Определить таблицу с помощью OpenCV
Я часто работаю с отсканированными бумагами. Бумаги содержат таблицы (похожие на таблицы Excel), которые мне нужно набирать на компьютере вручную. Чтобы сделать задачу еще хуже, таблицы могут иметь разное количество столбцов. Вводить их вручную в Excel, по меньшей мере, обыденно.
Я думал, что смогу сэкономить себе неделю работы, если смогу поставить программу на OCR это. Можно ли было бы обнаружить текстовые области заголовков с помощью OpenCV и OCR текста за обнаруженными координатами изображения.
Могу ли я добиться этого с помощью OpenCV или мне нужен совершенно другой подход?
Изменить: Пример таблицы на самом деле просто стандартная таблица, похожая на то, что вы можете увидеть в Excel и других электронных таблицах, см. Ниже.
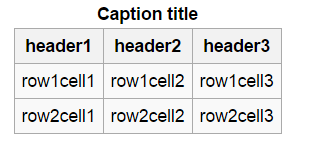
1 ответ
Этот вопрос кажется немного старым, но я также работал над аналогичной проблемой и получил свое собственное решение, которое я объясняю здесь.
Для чтения текста с использованием любого механизма распознавания существует много проблем в получении хорошей точности, которые включают в себя следующие основные случаи:
Наличие шума из-за плохого качества изображения / нежелательных элементов / пятен в области фона. Это потребует некоторой предварительной обработки, такой как удаление шума, которая может быть легко выполнена с использованием методов гауссовского фильтра или обычного медианного фильтра. Они также доступны в opencv.
Неправильная ориентация изображения: из-за неправильной ориентации механизм распознавания не может правильно сегментировать строки и слова на изображении, что дает наихудшую точность.
- Присутствие строк: при выполнении сегментации слов или строк механизм OCR иногда также пытается объединить слова и строки вместе, обрабатывая, таким образом, неверный контент и, следовательно, давая неправильные результаты. Есть и другие проблемы, но они являются основными.
В этом случае я думаю, что качество сканированного изображения достаточно хорошее и простое, и для решения проблемы могут быть использованы следующие шаги.
- Простая бинаризация изображения удалит фоновый контент, оставляя только необходимый контент, как показано здесь.

Теперь мы должны удалить линии, которые в данном случае являются табличными сетками. Это также можно определить с помощью подключенных компонентов и удаления крупных подключенных компонентов. Таким образом, наше окончательное изображение, которое необходимо передать в механизм распознавания, будет выглядеть следующим образом.
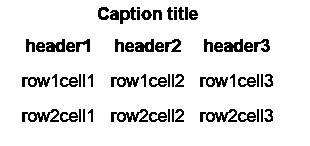
Для распознавания текста мы можем использовать Tesseract Open Source OCR Engine. Я получил следующие результаты от OCR:
Заголовок заголовка
заголовок! header2 header3
row1cell1 row1cell2 row1cell3
row2cell1 row2cell2 row2cell3
Как мы видим здесь, этот результат довольно точен, но есть некоторые проблемы, такие как заголовок! это должен быть header1, это потому, что механизм OCR неправильно понят! с 1. Эта проблема может быть решена путем дальнейшей обработки результата с использованием операций на основе регулярных выражений.
После постобработки результата OCR его можно проанализировать, чтобы прочитать значения строк и столбцов.
Также здесь в этом случае для классификации заголовка листа, заголовка и нормальных значений ячеек можно использовать информацию о шрифте.