Как создать категориальный пузырьковый сюжет в Python?
Нужна помощь в создании сюжета, похожего на этот в этой ссылке, просто с использованием библиотеки Python.
Catagorical Bubble Chart с использованием ggplot2 в R: смотрите ответ с наибольшим количеством голосов.
Здесь я позаимствовал данные по ссылке:
df = pd.DataFrame({'Var1':['Does.Not.apply',
'Not.specified',
'Active.Learning..general.',
'Problem.based.Learning',
'Project.Method',
'Case.based.Learning',
'Peer.Learning',
'Other',
'Does.Not.apply',
'Not.specified',
'Does.Not.apply',
'Active.Learning..general.',
'Does.Not.apply',
'Problem.based.Learning',
'Does.Not.apply',
'Project.Method',
'Does.Not.apply',
'Case.based.Learning',
'Does.Not.apply',
'Peer.Learning',
'Does.Not.apply',
'Other'],
'Var2':['Does.Not.apply',
'Does.Not.apply',
'Does.Not.apply',
'Does.Not.apply',
'Does.Not.apply',
'Does.Not.apply',
'Does.Not.apply',
'Does.Not.apply',
'Not.specified',
'Not.specified',
'Active.Learning..general.',
'Active.Learning..general.',
'Problem.based.Learning',
'Problem.based.Learning',
'Project.Method',
'Project.Method',
'Case.based.Learning',
'Case.based.Learning',
'Peer.Learning',
'Peer.Learning',
'Other',
'Other'],
'Count' : [53,15,1,2,4,22,6,1,15,15,1,1,2,2,4,4,22,22,6,6,1,1]})
3 ответа
Plotnine - грамматика реализации графического Python, основанная на ggplot2.
Код в значительной степени идентичен коду в вашей R-ссылке.
import math
import pandas as pd
from plotnine import *
df = pd.DataFrame(<dataframe data here>)
df['dotsize'] = df.apply(lambda row: math.sqrt(float(row.Count) / math.pi)*7.5, axis=1)
(ggplot(df, aes('Var1', 'Var2')) + \
geom_point(aes(size='dotsize'),fill='white') + \
geom_text(aes(label='Count'),size=8) + \
scale_size_identity() + \
theme(panel_grid_major=element_line(linetype='dashed',color='black'),
axis_text_x=element_text(angle=90,hjust=1,vjust=0))
).save('mygraph.png')
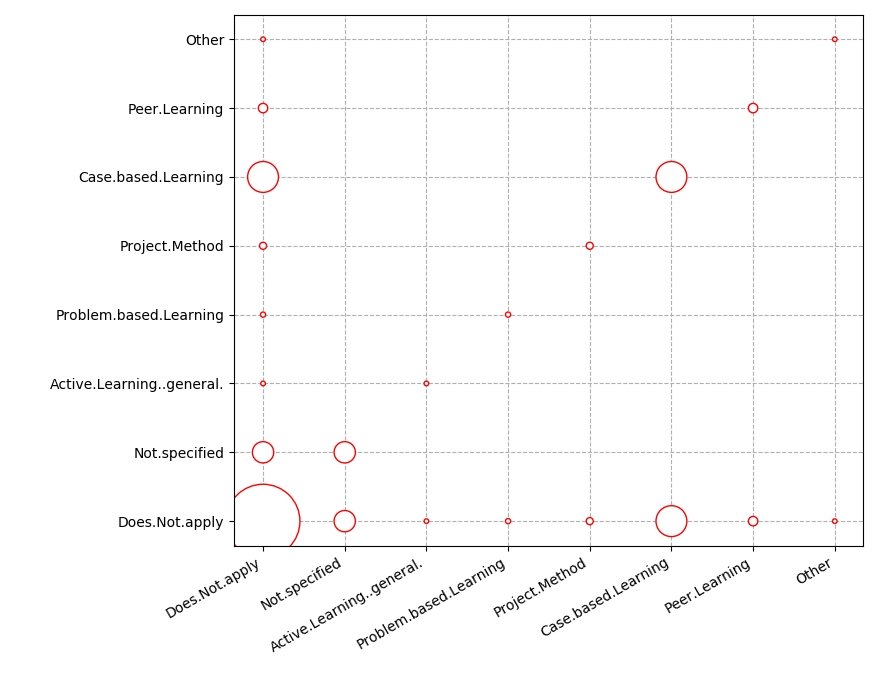
Родной Python matplotlib Конечно, можно создать этот вид графика. Это просто категорический график рассеяния с переменными размерами маркеров. Используя ваш игрушечный набор данных:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#create markersize column from values to better see the difference
#you probably want to edit this function depending on min, max, and range of values
df["markersize"] = np.square(df.Count) + 10
fig = plt.figure()
#plot categorical scatter plot
plt.scatter(df.Var1, df.Var2, s = df.markersize, edgecolors = "red", c = "white", zorder = 2)
#plot grid behind markers
plt.grid(ls = "--", zorder = 1)
#take care of long labels
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
Выход:
Что касается определения вашей функции размера маркера для точечной диаграммы, вы можете прочитать этот ответ.
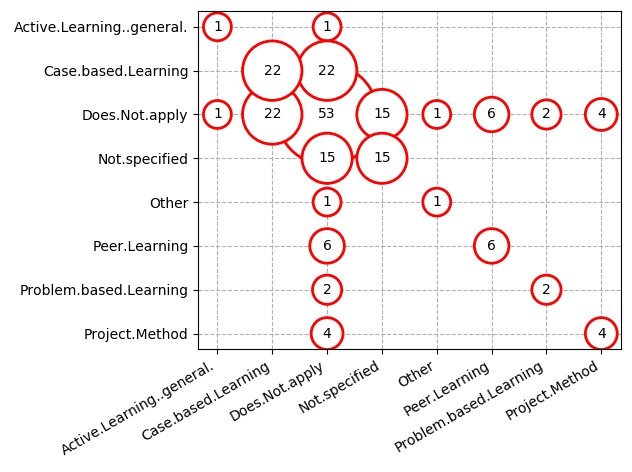
Еще один способ решения этой проблемы - построить аннотацию со значением и кружком вокруг него в каждой категориальной точке:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
#create padding column from values for circles that are neither too small nor too large
df["padd"] = 2.5 * (df.Count - df.Count.min()) / (df.Count.max() - df.Count.min()) + 0.5
fig = plt.figure()
#prepare the axes for the plot - you can also order your categories at this step
s = plt.scatter(sorted(df.Var1.unique()), sorted(df.Var2.unique(), reverse = True), s = 0)
s.remove
#plot data row-wise as text with circle radius according to Count
for row in df.itertuples():
bbox_props = dict(boxstyle = "circle, pad = {}".format(row.padd), fc = "w", ec = "r", lw = 2)
plt.annotate(str(row.Count), xy = (row.Var1, row.Var2), bbox = bbox_props, ha="center", va="center", zorder = 2, clip_on = True)
#plot grid behind markers
plt.grid(ls = "--", zorder = 1)
#take care of long labels
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
Образец вывода:
Престижность DavidG, который показал мне в этом ответе, как предотвратить, чтобы аннотация печаталась вне графика.