Python: сохранить страницу с большим количеством графики в виде файла.html
Я хочу сохранить посещенную страницу на диске в виде файла. Я использую urllib и URLOpener. Я выбираю сайт http://emma-watson.net/. Файл правильно сохраняется в формате.html, но когда я открыл файл, я заметил, что главное изображение сверху, которое содержит закладки для других подстраниц, не отображается, а также некоторые другие элементы (например, POTD). Как правильно сохранить страницу, чтобы вся страница была сохранена на диске?
def saveUrl(url):
testfile = urllib.URLopener()
testfile.retrieve(url,"file.html")
...
saveUrl("http://emma-watson.net")
Экран реальной страницы: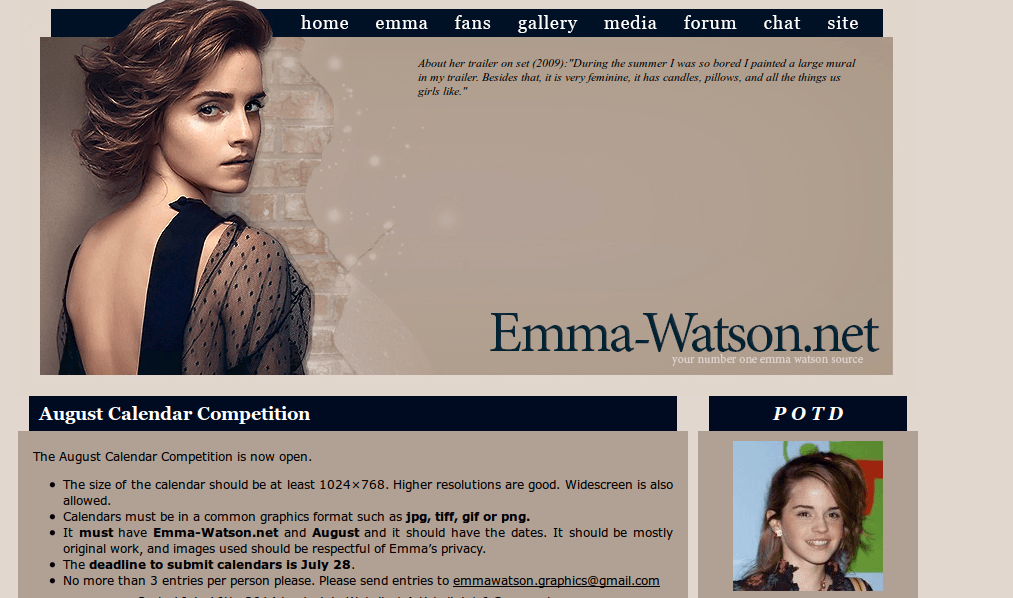 Экран открытого файла на моем диске:
Экран открытого файла на моем диске: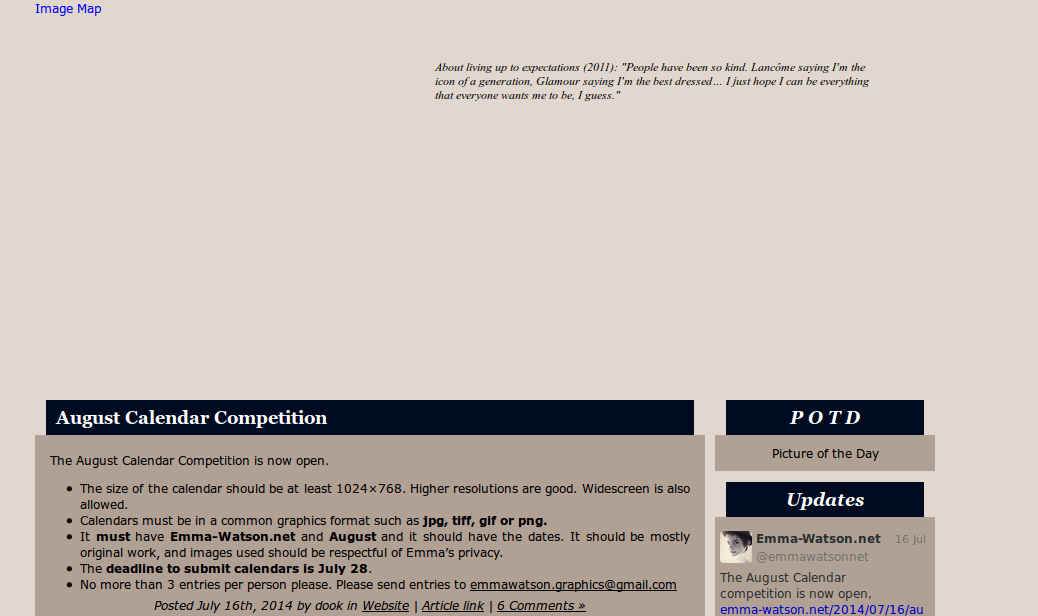
1 ответ
То, что вы пытаетесь сделать, - это создать очень простой веб-скребок (то есть вы хотите найти все ссылки в файле и загрузить их, но не хотите делать это рекурсивно, или выполнять какую-либо необычную фильтрацию или постобработка и т. д.).
Вы можете сделать это с помощью полноценной библиотеки веб-скребка, такой как scrapy и просто ограничив его до глубины 1 и не включая ничего другого.
Или вы можете сделать это вручную. Выберите ваш любимый HTML-парсер (BeautifulSoup прост в использовании; html.parser встроен в stdlib; Есть десятки других вариантов). Загрузите страницу, затем проанализируйте полученный файл и отсканируйте его img, a, script и т. д. с URL-адресами, затем загрузите эти URL-адреса, и все готово.
Если вы хотите, чтобы все это хранилось в одном файле, существует целый ряд форматов "файла веб-архива", и разные браузеры (и другие инструменты) поддерживают разные. Основная идея большинства из них заключается в том, что вы создаете zip-файл с файлами в определенном макете и с некоторым расширением, например.webarch вместо.zip. Это легко. Но вам также нужно изменить все абсолютные ссылки на относительные, что немного сложнее. Тем не менее, это не так сложно с таким инструментом, как BeautifulSoup или же html.parser или же lxml,
Как примечание, если вы на самом деле не используете UrlOpener во всяком случае, вы делаете жизнь тяжелее для себя без уважительной причины; просто используйте urlopen, Кроме того, как упоминают документы, вы должны использовать urllib2 не urllib; по факту urllib.urlopen устарело с 2.6. И даже если вам действительно нужно использовать явное средство открытия, как говорят документы: "Если вам не нужна поддержка открытия объектов с использованием схем, отличных от http:, ftp: или file:, вы, вероятно, захотите использовать FancyURLopener ".
Вот простой пример (достаточно, чтобы начать, как только вы решите, что делать, а что нет), используя BeautifulSoup:
import os
import urllib2
import urlparse
import bs4
def saveUrl(url):
page = urllib2.urlopen(url).read()
with open("file.html", "wb") as f:
f.write(page)
soup = bs4.BeautifulSoup(f)
for img in soup('img'):
imgurl = img['src']
imgpath = urlparse.urlparse(imgurl).path
imgpath = 'file.html_files/' + imgpath
os.makedirs(os.path.dirname(imgpath))
img = urllib2.urlopen(imgurl)
with open(imgpath, "wb") as f:
f.write(img)
saveUrl("http://emma-watson.net")
Этот код не будет работать, если есть изображения с относительными ссылками. Чтобы справиться с этим, вам нужно позвонить urlparse.urljoin прикрепить базовый URL. И, поскольку базовый URL может быть задан различными способами, если вы хотите обрабатывать каждую страницу, которую кто-либо когда-либо напишет, вам нужно прочитать документацию и написать соответствующий код. Именно в этот момент вы должны начать смотреть на что-то вроде scrapy, Но, если вы просто хотите работать с несколькими сайтами, просто написать что-то, что работает для этих сайтов, хорошо.
Между тем, если какое-либо из изображений загружается JavaScript по истечении времени загрузки страницы, что является довольно распространенным явлением на современных веб-сайтах, ничего не будет работать, за исключением фактического выполнения этого кода JavaScript. В этот момент вам, вероятно, понадобится инструмент автоматизации браузера, такой как Selenium, или инструмент симулятора браузера, такой как Mechanize+PhantomJS, а не скребок.