957147037082320914), SequenceNumberRange(StreamEventsPRD,shardId-000000000009,49558088270111696152922722880993488801473174525649617042,49558088270111696152922722884455852348849472550727581842), SequenceNumberRange(StreamEventsPRD,shardId-000000000000,49558087841379869711171505550483827793283335010434154498,49558087841379869711171505554030816148032657077741551618), SequenceNumberRange(StreamEventsPRD,shardId-000000000002,49558087853556076589569225785774419228345486684446523426,49558087853556076589569225789389107428993227916817989666))),BlockManagerBasedStoreResult(input-0-1453142312126,Some(3521)))) to the WriteAheadLog.
java.util.concurrent.TimeoutException: Futures timed out after [5000 milliseconds]
at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:219)
at scala.concurrent.impl.Promise$DefaultPromise.result(Promise.scala:223)
at scala.concurrent.Await$$anonfun$result$1.apply(package.scala:107)
at scala.concurrent.BlockContext$DefaultBlockContext$.blockOn(BlockContext.scala:53)
at scala.concurrent.Await$.result(package.scala:107)
at org.apache.spark.streaming.util.BatchedWriteAheadLog.write(BatchedWriteAheadLog.scala:81)
at org.apache.spark.streaming.scheduler.ReceivedBlockTracker.writeToLog(ReceivedBlockTracker.scala:232)
at org.apache.spark.streaming.scheduler.ReceivedBlockTracker.addBlock(ReceivedBlockTracker.scala:87)
at org.apache.spark.streaming.scheduler.ReceiverTracker.org$apache$spark$streaming$scheduler$ReceiverTracker$$addBlock(ReceiverTracker.scala:321)
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverTrackerEndpoint$$anonfun$receiveAndReply$1$$anon$1$$anonfun$run$1.apply$mcV$sp(ReceiverTracker.scala:500)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1230)
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverTrackerEndpoint$$anonfun$receiveAndReply$1$$anon$1.run(ReceiverTracker.scala:498)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Извлечение исходного кода
...
// Function to create a new StreamingContext and set it up
def setupContext(): StreamingContext = {
...
// Create a StreamingContext
val ssc = new StreamingContext(sc, Seconds(batchIntervalSeconds))
// Create a Kinesis DStream
val data = KinesisUtils.createStream(ssc,
kinesisAppName, kinesisStreamName,
kinesisEndpointUrl, RegionUtils.getRegionByEndpoint(kinesisEndpointUrl).getName(),
InitialPositionInStream.LATEST, Seconds(kinesisCheckpointIntervalSeconds),
StorageLevel.MEMORY_AND_DISK_SER_2, awsAccessKeyId, awsSecretKey)
...
ssc.checkpoint(checkpointDir)
ssc
}
// Get or create a streaming context.
val ssc = StreamingContext.getActiveOrCreate(checkpointDir, setupContext)
ssc.start()
ssc.awaitTermination()
1 ответ
Следуя предложению zero323 о публикации моего комментария в качестве ответа:
Увеличение spark.streaming.driver.writeAheadLog.batchingTimeout решило проблему тайм-аута контрольной точки. Мы сделали это, убедившись, что у нас есть место для этого. Мы тестировали это уже некоторое время. Поэтому я рекомендую увеличивать его только после тщательного рассмотрения.
ПОДРОБНОСТИ
Мы использовали эти 2 параметра в $ SPARK_HOME / conf / spark-defaults.conf:
spark.streaming.driver.writeAheadLog.allowBatching true spark.streaming.driver.writeAheadLog.batchingTimeout 15000
Первоначально у нас было только значение spark.streaming.driver.writeAheadLog.allowBatching, равное true.
Перед изменением мы воспроизвели проблему, упомянутую в вопросе ("...ReceivedBlockTracker: исключение, сгенерированное при записи записи...") в среде тестирования. Это происходило каждые несколько часов. После изменения проблема исчезла. Мы запускали его в течение нескольких дней, прежде чем перейти к производству.
Мы обнаружили, что метод getBatchingTimeout() класса WriteAheadLogUtils имеет значение по умолчанию 5000 мс, как показано здесь:
def getBatchingTimeout(conf: SparkConf): Long = {
conf.getLong(DRIVER_WAL_BATCHING_TIMEOUT_CONF_KEY, defaultValue = 5000)
}