Производительность чтения Tokumx VS mongodb
Я проводил стресс-тестирование производительности чтения, сравнивая Tokumx и чистый Mongodb.
- Tokumx Community Edition 2.0.0
- MongoDB 2.6.4_1
И tokumx, и mongodb работали на одной машине.
Обзор аппаратного обеспечения:
Model Name: Mac mini
Model Identifier: Macmini6,1
Processor Name: Intel Core i5
Processor Speed: 2.5 GHz
Number of Processors: 1
Total Number of Cores: 2
L2 Cache (per Core): 256 KB
L3 Cache: 3 MB
Memory: 10 GB
В каждом экземпляре только одна коллекция. В каждой коллекции 100 000 записей.
Для tokumx он был создан как секционированная коллекция. Но для mongodb он был создан как обычная коллекция:
db.createCollection("sample", {partitioned: true, primaryKey: {field1:1, _id: 1}});
И для обоих экземпляров индекс выглядит следующим образом:
db.sample.ensureIndex({field1:1});
db.sample.ensureIndex({field2:1});
db.sample.ensureIndex({field3:1});
db.sample.ensureIndex({field4:1});
db.sample.ensureIndex({geo:"2d"});
db.sample.ensureIndex({"created_at":1});
Я использовал Tsung для проведения стресс-тестирования. В плане тестирования я сделал простой поиск, посмотрев field2 а также geo порядок полей по created_at убывание.
<clients>
<client host="localhost" use_controller_vm="false" maxusers="8000"/>
</clients>
<servers>
<server host="jchimac.thenetcircle.lab" port="8080" type="tcp"/>
</servers>
<load duration="5" unit="minute">
<arrivalphase phase="1" duration="5" unit="minute">
<users interarrival="0.03" unit="second"/>
</arrivalphase>
</load>
Согласно официальному документу, сделка должна быть похожа на TOKUMX ™ BENCHMARK VS. MONGODB - HDD
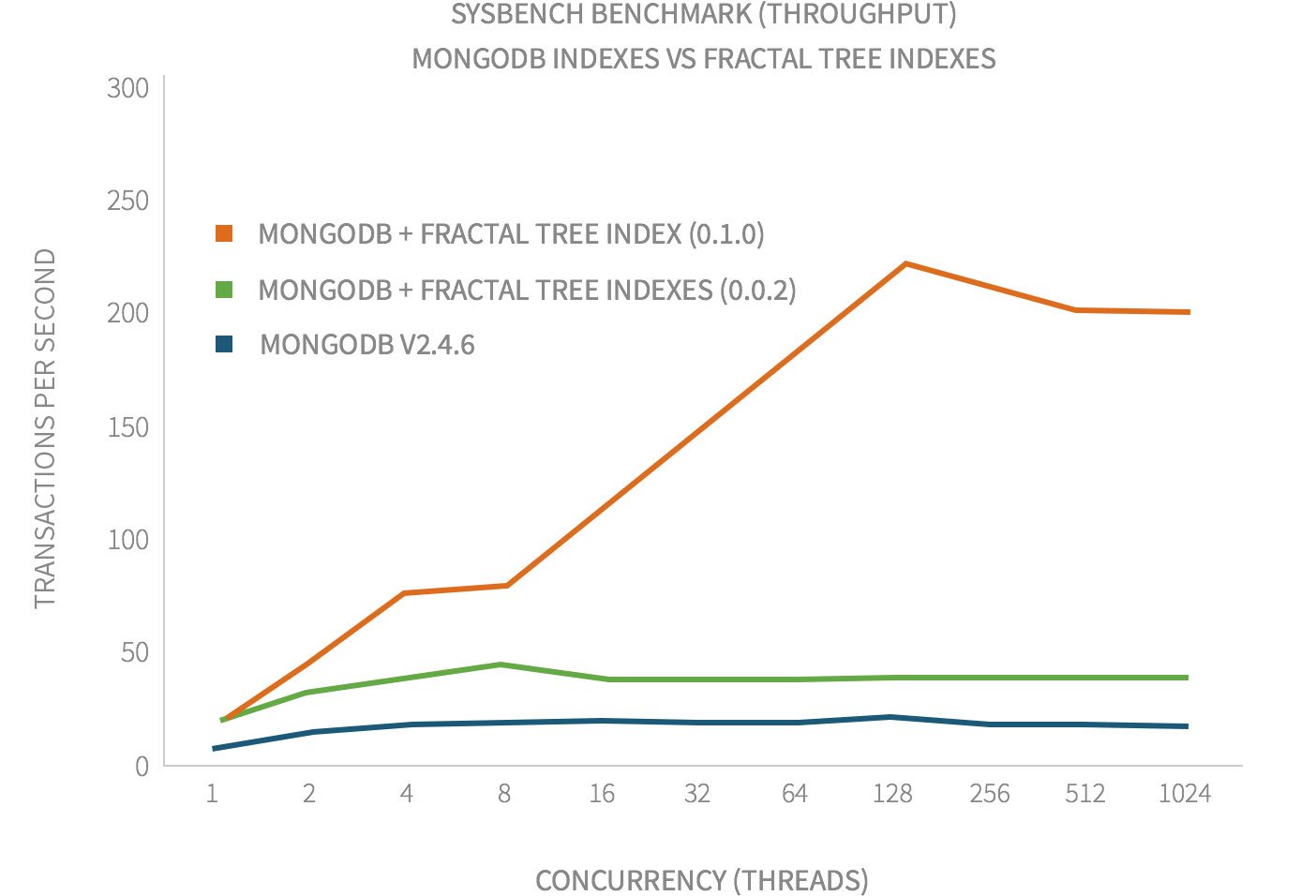
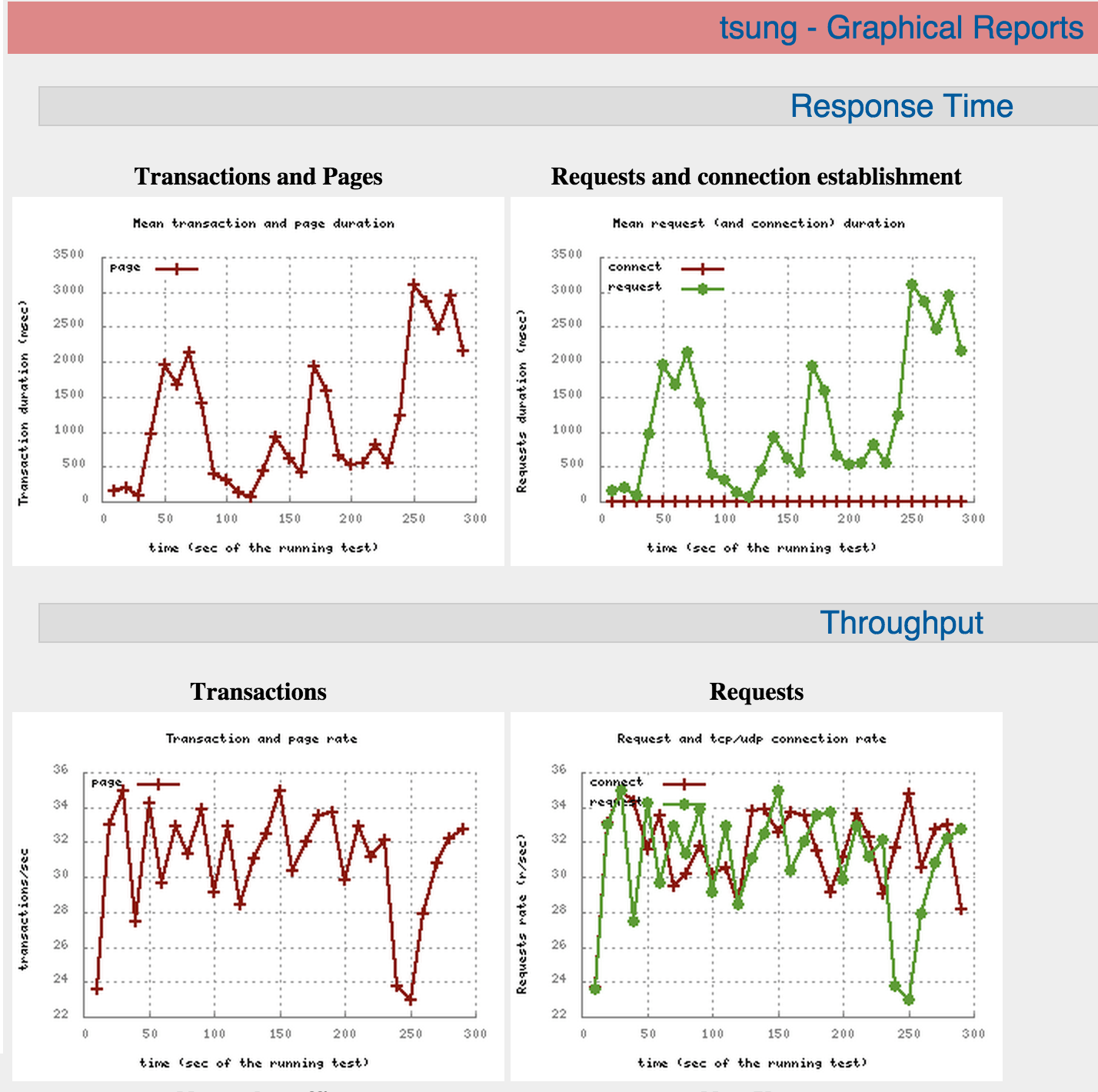
Но в моем тестировании:
TOKUMX:

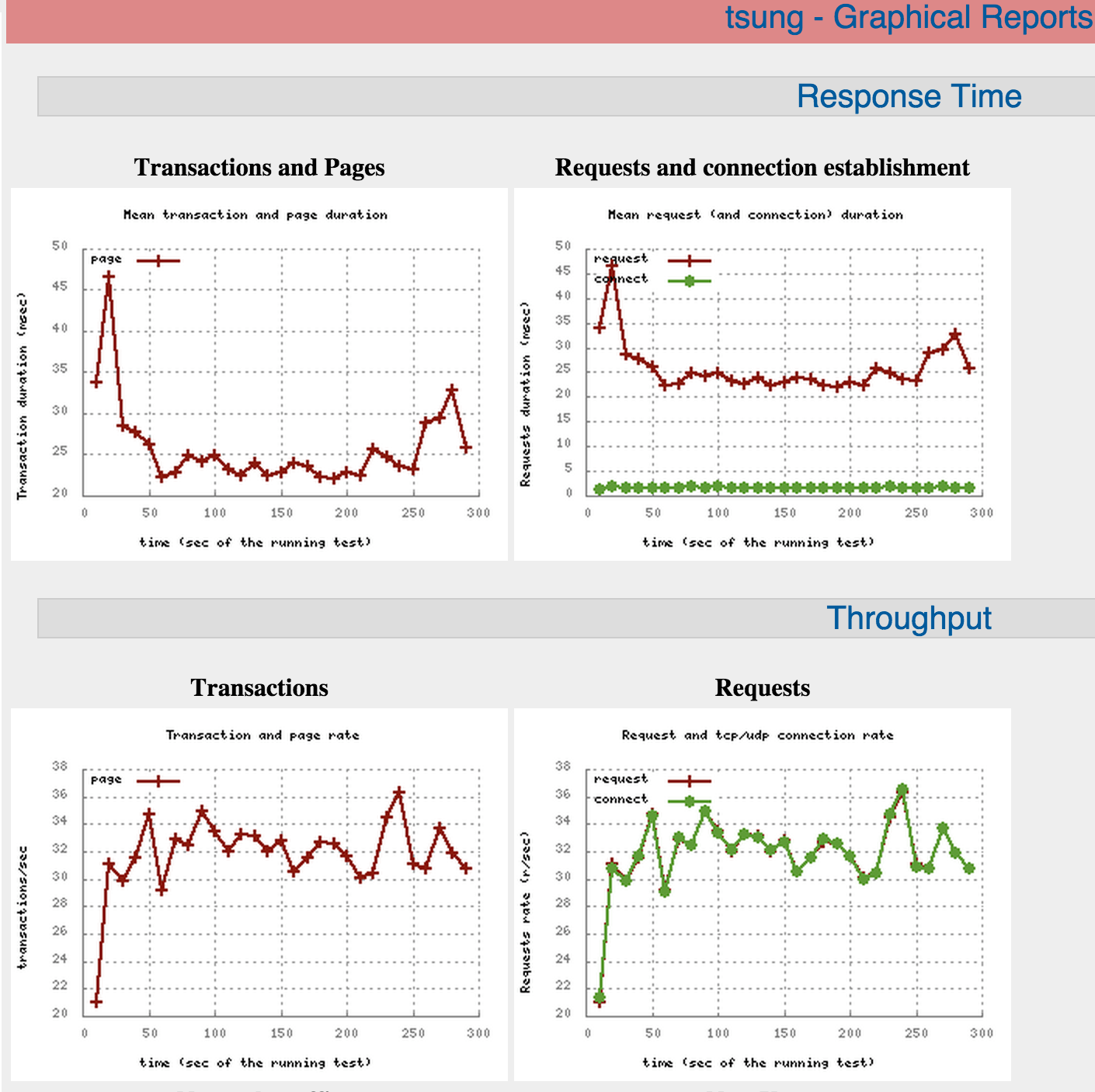
MongoDB:

Я спрашиваю здесь, чтобы знать, кто-нибудь может дать намек на это? Я что-то пропустил во всем тестировании?
Обновления:
Я провел еще одно тестирование на машине с Linux(CentOS):
CentOS release 6.5 (Final)
2.6.32-504.1.3.el6.x86_64 GNU/Linux
MemTotal: 24589896 kB
CPU: 12* (Intel(R) Xeon(R) CPU E5645 @ 2.40GHz)
Пример данных выглядит так:
{
"_id": ObjectId("54867dc8ffbc15aa2bc3ee0e"),
"_iid": 15,
"_pid": 15,
"uid": 102296,
"nickname": "nickname_102296",
"gender": 3,
"image_id": 15,
"created_at": 1418100168,
"tag": 1,
"geo": {
"lat": 51.590449999999997033,
"lon": 6.9671900000000004383
}
}
Каждая коллекция имеет 1 000 000 записей.
Индексы для каждой коллекции (создаются обычные коллекции):
db.createCollection("coll", {primaryKey: {_pid:1, _id: 1}});
db.tokumx_coll.ensureIndex({gender:1});
db.tokumx_coll.ensureIndex({uid:1});
db.tokumx_coll.ensureIndex({geo:"2d"});
db.tokumx_coll.ensureIndex({_pid:1});
db.tokumx_coll.ensureIndex({_iid:1});
db.tokumx_coll.ensureIndex({"created_at":1});
План тестирования также довольно прост:
{'$query', {gender,3,geo, {'$geoWithin', {'$center', [[48.72761, 9.24596], 0.005]}}}, '$orderby',{'_pid',-1}}
Стресс-тест Tsung проводится в течение 1 часа для каждого теста. И параллелизм составляет 1 запрос в секунду.
<load>
<arrivalphase phase="1" duration="60" unit="minute">
<users interarrival="1" unit="second"/>
</arrivalphase>
</load>
Вот отчет на скриншоте:
TOKUMX:


MongoDB:


Обновления @2014.12.12 Обнаружил это: https://github.com/Tokutek/mongo/issues/1014
3 ответа
TokuMX 2.0.0 Community Edition для MongoDB по-прежнему построен на MongoDB 2.4, который еще не имел индекса GEO 2dsphere, когда я писал этот пост. Поэтому, если вы создаете составные индексы, имеющие индекс GEO, вам придется подождать базу версий на MongoDB 2.6, которая поддерживает индекс geo 2dshere.
В принципе:
- "2d индексы": составные индексы только с одним дополнительным полем как суффикс поля 2d индекса
- "2dsphere indexes": составные индексы со скалярными индексными полями (т. Е. По возрастанию или по убыванию) в качестве префикса или суффикса 2dsphere index field
И если вас больше интересует мое стресс-тестирование, вы можете найти его в этом посте.
Транзакция Sysbench включает в себя операции вставки / обновления / удаления, но описываемый вами тест доступен только для чтения. Основной причиной того, что TokuMX достигает гораздо более высоких результатов Sysbench, чем MongoDB, является параллелизм записи.
Я рад видеть, что вы интересуетесь TokuMX. Тем не менее, есть ряд вопросов о вашей настройке бенчмаркинга, на которые вы должны ответить, прежде чем пытаться сделать выводы из результатов:
Вы работаете на Mac mini. TokuMX поддерживается только для разработки на OSX, а не для производства. Есть несколько явных проблем с производительностью в OSX, которые мы решили в Linux. Если вы заинтересованы в оценке производительности TokuMX, вам действительно следует тестировать Linux на выделенном оборудовании.
График, который вы показали из наших маркетинговых материалов, описывает, как изменяется пропускная способность конкретного теста (sysbench), когда мы меняем количество одновременных потоков. Tsung, похоже, не измеряет пропускную способность по сравнению с параллелизмом, так почему вы ожидаете, что он будет иметь характеристики, подобные графику на нашем сайте?
Рабочая нагрузка Tsung похожа на ваше приложение? Как вы выбрали проверенную схему? Представляет ли это модель данных вашего приложения? Ваши запросы не совпадают с выбранными вами индексами; если вы хотите проверить запросы на
field2, geo, created_atтогда у вас должен быть индекс, который упорядочивает данные в соответствии с этим ключом. Я ожидаю, что ваше приложение не просто рабочая нагрузка только для чтения, которая не использует индексы, которые вы определили для небольшого набора данных. Подумайте больше о том, как разработать эталон, который будет представлять ваше приложение. Или, что еще лучше, просто запустите ваше приложение или следите за ним и следите за показателями, которые вам нужны.Время выполнения вашего теста составляет всего 5 минут, и большая часть выходных данных демонстрирует значительные расхождения во время выполнения. Если эта рабочая нагрузка вам интересна, вы, вероятно, захотите запустить ее намного дольше (и, возможно, на большем наборе данных), собрать много данных и сравнить гистограммы пропускной способности и задержки с TokuMX и MongoDB.
Почему вы создали многораздельную коллекцию? Вы создали какие-либо разделы? Соответствует ли эта парадигма требованиям вашего приложения?
Я думаю, что если вы начнете отвечать на эти вопросы, вы приведете себя к несоответствиям, которые вы видите, и, надеюсь, вы приблизитесь к эталону, который даст вам надежные и действенные результаты.