Потеря схемы с помощью соединителя потоковой передачи ApacheBahir на потоке ApacheSpark
Я пытаюсь подключить структурированный поток ApacheSpark к теме MQTT (в данном случае платформа IBM Watson IoT на IBM Bluemix).
Я создаю структурированный поток следующим образом:
val df = spark.readStream
.format("org.apache.bahir.sql.streaming.mqtt.MQTTStreamSourceProvider")
.option("username","a-vy0z2s-q6s8r693hv")
.option("password","B+UX(aWuFPvX")
.option("clientId","a:vy0z2s:a-vy0z2s-zfzzckrnqf")
.option("topic", "iot-2/type/WashingMachine/id/Washer02/evt/voltage/fmt/json")
.load("tcp://vy0z2s.messaging.internetofthings.ibmcloud.com:1883")
Пока все хорошо, в REPL я возвращаю этот объект df следующим образом:
df: org.apache.spark.sql.DataFrame = [значение: строка, отметка времени: отметка времени]
Из этой ветки я узнал, что мне нужно менять идентификатор клиента при каждом подключении. Так что это решено, но если я начну читать из потока, используя эту строку:
val query = df.writeStream. outputMode ("добавить").
формат ("консоль"). начать ()
Тогда результирующая схема выглядит так:
df: org.apache.spark.sql.DataFrame = [значение: строка, отметка времени: отметка времени]
И данные таковы:
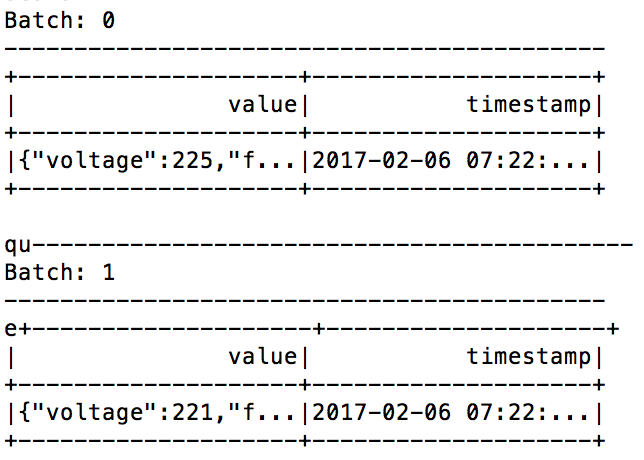
Это означает, что мой поток JSON преобразуется в поток строкового объекта, содержащего представление JSON.
Это ограничение ApacheBahir?
Также не помогает предоставление схемы, поскольку следующий код похож на тот же результат:
import org.apache.spark.sql.types._
val schema = StructType(
StructField("count",LongType,true)::
StructField("flowrate",LongType,true)::
StructField("fluidlevel",StringType,true)::
StructField("frequency",LongType,true)::
StructField("hardness",LongType,true)::
StructField("speed",LongType,true)::
StructField("temperature",LongType,true)::
StructField("ts",LongType,true)::
StructField("voltage",LongType,true)::
Nil)
:paste
val df = spark.readStream
.schema(schema)
.format("org.apache.bahir.sql.streaming.mqtt.MQTTStreamSourceProvider")
.option("username","a-vy0z2s-q6s8r693hv")
.option("password","B+UX(a8GFPvX")
.option("clientId","a:vy0z2s:a-vy0z2s-zfzzckrnqf4")
.option("topic", "iot-2/type/WashingMachine/id/Washer02/evt/voltage/fmt/json")
.load("tcp://vy0z2s.messaging.internetofthings.ibmcloud.com:1883")
2 ответа
Много DataSources включая, но не ограничиваясь MQTTStreamSource, имеют фиксированную схему, состоящую из сообщения и отметки времени. Схема не теряется, просто не анализируется, и это ожидаемое поведение.
Если схема фиксирована и известна заранее, вы сможете использовать from_json функция:
import org.apache.spark.sql.functions.from_json
df.withColumn("value", from_json($"value", schema))
Для синтаксического анализа (поскольку я больше не использую метод "from_json") я использовал
import org.apache.spark.sql.functions.json_tuple
и следующий код, он также работает:
df.withColumn ("значение",json_tuple($"значение","myColumnName"))