Используйте Regex для разбиения массива нумерованного списка на многострочный нумерованный список
Я пытаюсь научить Regex отвечать на вопрос о португальском СО.
Ввод (массив или строка в ячейке, так .MultiLine = False)?
1 One without dot. 2. Some Random String. 3.1 With SubItens. 3.2 With number 0n mid. 4. Number 9 incorrect. 11.12 More than one digit. 12.7 Ending (no word).
Выход
1 One without dot.
2. Some Random String.
3.1 With SubItens.
3.2 With number 0n mid.
4. Number 9 incorrect.
11.12 More than one digit.
12.7 Ending (no word).
Я думал использовать Regex с Split, но я не смог реализовать пример в Excel.
Imports System.Text.RegularExpressions
Module Example
Public Sub Main()
Dim input As String = "plum-pear"
Dim pattern As String = "(-)"
Dim substrings() As String = Regex.Split(input, pattern) ' Split on hyphens.
For Each match As String In substrings
Console.WriteLine("'{0}'", match)
Next
End Sub
End Module
' The method writes the following to the console:
' 'plum'
' '-'
' 'pear'
Так что читая это и это. Сайт RegExr использовался с выражением /([0-9]{1,2})([.]{0,1})([0-9]{0,2})/igm на входе.
И получается следующее:

Есть ли лучший способ сделать это? Правильно ли Regex или лучший способ создания? Примеры, которые я нашел в Google, не рассказывали мне о том, как правильно использовать RegEx с Split.
Может быть, я путаю логику функции разделения, которую я хотел получить индекс разделения, а строка-разделитель была регулярным выражением.
2 ответа
Я могу сделать это заканчивается словом и точкой
использование
\d+(?:\.\d+)*[\s\S]*?\w+\.
Смотрите демо-версию регулярного выражения.
подробности
\d+- 1 или более цифр(?:\.\d+)*- ноль или более последовательностей:\.- точка\d+- 1 или более цифр
[\s\S]*?- любые 0+ символов, как можно меньше, вплоть до первого...\w+\.- 1+ слов с последующими символами.,
Вот пример кода VBA:
Dim str As String
Dim objMatches As Object
str = " 1 One without dot. 2. Some Random String. 3.1 With SubItens. 3.2 With Another SubItem. 4. List item. 11.12 More than one digit."
Set objRegExp = New regexp ' CreateObject("VBScript.RegExp")
objRegExp.Pattern = "\d+(?:\.\d+)*[\s\S]*?\w+\."
objRegExp.Global = True
Set objMatches = objRegExp.Execute(str)
If objMatches.Count <> 0 Then
For Each m In objMatches
Debug.Print m.Value
Next
End If
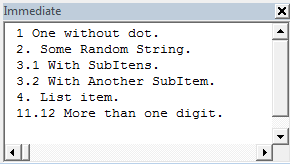
НОТА
Вы можете требовать, чтобы совпадения останавливались только на слове + . которые сопровождаются 0+ пробелами и числом, используя \d+(?:\.\d+)*[\s\S]*?[a-zA-Z]+\.(?=\s*(?:\d+|$)),
(?=\s*(?:\d+|$)) положительный прогноз требует наличия пробелов 0+ (\s*) с 1+ цифрами (\d+) или конец строки ($) сразу справа от текущего местоположения.
Если разделение VBA поддерживает регулярное выражение, то это может сработать, при условии, что в индексах нет цифр, кроме индексов:
\s(?=\d)