Как Hadoop выполняет разбиение ввода?
Это концептуальный вопрос, касающийся Hadoop/HDFS. Допустим, у вас есть файл, содержащий 1 миллиард строк. И для простоты, давайте рассмотрим, что каждая строка имеет вид <k,v> где k - смещение строки от начала, а value - содержимое строки.
Теперь, когда мы говорим, что хотим запустить N задач карты, разделяет ли фреймворк входной файл на N разбиений и запускает каждую задачу карты в этом разбиении? или мы должны написать функцию разбиения, которая разделяет N, и запускать каждую задачу карты в сгенерированном разбиении?
Все, что я хочу знать, это то, делаются ли внутренние операции, или мы должны разделить данные вручную?
Более конкретно, каждый раз, когда вызывается функция map(), каковы ее Key key and Value val параметры?
Спасибо, Дипак
11 ответов
InputFormat несет ответственность за обеспечение расколов.
В общем, если у вас есть n узлов, HDFS распределяет файл по всем этим n узлам. Если вы начнете работу, по умолчанию будет n мапперов. Благодаря Hadoop картограф на машине будет обрабатывать часть данных, которые хранятся на этом узле. Я думаю это называется Rack awareness,
Короче говоря, загрузите данные в HDFS и запустите работу MR. Hadoop позаботится об оптимизированном исполнении.
Файлы разбиваются на блоки HDFS, а блоки реплицируются. Hadoop назначает узел для разделения на основе принципа локальности данных. Hadoop попытается выполнить отображение на узлах, где находится блок. Из-за репликации существует несколько таких узлов, на которых размещается один и тот же блок.
Если узлы недоступны, Hadoop попытается выбрать узел, ближайший к узлу, на котором размещен блок данных. Например, он может выбрать другой узел в той же стойке. Узел может быть недоступен по разным причинам; все слоты карты могут быть использованы или узел может просто не работать.
К счастью, все будет заботиться о структуре.
Обработка данныхMapReduce основана на этой концепции разделения входных данных. Количество входных разбиений, рассчитанных для конкретного приложения, определяет количество задач сопоставления.
Количество карт обычно определяется количеством блоков DFS во входных файлах.
Каждая из этих задач сопоставления назначается, где это возможно, подчиненному узлу, где хранится разделение ввода. Диспетчер ресурсов (или JobTracker, если вы находитесь в Hadoop 1) делает все возможное, чтобы гарантировать, что входные разбиения обрабатываются локально.
Если локальность данных не может быть достигнута из-за разделения входов, пересекающего границы узлов данных, некоторые данные будут перенесены из одного узла данных в другой узел данных.
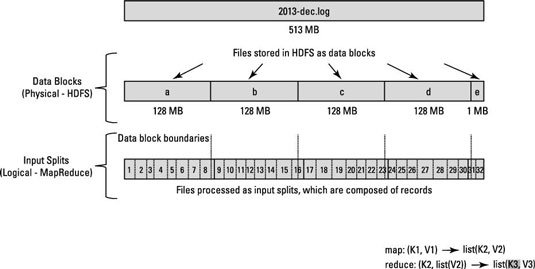
Предположим, что есть блок 128 МБ и последняя запись не уместилась в блоке a и распространяется в блоке b, тогда данные в блоке b будут скопированы на узел, имеющий блок a
Посмотрите на эту диаграмму.
Посмотрите на похожие вопросы
Я думаю, что Дипак спрашивал больше о том, как определяется вход для каждого вызова функции карты, а не о данных, присутствующих на каждом узле карты. Я говорю это, основываясь на второй части вопроса:более конкретно, каждый раз, когда вызывается функция map(), каковы ее параметры Key key и Value val?
На самом деле, тот же вопрос привел меня сюда, и если бы я был опытным разработчиком Hadoop, я мог бы интерпретировать его как ответы выше.
Чтобы ответить на вопрос,
файл в данном узле карты разделяется на основе значения, которое мы установили для InputFormat. (это делается в Java с помощью setInputFormat ()!)
Пример:
conf.setInputFormat (TextInputFormat.class); Здесь, передавая TextInputFormat в функцию setInputFormat, мы сообщаем hadoop обрабатывать каждую строку входного файла в узле карты как входные данные для функции карты. Перевод строки или возврат каретки используются для обозначения конца строки. больше информации на TextInputFormat!
В этом примере: ключи - это позиция в файле, а значения - строка текста.
Надеюсь это поможет.
Для лучшего понимания того, как InputSplits работает в hadoop, я бы рекомендовал прочитать статью, написанную hadoop для чайников. Это действительно полезно.
Разница между размером блока и входным разделением.
Разделение ввода - это логическое разделение ваших данных, в основном используемое при обработке данных в программе MapReduce или других методах обработки. Размер входного разделения - это пользовательское значение, и Hadoop Developer может выбрать размер разделения в зависимости от размера данных (объем обрабатываемых данных).
Input Split в основном используется для управления количеством Mapper в программе MapReduce. Если вы не определили размер разделения ввода в программе MapReduce, то разделение блоков HDFS по умолчанию будет рассматриваться как разделение ввода при обработке данных.
Пример:
Предположим, у вас есть файл размером 100 МБ и конфигурация блока HDFS по умолчанию составляет 64 МБ, тогда он будет разделен на 2 части и займет два блока HDFS. Теперь у вас есть программа MapReduce для обработки этих данных, но вы не указали входное разделение, тогда на основе количества блоков (2 блока) будет рассматриваться как входное разделение для обработки MapReduce, и для этого задания будет назначено два преобразователя. Но предположим, что вы указали размер разделения (скажем, 100 МБ) в вашей программе MapReduce, тогда оба блока (2 блока) будут рассматриваться как один разделитель для обработки MapReduce, и для этого задания будет назначен один Mapper.
Теперь предположим, что вы указали размер разделения (скажем, 25 МБ) в своей программе MapReduce, тогда для программы MapReduce будет 4 входных разделения, и для задания будет назначено 4 Mapper.
Заключение:
- Разделение ввода - это логическое разделение входных данных, в то время как блок HDFS - это физическое разделение данных.
- Размер блока HDFS по умолчанию - это размер разделения по умолчанию, если входное разделение не указано в коде.
- Разделение определяется пользователем, и пользователь может контролировать размер разделения в своей программе MapReduce.
- Одно разделение может быть сопоставлено нескольким блокам, и может быть несколько разделений одного блока.
- Количество задач карты (Mapper) равно количеству входных разбиений.
Источник: https://hadoopjournal.wordpress.com/2015/06/30/mapreduce-input-split-versus-hdfs-blocks/
FileInputFormat - это абстрактный класс, который определяет, как входные файлы читаются и выводятся. FileInputFormat предоставляет следующие функциональные возможности: 1. выбрать файлы / объекты, которые должны использоваться в качестве входных данных 2. определяет входные разделы, которые разбивают файл на задачу.
Согласно базовой функциональности hadoopp, если n разделений, то будет n mapper.
Когда запускается задание Hadoop, он разбивает входные файлы на куски и присваивает каждое разбиение мапперу для обработки; это называется InputSplit.
Существует отдельная задача сокращения карты, которая разбивает файлы на блоки. Используйте FileInputFormat для больших файлов и CombineFileInput Format для маленьких. Вы также можете проверить, можно ли разделить ввод на блоки методом issplittable. Каждый блок затем подается на узел данных, где карта сокращает количество выполненных заданий для дальнейшего анализа. размер блока будет зависеть от размера, который вы упомянули в параметре mapred.max.split.size.
FileInputFormat.addInputPath(job, new Path(args[ 0])); или же
conf.setInputFormat(TextInputFormat.class);
Функция FileInputFormat класса addInputPath,setInputFormat заботится о входных данных, также этот код определяет количество создаваемых картографов. Можно сказать, что inputslit и число картографов прямо пропорциональны количеству блоков, используемых для хранения входного файла в HDFS.
Ex. если у нас есть входной файл размером 74 МБ, этот файл хранится в HDFS в двух блоках (64 МБ и 10 МБ). поэтому для этого файла inputslit используется два и два экземпляра mapper для чтения этого входного файла.
Краткий ответ - InputFormat заботится о разделении файла.
Я подхожу к этому вопросу, посмотрев на его класс TextInputFormat по умолчанию:
Все классы InputFormat являются подклассами FileInputFormat, которые обеспечивают разделение.
В частности, функция getSplit в FileInputFormat генерирует список InputSplit из списка файлов, определенных в JobContext. Разделение основано на размере байтов, минимальные и максимальные значения которых могут быть произвольно определены в файле проекта XML.