Установить пропущенные значения для нескольких помеченных переменных
Как установить недостающие значения для нескольких помеченных векторов в кадре данных. Я работаю с набором данных опроса от SPSS. Я имею дело примерно с 20 различными переменными, с одинаковыми пропущенными значениями. Поэтому я хотел бы найти способ использовать lapply() для этой работы, но я не могу.
Я на самом деле могу сделать это с помощью базы R с помощью as.numeric() и затем recode(), но я заинтригован возможностями гавани и помеченного класса, поэтому я хотел бы найти способ сделать все это в тидиверсе Хэдли
Примерно представляющие интерес переменные выглядят так. Извините, если это основной вопрос, но я считаю, что справочная документация, связанная с убежищем и помеченными пакетами, очень бесполезна.
library(haven)
library(labelled)
v1<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v2<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v3<-data.frame(v1=v1, v2=v2)
lapply(v3, val_labels)
lapply(v3, function(x) set_na_values(x, c(5,6)))
6 ответов
Хорошо, теперь я понимаю, что ты пытаешься сделать...
т.е. пометить метки и значения как NA, не удаляя основные импортированные данные...
См. Приложение для более подробного примера, который использует общедоступный файл данных, чтобы показать пример, который использует dplyr обновить несколько столбцов, меток...
Предложенное решение
df <- data_frame(s1 = c(1,2,2,2,5,6), s2 = c(1,2,2,2,5,6)) %>%
set_value_labels(s1 = c(agree=1, disagree=2, dk=5, refused=6),
s2 = c(agree=1, disagree=2, dk = tagged_na("5"), refused = tagged_na("6"))) %>%
set_na_values(s2 = c(5,6))
val_labels(df)
is.na(df$s1)
is.na(df$s2)
df
Результат решения:
> library(haven)
> library(labelled)
> library(dplyr)
> df <- data_frame(s1 = c(1,2,2,2,5,6), s2 = c(1,2,2,2,5,6)) %>%
+ set_value_labels(s1 = c(agree=1, disagree=2, dk=5, refused=6),
+ s2 = c(agree=1, disagree=2, dk = tagged_na("5"), refused = tagged_na("6"))) %>%
+ set_na_values(s2 = c(5,6))
> val_labels(df)
$s1
agree disagree dk refused
1 2 5 6
$s2
agree disagree dk refused
1 2 NA NA
> is.na(df$s1)
[1] FALSE FALSE FALSE FALSE FALSE FALSE
> is.na(df$s2)
[1] FALSE FALSE FALSE FALSE TRUE TRUE
> df
# A tibble: 6 × 2
s1 s2
<dbl+lbl> <dbl+lbl>
1 1 1
2 2 2
3 2 2
4 2 2
5 5 5
6 6 6
Теперь мы можем манипулировать данными
mean(df$s1, na.rm = TRUE)
mean(df$s2, na.rm = TRUE)
> mean(df$s1, na.rm = TRUE)
[1] 3
> mean(df$s2, na.rm = TRUE)
[1] 1.75
Используйте пакет с метками, чтобы удалить метки и заменить на R NA
Если вы хотите удалить метки и заменить их значениями R NA, вы можете использовать remove_labels(x, user_na_to_na = TRUE)
Пример:
df <- remove_labels(df, user_na_to_na = TRUE)
df
Результат:
> df <- remove_labels(df, user_na_to_na = TRUE)
> df
# A tibble: 6 × 2
s1 s2
<dbl> <dbl>
1 1 1
2 2 2
3 2 2
4 2 2
5 5 NA
6 6 NA
-
Объяснение / Обзор формата SPSS:
IBM SPSS (Приложение) может импортировать и экспортировать данные во многих форматах и в непрямоугольных конфигурациях; однако набор данных всегда транслируется в прямоугольный файл данных SPSS, известный как системный файл (с расширением *.sav). Метаданные (информация о данных), такие как форматы переменных, пропущенные значения и метки переменных и значений, хранятся вместе с набором данных.
Ярлыки значения
База R имеет один тип данных, который эффективно поддерживает отображение между целыми числами и символьными метками: фактор. Это, однако, не является основным использованием факторов: вместо этого они предназначены для автоматического создания полезных контрастов для линейных моделей. Факторы отличаются от обозначенных значений, предоставляемых другими инструментами, в важных отношениях:
SPSS и SAS могут маркировать числовые и символьные значения, а не только целочисленные значения.
Недостающие ценности
Все три инструмента (SPSS, SAS, Strata) предоставляют глобальное "системное пропущенное значение", которое отображается как ., Это примерно эквивалентно R NA, хотя ни Stata, ни SAS не распространяют отсутствие в числовых сравнениях: SAS рассматривает пропущенное значение как наименьшее возможное число (т. е. -inf), а Stata рассматривает его как наибольшее возможное число (т. е. inf).
Каждый инструмент также предоставляет механизм для записи нескольких типов пропусков:
- Stata "расширил" пропущенные значения, от.A до.Z.
- SAS имеет "специальные" пропущенные значения, от.A до.Z плюс._.
- SPSS имеет пропущенные значения для каждого пользователя в столбце. Каждый столбец может объявлять до трех различных значений или диапазон значений (плюс одно отдельное значение), которые следует рассматривать как пропущенные.
Определяемые пользователем пропущенные значения
Пользовательские значения SPSS работают иначе, чем SAS и Stata. Каждый столбец может иметь до трех различных значений, которые считаются пропущенными, или диапазон. Haven обеспечивает labelled_spss() как подкласс labelled() моделировать эти дополнительные определяемые пользователем пропуски.
x1 <- labelled_spss(c(1:10, 99), c(Missing = 99), na_value = 99)
x2 <- labelled_spss(c(1:10, 99), c(Missing = 99), na_range = c(90, Inf))
x1
#> <Labelled SPSS double>
#> [1] 1 2 3 4 5 6 7 8 9 10 99
#> Missing values: 99
#>
#> Labels:
#> value label
#> 99 Missing
x2
#> <Labelled SPSS double>
#> [1] 1 2 3 4 5 6 7 8 9 10 99
#> Missing range: [90, Inf]
#>
#> Labels:
#> value label
#> 99 Missing
Помеченные пропущенные значения
Чтобы поддерживать расширенное значение Stata и специальное пропущенное значение SAS, в хэне реализован теговый NA. Это достигается за счет использования внутренней структуры NA с плавающей запятой. Это позволяет этим значениям вести себя идентично NA в обычных операциях R, при этом сохраняя значение тега.
Интерфейс R для создания с тегами NA Это немного неуклюже, потому что обычно они создаются для вас. Но вы можете создать свой собственный с tagged_na():
Важный:
Обратите внимание, что эти помеченные NA ведут себя так же, как и обычные NA, даже при печати. Чтобы увидеть их теги, используйте print_tagged_na():
Таким образом:
library(haven)
library(labelled)
v1<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v2<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=tagged_na("5"), refused= tagged_na("6")))
v3<-data.frame(v1 = v1, v2 = v2)
v3
lapply(v3, val_labels)
> v3
x x.1
1 1 1
2 2 2
3 2 2
4 2 2
5 5 5
6 6 6
> lapply(v3, val_labels)
$x
agree disagree dk refused
1 2 5 6
$x.1
agree disagree dk refused
1 2 NA NA
Слово предостережения:
Пользовательские значения SPSS работают иначе, чем SAS и Stata. Каждый столбец может иметь до трех различных значений, которые считаются пропущенными, или диапазон. Хейвен обеспечивает labelled_spss() в качестве подкласса метки () для моделирования этих дополнительных пользовательских пропущений.
Я надеюсь, что выше помогает
Береги Т.
Рекомендации:
- https://cran.r-project.org/web/packages/haven/haven.pdf
- https://cran.r-project.org/web/packages/haven/vignettes/semantics.html
- https://www.spss-tutorials.com/spss-missing-values-tutorial/
Пример приложения с использованием общедоступных данных...
Пример пропущенных значений SPSS с использованием файла данных SPPS { hospital.sav }
Во-первых, давайте удостоверимся, что
- Системные пропущенные значения - это значения, которые полностью отсутствуют в данных
- Пользовательские пропущенные значения - это значения, которые присутствуют в данных, но должны быть исключены из расчетов.
SPSS Просмотр данных...
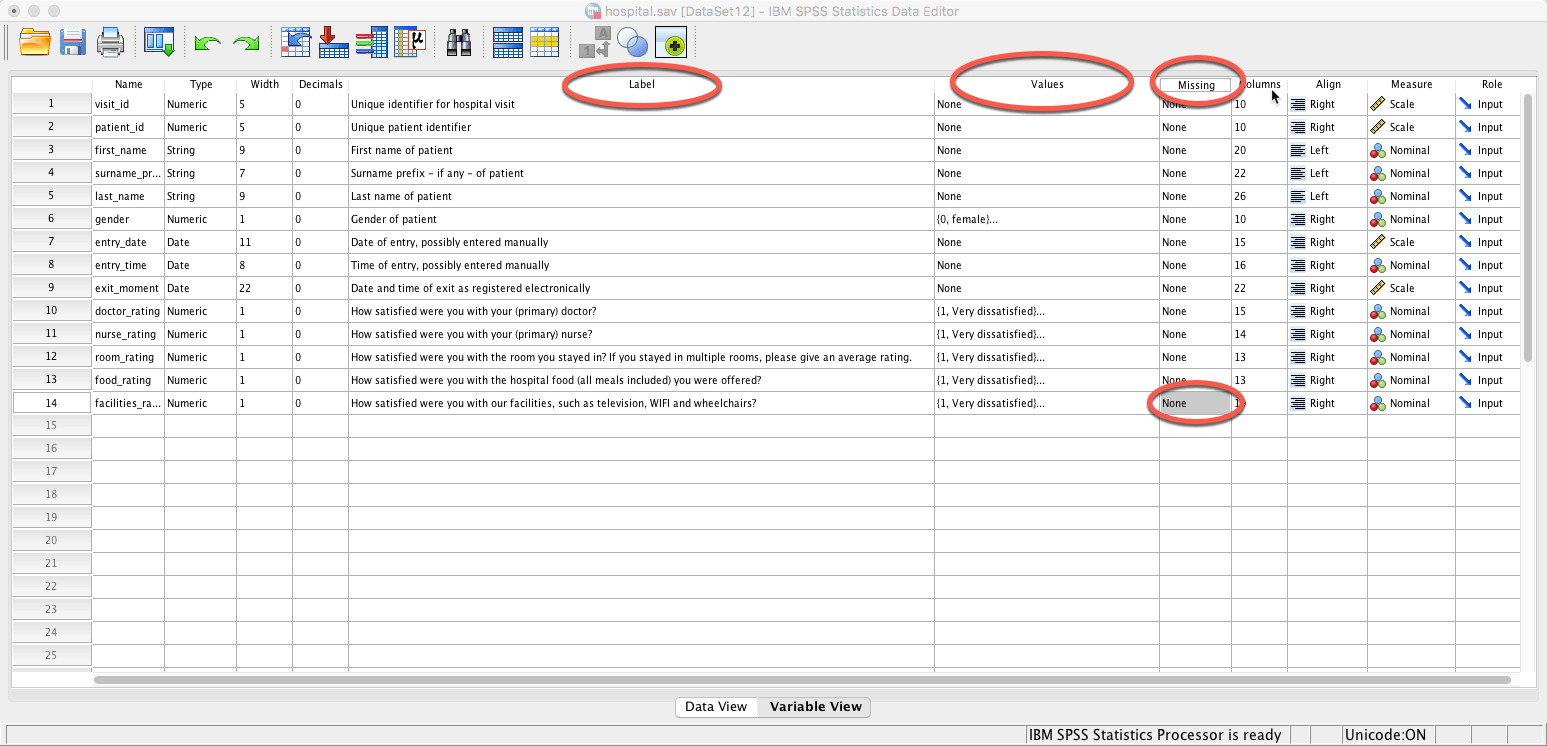
Давайте рассмотрим изображение и данные... Данные SPSS, показанные в представлении переменных, показывают, что каждая строка имеет метку [Column5], мы отмечаем, что строки 10-14 имеют определенные значения, приписанные им [1..6] [Столбец 6], которые имеют атрибуты имени и что значения не указаны как отсутствующие [столбец 7].
Теперь давайте посмотрим на представление данных SPSS:
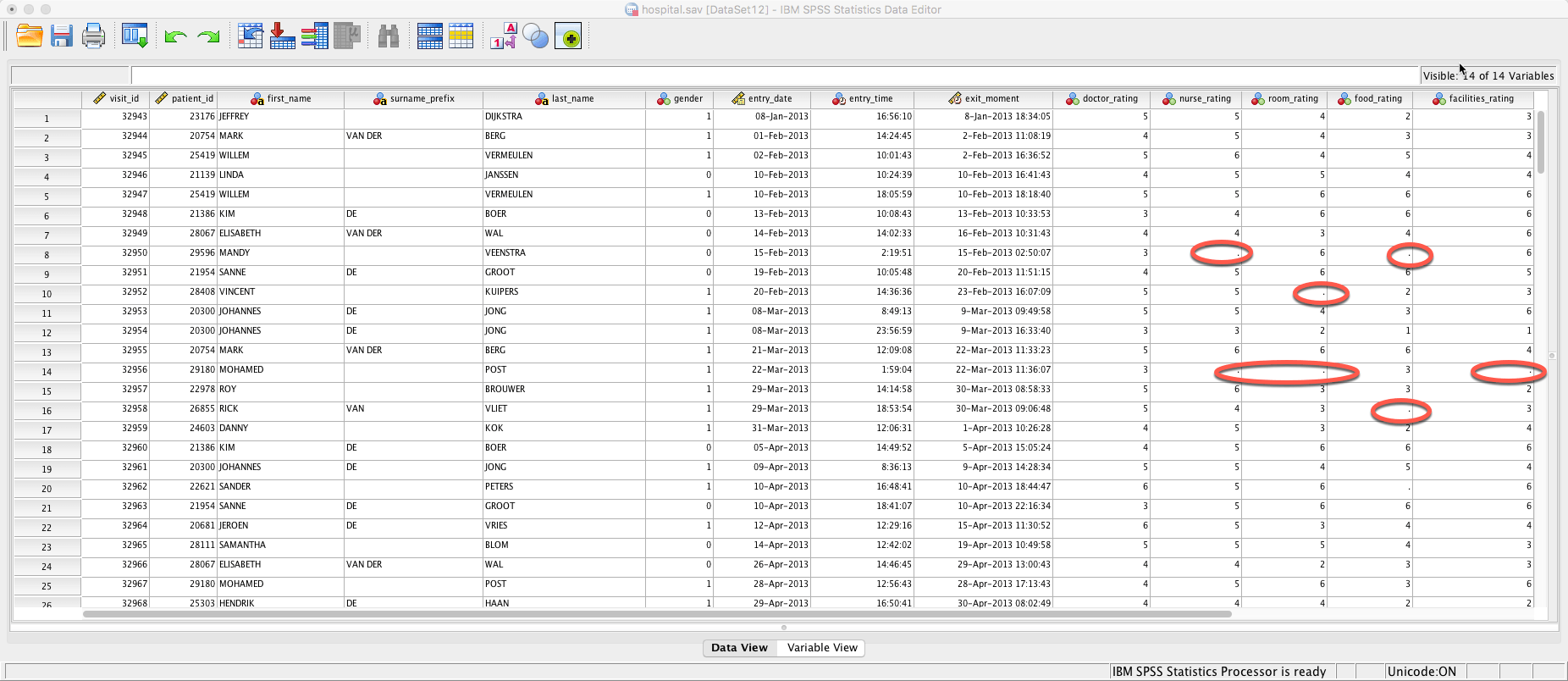
Здесь мы можем заметить, что отсутствуют данные... (см. "."). Ключевым моментом является то, что у нас отсутствуют данные, но в настоящее время нет "отсутствующих значений пользователя"
Теперь давайте обратимся к R и загрузим данные в R
hospital_url <- "https://www.spss-tutorials.com/downloads/hospital.sav"
hospital <- read_sav(hospital_url,
user_na = FALSE)
head(hospital,5)
# We're interested in columns 10 through 14...
head(hospital[10:14],5)
Результат
> hospital_url <- "https://www.spss-tutorials.com/downloads/hospital.sav"
> hospital <- read_sav(hospital_url,
+ user_na = FALSE)
> head(hospital,5)
# A tibble: 5 × 14
visit_id patient_id first_name surname_prefix last_name gender entry_date entry_time
<dbl> <dbl> <chr> <chr> <chr> <dbl+lbl> <date> <time>
1 32943 23176 JEFFREY DIJKSTRA 1 2013-01-08 16:56:10
2 32944 20754 MARK VAN DER BERG 1 2013-02-01 14:24:45
3 32945 25419 WILLEM VERMEULEN 1 2013-02-02 10:01:43
4 32946 21139 LINDA JANSSEN 0 2013-02-10 10:24:39
5 32947 25419 WILLEM VERMEULEN 1 2013-02-10 18:05:59
# ... with 6 more variables: exit_moment <dttm>, doctor_rating <dbl+lbl>, nurse_rating <dbl+lbl>,
# room_rating <dbl+lbl>, food_rating <dbl+lbl>, facilities_rating <dbl+lbl>
Столбцы с 10 по 14 содержат значения
1="Very Dissatisfied"
2="Dissatisfied"
3="Neutral"
4="Satisfied"
5="Very Satisfied"
6="Not applicable or don't want to answer"
таким образом:
> head(hospital[10:14],5)
# A tibble: 5 × 5
doctor_rating nurse_rating room_rating food_rating facilities_rating
<dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl>
1 5 5 4 2 3
2 4 5 4 3 3
3 5 6 4 5 4
4 4 5 5 4 4
5 5 5 6 6 6
SPSS Value Labels
> lapply(hospital[10], val_labels)
$doctor_rating
Very dissatisfied Dissatisfied
1 2
Neutral Satisfied
3 4
Very satisfied Not applicable or don't want to answer
5 6
хорошо, обратите внимание, что выше мы можем подтвердить, что мы импортировали метки значений.
Удалить неприменимые данные из данных опроса
Наша цель - удалить записи данных "Не применимо или не хотите отвечать", установив для них "Пользовательские значения NA", то есть пропущенное значение SPSS.
Решение - Шаг 1 - Один столбец
Мы хотим установить атрибут отсутствующего значения в нескольких столбцах данных... Давайте сначала сделаем это для одного столбца...
Обратите внимание, мы используем add_value_labels не set_value_labels поскольку мы хотим добавить новую метку, не полностью перезаписать существующие метки...
d <- hospital
mean(d$doctor_rating, na.rm = TRUE)
d <- hospital %>%
add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
= tagged_na("6") )) %>%
set_na_values(doctor_rating = 5)
val_labels(d$doctor_rating)
mean(d$doctor_rating, na.rm = TRUE)
> d <- hospital
> mean(d$doctor_rating, na.rm = TRUE)
[1] 4.322368
> d <- hospital %>%
+ add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
+ = tagged_na("6") )) %>%
+ set_na_values(doctor_rating = 6)
> val_labels(d$doctor_rating)
Very dissatisfied Dissatisfied
1 2
Neutral Satisfied
3 4
Very satisfied Not applicable or don't want to answer
5 6
Not applicable or don't want to answer
NA
> mean(d$doctor_rating, na.rm = TRUE)
[1] 4.097015
Решение - Шаг 2 - Теперь примените к нескольким столбцам...
mean(hospital$nurse_rating)
mean(hospital$nurse_rating, na.rm = TRUE)
d <- hospital %>%
add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
= tagged_na("6") )) %>%
set_na_values(doctor_rating = 6) %>%
add_value_labels( nurse_rating = c( "Not applicable or don't want to answer"
= tagged_na("6") )) %>%
set_na_values(nurse_rating = 6)
mean(d$nurse_rating, na.rm = TRUE)
Результат
Обратите внимание, что nurse_rating содержит значения "NaN" и значения с тегами NA. Первый вызов mean() завершается неудачно, второй завершается успешно, но включает "Не применимо...", после фильтра "Не применимо..." удаляются...
> mean(hospital$nurse_rating)
[1] NaN
> mean(hospital$nurse_rating, na.rm = TRUE)
[1] 4.471429
> d <- hospital %>%
+ add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
+ = tagged_na("6") )) %>%
+ set_na_values(doctor_rating = 6) %>%
+ add_value_labels( nurse_rating = c( "Not applicable or don't want to answer"
+ = tagged_na("6") )) %>%
+ set_na_values(nurse_rating = 6)
> mean(d$nurse_rating, na.rm = TRUE)
[1] 4.341085
Преобразовать помеченные NA в R NA
Здесь мы берем вышеупомянутый тегированный NA и конвертируем в значения R NA.
d <- d %>% remove_labels(user_na_to_na = TRUE)
Не совсем уверен, что это то, что вы ищете:
v1 <- labelled(c(1, 2, 2, 2, 5, 6), c(agree = 1, disagree = 2, dk = 5, refused = 6))
v2 <- labelled(c(1, 2, 2, 2, 5, 6), c(agree = 1, disagree = 2, dk = 5, refused = 6))
v3 <- data_frame(v1 = v1, v2 = v2)
lapply(names(v3), FUN = function(x) {
na_values(v3[[x]]) <<- 5:6
})
lapply(v3, na_values)
Последняя строка возвращается
$v1
[1] 5 6
$v2
[1] 5 6
Проверьте пропущенные значения:
is.na(v3$v1)
[1] FALSE FALSE FALSE FALSE TRUE TRUE
Это правильно?
#Using replace to substitute 5 and 6 in v3 with NA
data.frame(lapply(v3, function(a) replace(x = a, list = a %in% c(5,6), values = NA)))
# x x.1
#1 1 1
#2 2 2
#3 2 2
#4 2 2
#5 NA NA
#6 NA NA
Я знаю, что labelled_spss позволяет вам указать na_range или даже вектор na_values
#DATA
v11 = labelled_spss(x = c(1,2,2,2,5,6),
labels = c(agree=1, disagree=2, dk=5, refused=6),
na_range = 5:6)
#Check if v11 has NA values
is.na(v11)
#[1] FALSE FALSE FALSE FALSE TRUE TRUE
v22 = labelled_spss(x = c(1,2,2,2,5,6),
labels = c(agree=1, disagree=2, dk=5, refused=6),
na_range = 5:6)
#Put v11 and v22 in a list
v33 = list(v11, v22)
#Use replace like above
data.frame(lapply(X = v33, FUN = function(a) replace(x = a, list = is.na(a), values = NA)))
# x x.1
#1 1 1
#2 2 2
#3 2 2
#4 2 2
#5 NA NA
#6 NA NA
Определение пользовательских пропущенных значений в стиле SPSS
Основные функции
Две основные функции в labelled Пакет для манипулирования пользовательскими пропущенными значениями в стиле SPSS na_values а также na_range,
library(labelled)
v1 <-c(1,2,2,2,5,6)
val_labels(v1) <- c(agree=1, disagree=2, dk=5, refused=6)
na_values(v1) <- 5:6
v1
<Labelled SPSS double>
[1] 1 2 2 2 5 6
Missing values: 5, 6
Labels:
value label
1 agree
2 disagree
5 dk
6 refused
set_* функции
set_* функции в labelled предназначены для использования с magrittr / dplyr,
library(dplyr)
d <- tibble(v1 = c(1, 2, 2, 2, 5, 6), v2 = c(1:3, 1:3))
d <- d %>%
set_value_labels(v1 = c(agree=1, disagree=2, dk=5, refused=6)) %>%
set_na_values(v1 = 5:6)
d$v1
<Labelled SPSS double>
[1] 1 2 2 2 5 6
Missing values: 5, 6
Labels:
value label
1 agree
2 disagree
5 dk
6 refused
Что такое пользовательские пропущенные значения?
Определяемые пользователем пропущенные значения являются лишь мета-информацией. Это не меняет значения в векторе. Это просто способ сказать пользователю, что эти значения могут / должны рассматриваться в некотором контексте как отсутствующие значения. Это означает, что если вы вычисляете что-то (например, среднее значение) по вашему вектору, эти значения все равно будут учитываться.
mean(v1)
[1] 3
Вы можете легко преобразовать определенные пользователем пропущенные значения в правильные NA с user_na_to_na,
mean(user_na_to_na(v1), na.rm = TRUE)
[1] 1.75
Существует очень мало функций, которые бы учитывали эту метаинформацию. Смотрите, например, freq функция от questionr пакет.
library(questionr)
freq(v1)
n % val%
[1] agree 1 16.7 25
[2] disagree 3 50.0 75
[5] dk 1 16.7 NA
[6] refused 1 16.7 NA
NA 0 0.0 NA
В чем разница с помеченными NA?
Цель помеченных НС, введенных haven, чтобы воспроизвести способ, которым Stata обрабатывает пропущенные значения. Все помеченные NA внутренне считаются NA по Р.
Первый аргумент set_na_values это фрейм данных, а не вектор / столбец, поэтому ваш lapply Команда не работает. Вы можете построить список аргументов для set_na_values для произвольного числа столбцов в вашем фрейме данных, а затем вызвать его с do.call как показано ниже...
v1<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v2<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v3<-data.frame(v1=v1, v2=v2)
na_values(v3)
args <- c(list(.data = v3), setNames(lapply(names(v3), function(x) c(5,6)), names(v3)))
v3 <- do.call(set_na_values, args)
na_values(v3)
Обновление: Вы также можете использовать форму назначения na_values функция в пределах lapply оператор, поскольку он принимает вектор в качестве первого аргумента вместо фрейма данных, например set_na_values...
library(haven)
library(labelled)
v1<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v2<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v3<-data.frame(v1=v1, v2=v2)
lapply(v3, val_labels)
na_values(v3)
v3[] <- lapply(v3, function(x) `na_values<-`(x, c(5,6)))
na_values(v3)
или даже использовать нормальную версию na_values в lapply команда, просто убедившись, чтобы вернуть "фиксированный" вектор...
library(haven)
library(labelled)
v1<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v2<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v3<-data.frame(v1=v1, v2=v2)
lapply(v3, val_labels)
na_values(v3)
v3[] <- lapply(v3, function(x) { na_values(x) <- c(5,6); x } )
na_values(v3)
и эта идея может быть использована внутри dplyr цепочка, либо применяя ко всем переменным, либо применяя к любым столбцам, выбранным с помощью dplyrинструменты выбора...
library(haven)
library(labelled)
library(dplyr)
v1<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v2<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v3<-data.frame(v1=v1, v2=v2)
lapply(v3, val_labels)
na_values(v3)
v4 <- v3 %>% mutate_all(funs(`na_values<-`(., c(5,6))))
na_values(v4)
v5 <- v3 %>% mutate_each(funs(`na_values<-`(., c(5,6))), x)
na_values(v5)
Вы могли бы использовать очень простое решение в использовании base Р:
v3[v3 == 5 ] <- NA
v3[v3 == 6 ] <- NA
Но если вы ищете действительно быстрое решение, вы можете использовать data.table подход.
library(data.table)
setDT(v3)
for(j in seq_along(v3)) {
set(v3, i=which(v3[[j]] %in% c(5,6)), j=j, value=NA)
}