Когда нецелесообразно использовать persist() для фрейма данных искры?
Работая над улучшением производительности кода, так как у меня было много неудачных заданий (прервано), я подумал об использовании persist() функция на Spark Dataframe всякий раз, когда мне нужно использовать тот же самый dataframe для многих других операций. Делая это и следуя заданиям, этапам в интерфейсе приложения Spark, я чувствовал, что это не всегда оптимально, это зависит от количества разделов и размера данных. Я не был уверен, пока не получил работу, прерванную из-за сбоя на этапе упорства.
Я спрашиваю, если лучшая практика использования persist() всякий раз, когда будет выполняться много операций над фреймом данных, всегда действует? Если нет, то когда это не так? как судить?
Чтобы быть более конкретным, я представлю свой код и детали прерванной работы:
#create a dataframe from another one df_transf_1 on which I made a lot of transformations but no actions
spark_df = df_transf_1.select('user_id', 'product_id').dropDuplicates()
#persist
spark_df.persist()
products_df = spark_df[['product_id']].distinct()
df_products_indexed = products_df.rdd.map(lambda r: r.product_id).zipWithIndex().toDF(['product_id', 'product_index'])
Вы можете спросить, почему я упорствовал spark_df? Это потому, что я собираюсь использовать его несколько раз, как с products_df а также в joins (например: spark_df = spark_df.join(df_products_indexed,"product_id")
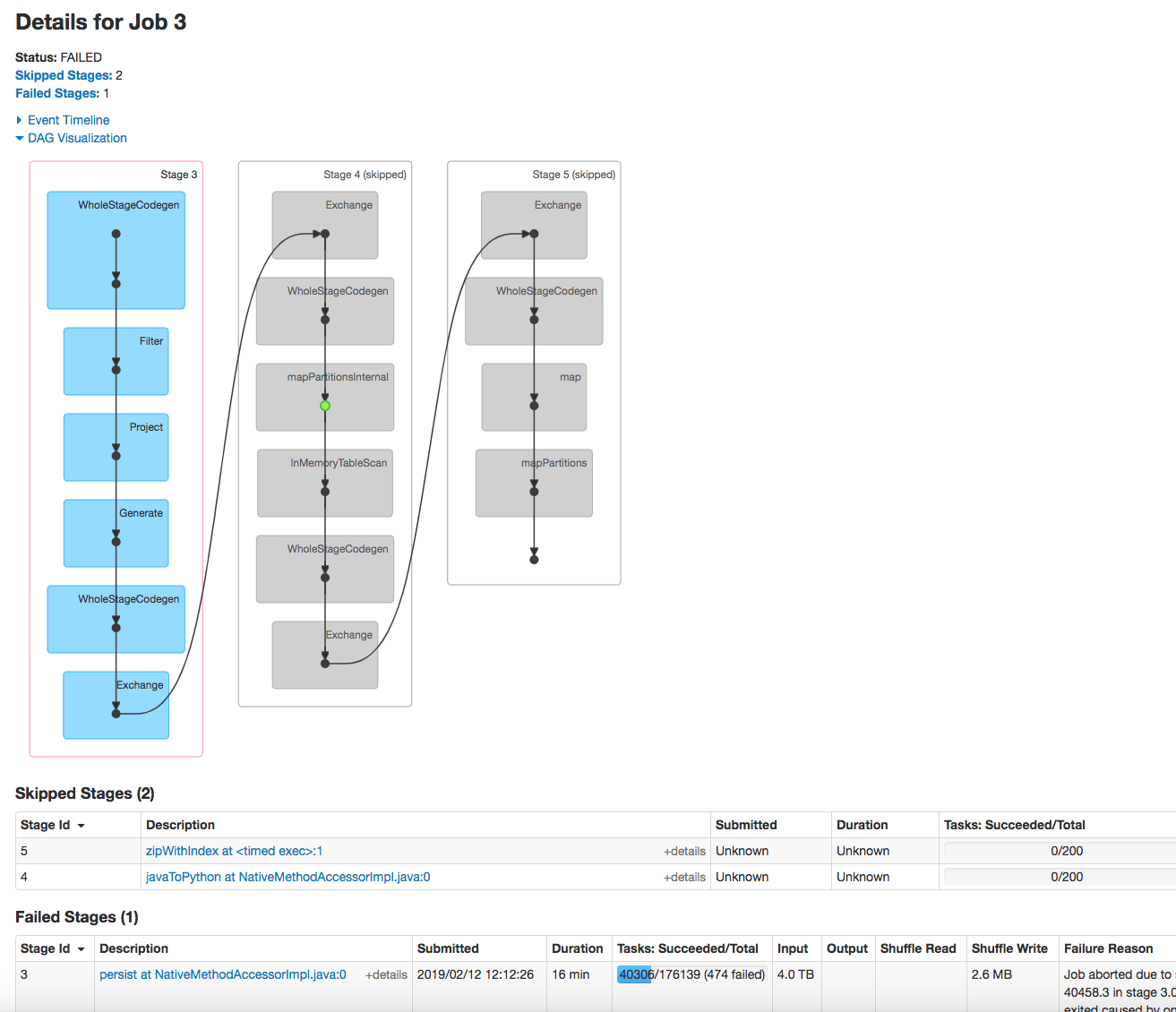
Подробная информация о причине отказа на этапе 3:
Задание прервано из-за сбоя этапа: сбой задачи 40458 на этапе 3.0, последний сбой: сбой задачи 40458.3 на этапе 3.0 (TID 60778, xx.xx.yyyy.com, executor 91): ExecutorLostFailure (выход executor 91 вызван одним из запущенных задач) Причина: ведомый потерял трассировку стека драйверов:
Размер входных данных (4 ТБ) огромен, перед тем как продолжить, есть ли способ проверить размер данных? Это параметр при выборе сохранения или нет? Также количество разделов (заданий) для persist > 100000
0 ответов
Вот два случая использования persist():
После использования
repartitionво избежание перетасовки ваших данных снова и снова, поскольку кадр данных используется на следующих шагах. Это будет полезно только в том случае, если вы вызываете более одного действия для постоянного кадра данных / СДР, поскольку постоянное является преобразованием и, следовательно, лениво оценивается. В общем, если у вас есть несколько действий на одном кадре данных /RDD.Итерационные вычисления, например, когда вы хотите запросить фрейм данных внутри цикла for. С
persistSpark сохранит промежуточные результаты и пропустит повторную оценку одних и тех же операций при каждом вызове действия. Другим примером будет добавление новых столбцов сjoinкак обсуждено здесь.
Мой опыт научил меня тому, что вы должны сохранять фрейм данных, когда выполняете над ними несколько операций, поэтому вы создаете временные таблицы (также вы гарантируете, что в случае сбоя у вас будет точка восстановления). Этим вы предотвращаете огромные DAG'ы, которые часто не заканчиваются, если у вас есть, например, объединения. Так что мой совет будет сделать что-то вроде этого:
# operations
df.write.saveAsTable('database.tablename_temp')
df = spark.table('database.tablename_temp')
# more operations