Разбить генератор на куски, не прогуливая его
(Этот вопрос связан с этим и с этим, но это предварительная ходьба генератора, чего я и хочу избежать)
Я хотел бы разбить генератор на куски. Требования следующие:
- не дополняйте чанки: если количество оставшихся элементов меньше размера чанка, последний чанк должен быть меньше.
- не обходите генератор заранее: вычисление элементов стоит дорого, и это должно выполняться только функцией-потребителем, а не блоком
- что означает, конечно: не накапливать в памяти (нет списков)
Я пробовал следующий код:
def head(iterable, max=10):
for cnt, el in enumerate(iterable):
yield el
if cnt >= max:
break
def chunks(iterable, size=10):
i = iter(iterable)
while True:
yield head(i, size)
# Sample generator: the real data is much more complex, and expensive to compute
els = xrange(7)
for n, chunk in enumerate(chunks(els, 3)):
for el in chunk:
print 'Chunk %3d, value %d' % (n, el)
И это как-то работает:
Chunk 0, value 0
Chunk 0, value 1
Chunk 0, value 2
Chunk 1, value 3
Chunk 1, value 4
Chunk 1, value 5
Chunk 2, value 6
^CTraceback (most recent call last):
File "xxxx.py", line 15, in <module>
for el in chunk:
File "xxxx.py", line 2, in head
for cnt, el in enumerate(iterable):
KeyboardInterrupt
Buuuut... это никогда не останавливается (я должен нажать ^C) из-за while True, Я хотел бы остановить этот цикл всякий раз, когда генератор потребляется, но я не знаю, как обнаружить эту ситуацию. Я пытался поднять исключение:
class NoMoreData(Exception):
pass
def head(iterable, max=10):
for cnt, el in enumerate(iterable):
yield el
if cnt >= max:
break
if cnt == 0 : raise NoMoreData()
def chunks(iterable, size=10):
i = iter(iterable)
while True:
try:
yield head(i, size)
except NoMoreData:
break
# Sample generator: the real data is much more complex, and expensive to compute
els = xrange(7)
for n, chunk in enumerate(chunks(els, 2)):
for el in chunk:
print 'Chunk %3d, value %d' % (n, el)
Но тогда исключение возникает только в контексте потребителя, а это не то, что я хочу (я хочу, чтобы код потребителя был чистым)
Chunk 0, value 0
Chunk 0, value 1
Chunk 0, value 2
Chunk 1, value 3
Chunk 1, value 4
Chunk 1, value 5
Chunk 2, value 6
Traceback (most recent call last):
File "xxxx.py", line 22, in <module>
for el in chunk:
File "xxxx.py", line 9, in head
if cnt == 0 : raise NoMoreData
__main__.NoMoreData()
Как я могу обнаружить, что генератор исчерпан в chunks функция, не ходя это?
12 ответов
Одним из способов было бы посмотреть на первый элемент, если таковой имеется, а затем создать и вернуть фактический генератор.
def head(iterable, max=10):
first = next(iterable) # raise exception when depleted
def head_inner():
yield first # yield the extracted first element
for cnt, el in enumerate(iterable):
yield el
if cnt + 1 >= max: # cnt + 1 to include first
break
return head_inner()
Просто используйте это в своем chunk генератор и поймать StopIteration исключение, как вы сделали с вашим пользовательским исключением.
Обновление: вот еще одна версия, используя itertools.islice заменить большую часть head функция и for петля. Это просто for цикл на самом деле делает то же самое, что громоздкий while-try-next-except-break построить в исходном коде, так что результат гораздо более читабелен.
def chunks(iterable, size=10):
iterator = iter(iterable)
for first in iterator: # stops when iterator is depleted
def chunk(): # construct generator for next chunk
yield first # yield element from for loop
for more in islice(iterator, size - 1):
yield more # yield more elements from the iterator
yield chunk() # in outer generator, yield next chunk
И мы можем стать еще короче, используя itertools.chain заменить внутренний генератор:
def chunks(iterable, size=10):
iterator = iter(iterable)
for first in iterator:
yield chain([first], islice(iterator, size - 1))
Другой способ создания групп / чанков, а не предварительная прогулка - использование генератора itertools.groupby на ключевой функции, которая использует itertools.count объект. Так как count объект не зависит от итерируемого, чанки могут быть легко сгенерированы без знания того, что содержит итерируемое.
Каждая итерация groupby вызывает next метод count объект и генерирует ключ группы / чанка (за которым следуют элементы в чанке) путем целочисленного деления текущего значения счетчика на размер чанка.
from itertools import groupby, count
def chunks(iterable, size=10):
c = count()
for _, g in groupby(iterable, lambda _: next(c)//size):
yield g
Каждая группа / чанк g В результате получается функция генератора итератор. Тем не менее, так как groupby использует общий итератор для всех групп, групповые итераторы не могут быть сохранены в списке или каком-либо контейнере, каждый групповой итератор должен использоваться до следующей.
Самое быстрое решение, которое я мог бы найти, благодаря (в CPython) использованию встроенных функций уровня C. Таким образом, не требуется никакого байт-кода Python для создания каждого фрагмента (если только базовый генератор не реализован в Python), который имеет огромное преимущество в производительности. Он обходит каждый кусок перед тем, как вернуть его, но он не выполняет предварительную прогулку за пределы фрагмента, который собирается вернуть:
# Py2 only to get generator based map
from future_builtins import map
from itertools import islice, repeat, starmap, takewhile
# operator.truth is *significantly* faster than bool for the case of
# exactly one positional argument
from operator import truth
def chunker(n, iterable): # n is size of each chunk; last chunk may be smaller
return takewhile(truth, map(tuple, starmap(islice, repeat((iter(iterable), n)))))
Так как это немного плотно, разложенная версия для иллюстрации:
def chunker(n, iterable):
iterable = iter(iterable)
while True:
x = tuple(islice(iterable, n))
if not x:
return
yield x
Завершение звонка chunker в enumerate позволит вам нумеровать куски, если это необходимо.
more-itertools предоставил chunked и ichunked, которые могут достичь цели, это упоминается на странице документа Python 3 itertools.

Как насчет использования itertools.islice:
import itertools
els = iter(xrange(7))
print list(itertools.islice(els, 2))
print list(itertools.islice(els, 2))
print list(itertools.islice(els, 2))
print list(itertools.islice(els, 2))
Который дает:
[0, 1]
[2, 3]
[4, 5]
[6]
Начал осознавать полезность этого сценария, когда создавал решение для вставки БД из 500 тыс. Строк + с более высокой скоростью.
Генератор обрабатывает данные из источника и "выдает" их построчно; а затем другой генератор группирует выходные данные по блокам и "возвращает" его по блокам. Второй генератор знает только размер куска и ничего более.
Ниже приведен пример, чтобы подчеркнуть концепцию:
#!/usr/bin/python
def firstn_gen(n):
num = 0
while num < n:
yield num
num += 1
def chunk_gen(some_gen, chunk_size=7):
res_chunk = []
for count, item in enumerate(some_gen, 1):
res_chunk.append(item)
if count % chunk_size == 0:
yield res_chunk
res_chunk[:] = []
else:
yield res_chunk
if __name__ == '__main__':
for a_chunk in chunk_gen(firstn_gen(33)):
print(a_chunk)
Протестировано в Python 2.7.12:
[0, 1, 2, 3, 4, 5, 6]
[7, 8, 9, 10, 11, 12, 13]
[14, 15, 16, 17, 18, 19, 20]
[21, 22, 23, 24, 25, 26, 27]
[28, 29, 30, 31, 32]
У меня была такая же проблема, но я нашел более простое решение, чем упомянутое здесь:
def chunker(iterable, chunk_size):
els = iter(iterable)
while True:
next_el = next(els)
yield chain([next_el], islice(els, chunk_size - 1))
for i, chunk in enumerate(chunker(range(11), 2)):
for el in chunk:
print(i, el)
# Prints the following:
0 0
0 1
1 2
1 3
2 4
2 5
3 6
3 7
4 8
4 9
5 10
from itertools import islice
def chunk(it, n):
'''
# returns chunks of n elements each
>>> list(chunk(range(10), 3))
[
[0, 1, 2, ],
[3, 4, 5, ],
[6, 7, 8, ],
[9, ]
]
>>> list(chunk(list(range(10)), 3))
[
[0, 1, 2, ],
[3, 4, 5, ],
[6, 7, 8, ],
[9, ]
]
'''
def _w(g):
return lambda: tuple(islice(g, n))
return iter(_w(iter(it)), ())
Вдохновленный Moses Koledoye, я попытался найти решение, которое использует itertools.groupby, но не требует разделения на каждом этапе.
Следующая функция может использоваться в качестве ключа для groupby, и она просто возвращает логическое значение, которое переворачивается после предварительно определенного числа вызовов.
def chunks(chunksize=3):
def flag_gen():
flag = False
while True:
for num in range(chunksize):
yield flag
flag = not flag
flag_iter = flag_gen()
def flag_func(*args, **kwargs):
return next(flag_iter)
return flag_func
Который можно использовать так:
from itertools import groupby
my_long_generator = iter("abcdefghijklmnopqrstuvwxyz")
chunked_generator = groupby(my_long_generator, key=chunks(chunksize=5))
for flag, chunk in chunked_generator:
print("Flag is {f}".format(f=flag), list(chunk))
Выход:
Flag is False ['a', 'b', 'c', 'd', 'e']
Flag is True ['f', 'g', 'h', 'i', 'j']
Flag is False ['k', 'l', 'm', 'n', 'o']
Flag is True ['p', 'q', 'r', 's', 't']
Flag is False ['u', 'v', 'w', 'x', 'y']
Flag is True ['z']
Я сделал скрипку, демонстрирующую этот код.
Три варианта самого быстрого решения ShadowRanger до Python-3.12, использующего получение кортежей фрагментов и удаление значения заполнения из последнего фрагмента. ОниStefan_*в этом тесте для итерации с 10^6 элементами и размером фрагмента от n=2 до n=1000:
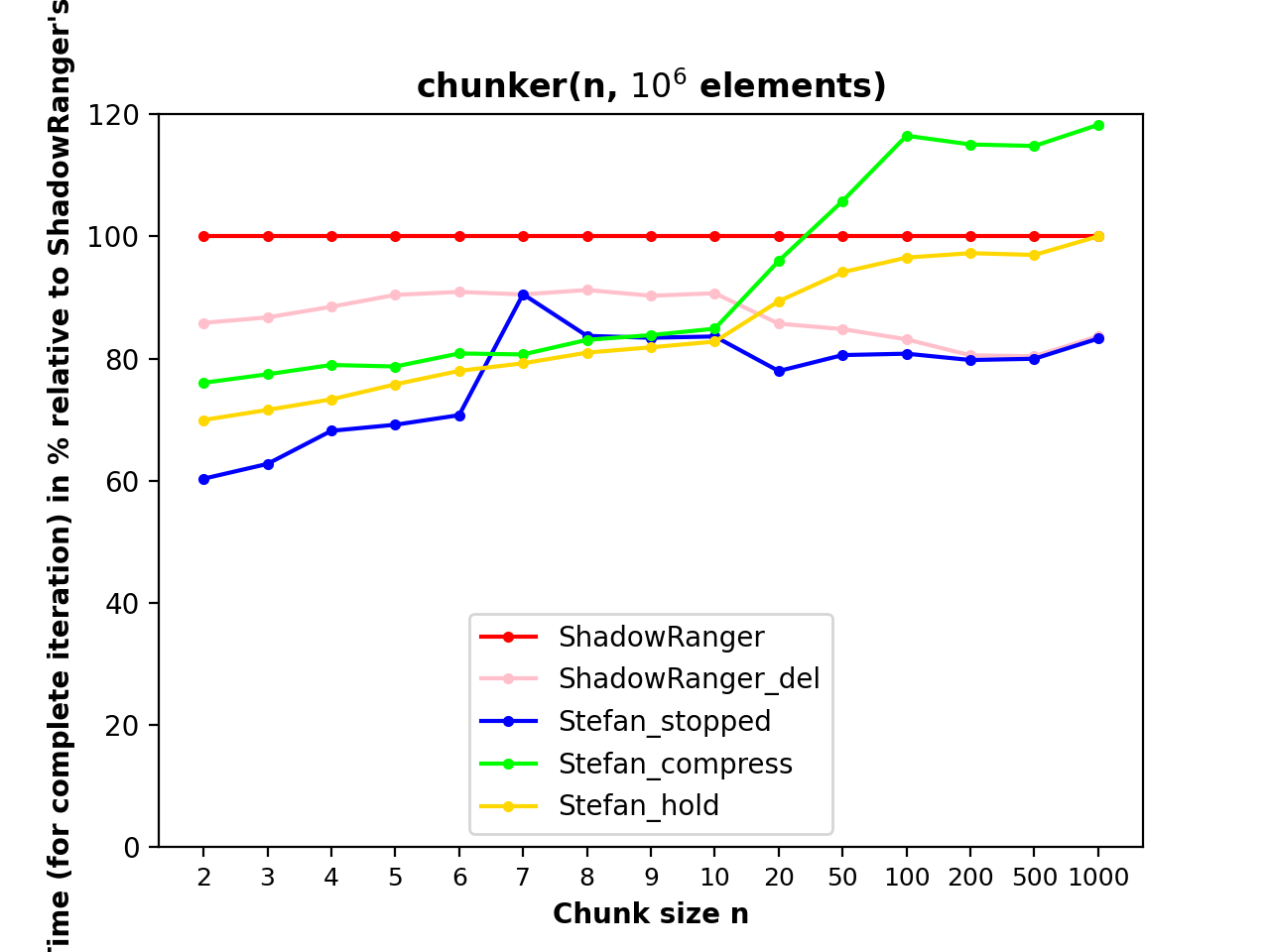
Протестировано на Python 3.10.8. Понятия не имею, что происходит с n=7 до n=10, я запускал тест несколько раз, и всегда так.
Stefan_hold
Этот блок содержит один фрагмент, и для каждого следующего фрагмента он возвращает удерживаемый фрагмент, а затем вместо него удерживает следующий. В конце очистите и дайте последний удерживаемый фрагмент.
def chunker(n, iterable):
fillvalue = object()
args = repeat(iter(iterable), n)
chunks = zip_longest(*args, fillvalue=fillvalue)
for chunk in chunks:
for next_chunk in chunks:
yield chunk
chunk = next_chunk
yield unfill(chunk, fillvalue)
ShadowRanger проверяетif x[-1] is fillvalue:за каждый кусокx. В этом решении я вместо этого использую более быстрыйif stopped:проверка значения bool. Чтобы это работало, я привязываю ко входу «пустой» итератор, единственная задача которого — установитьstoppedкTrue:
def chunker(n, iterable):
stopped = False
def stop():
nonlocal stopped
stopped = True
return
yield
fillvalue = object()
it = iter(iterable)
most = repeat(it, n-1)
last = chain(it, stop())
for chunk in zip_longest(*most, last, fillvalue=fillvalue):
if stopped:
yield unfill(chunk, fillvalue)
else:
yield chunk
del chunk
Stefan_compress
Этот вариант исключает интерпретацию Python на протяжении всего фрагмента, кроме последнего. Оно используетteeчтобы получить три копии итератора фрагментов из файла . Копия вносит все, кроме последнего фрагмента. Копия находится на один фрагмент впереди, ее единственная задача — не допустить последнего фрагмента изmain. slowкопия на шаг отстаетfastи предоставляет последний кусок.
def chunker(n, iterable):
fillvalue = object()
args = (iter(iterable),) * n
chunks = zip_longest(*args, fillvalue=fillvalue)
main, fast, slow = tee(chunks, 3)
next(fast, None)
return chain(
compress(main, zip(fast, slow)),
(unfill(chunk, fillvalue) for chunk in slow)
)
unfill
Помощник, который мои решения используют для удаления значения заполнения из последнего фрагмента:
def unfill(chunk, fillvalue):
return chunk[:bisect(chunk, False, key=lambda value: value is fillvalue)]
Оптимизация
ShadowRanger_delявляется незначительной модификацией решения ShadowRanger, удаляющей переменную фрагмента после получения фрагмента, так чтоzip_longestможет использовать оптимизацию повторного использования кортежа результатов. МойStefan_stoppedтакже использует эту оптимизацию.
Хотя это помогает/работает только в том случае, если потребитель нашего итератора фрагментов также не сохраняет ссылку на кортеж, например, если он используетmap(sum, chunker(...))вычислять суммы фрагментов чисел.
Вот тот же тест, но без негоdelоптимизация:

Полный код
Решения, проверка правильности, бенчмаркинг, построение графиков.
import sys
print(sys.version)
import matplotlib.pyplot as plt
from itertools import takewhile, zip_longest, chain, compress, tee, repeat
from timeit import timeit
from statistics import mean, stdev
from collections import deque
import gc
from random import sample
from bisect import bisect
#----------------------------------------------------------------------
# Solutions
#----------------------------------------------------------------------
def ShadowRanger(n, iterable):
'''chunker(3, 'ABCDEFG') --> ('A', 'B', 'C'), ('D', 'E', 'F'), ('G',)'''
fillvalue = object() # Anonymous sentinel object that can't possibly appear in input
args = (iter(iterable),) * n
for x in zip_longest(*args, fillvalue=fillvalue):
if x[-1] is fillvalue:
# takewhile optimizes a bit for when n is large and the final
# group is small; at the cost of a little performance, you can
# avoid the takewhile import and simplify to:
# yield tuple(v for v in x if v is not fillvalue)
yield tuple(takewhile(lambda v: v is not fillvalue, x))
else:
yield x
def ShadowRanger_del(n, iterable):
'''chunker(3, 'ABCDEFG') --> ('A', 'B', 'C'), ('D', 'E', 'F'), ('G',)'''
fillvalue = object() # Anonymous sentinel object that can't possibly appear in input
args = (iter(iterable),) * n
for x in zip_longest(*args, fillvalue=fillvalue):
if x[-1] is fillvalue:
# takewhile optimizes a bit for when n is large and the final
# group is small; at the cost of a little performance, you can
# avoid the takewhile import and simplify to:
# yield tuple(v for v in x if v is not fillvalue)
yield tuple(takewhile(lambda v: v is not fillvalue, x))
else:
yield x
del x
def unfill(chunk, fillvalue):
return chunk[:bisect(chunk, False, key=lambda value: value is fillvalue)]
def Stefan_stopped(n, iterable):
stopped = False
def stop():
nonlocal stopped
stopped = True
return
yield
fillvalue = object()
it = iter(iterable)
most = repeat(it, n-1)
last = chain(it, stop())
for chunk in zip_longest(*most, last, fillvalue=fillvalue):
if stopped:
yield unfill(chunk, fillvalue)
else:
yield chunk
del chunk
def Stefan_compress(n, iterable):
fillvalue = object()
args = (iter(iterable),) * n
chunks = zip_longest(*args, fillvalue=fillvalue)
main, fast, slow = tee(chunks, 3)
next(fast, None)
return chain(
compress(main, zip(fast, slow)),
(unfill(chunk, fillvalue) for chunk in slow)
)
def Stefan_hold(n, iterable):
fillvalue = object()
args = repeat(iter(iterable), n)
chunks = zip_longest(*args, fillvalue=fillvalue)
for chunk in chunks:
for next_chunk in chunks:
yield chunk
chunk = next_chunk
yield unfill(chunk, fillvalue)
funcs = ShadowRanger, ShadowRanger_del, Stefan_stopped, Stefan_compress, Stefan_hold
#----------------------------------------------------------------------
# Correctness checks
#----------------------------------------------------------------------
def run(f):
return list(f(n, iter(range(N))))
for n in range(1, 10):
for N in range(100):
args = n, range(N)
expect = run(ShadowRanger)
for f in funcs:
result = run(f)
if result != expect:
raise Exception(f'{f.__name__} failed for {n=}, {N=}')
#----------------------------------------------------------------------
# Benchmarking
#----------------------------------------------------------------------
benchmarks = []
# Speed
N = 10 ** 6
for n in *range(2, 11), 20, 50, 100, 200, 500, 1000:
for _ in range(1):
times = {f: [] for f in funcs}
def stats(f):
ts = [t * 1e3 for t in sorted(times[f])[:10]]
return f'{mean(ts):6.2f} ± {stdev(ts):4.2f} ms '
for _ in range(100):
for f in sample(funcs, len(funcs)):
gc.collect()
t = timeit(lambda: deque(f(n, repeat(None, N)), 0), number=1)
times[f].append(t)
print(f'\n{n = }')
for f in sorted(funcs, key=stats):
print(stats(f), f.__name__)
benchmarks.append((n, times))
#----------------------------------------------------------------------
# Plotting
#----------------------------------------------------------------------
names = [f.__name__ for f in funcs]
stats = [
(n, [mean(sorted(times[f])[:10]) * 1e3 for f in funcs])
for n, times in benchmarks
]
colors = {
'Stefan_stopped': 'blue',
'Stefan_compress': 'lime',
'Stefan_hold': 'gold',
'ShadowRanger': 'red',
'ShadowRanger_del': 'pink',
}
ns = [n for n, _ in stats]
print('%28s' % 'chunk size', *('%5d' % n for n in ns))
print('-' * 95)
x = range(len(ns))
for i, name in enumerate(names):
ts = [tss[i] for _, tss in stats]
ts = [tss[i] / tss[0] * 100 for _, tss in stats]
color = colors[name]
if color:
plt.plot(x, ts, '.-', color=color, label=name)
print('%29s' % name, *('%5.1f' % t for t in ts))
plt.xticks(x, ns, size=9)
plt.ylim(0, 120)
plt.title('chunker(n, $10^6$ elements)', weight='bold')
plt.xlabel('Chunk size n', weight='bold')
plt.ylabel("Time (for complete iteration) in % relative to ShadowRanger's", weight='bold')
plt.legend(loc='lower center')
#plt.show()
plt.savefig('chunker_plot.png', dpi=200)
Вы сказали, что не хотите хранить вещи в памяти, значит ли это, что вы не можете создать промежуточный список для текущего чанка?
Почему бы не пройти через генератор и не вставить значение часового между кусками? Потребитель (или подходящая оболочка) может игнорировать стража:
class Sentinel(object):
pass
def chunk(els, size):
for i, el in enumerate(els):
yield el
if i > 0 and i % size == 0:
yield Sentinel
РЕДАКТИРОВАТЬ другое решение с генератором генераторов
Вы не должны делать while True в вашем итераторе, но просто переберите его и обновите номер чанка на каждой итерации:
def chunk(it, maxv):
n = 0
for i in it:
yield n // mavx, i
n += 1
Если вы хотите генератор генераторов, вы можете иметь:
def chunk(a, maxv):
def inner(it, maxv, l):
l[0] = False
for i in range(maxv):
yield next(it)
l[0] = True
raise StopIteration
it = iter(a)
l = [True]
while l[0] == True:
yield inner(it, maxv, l)
raise StopIteration
с существом итеративным.
Тесты: на Python 2.7 и 3.4:
for i in chunk(range(7), 3):
print 'CHUNK'
for a in i:
print a
дает:
CHUNK
0
1
2
CHUNK
3
4
5
CHUNK
6
И на 2.7:
for i in chunk(xrange(7), 3):
print 'CHUNK'
for a in i:
print a
дает тот же результат.
Но ВНИМАНИЕ: list(chunk(range(7)) блоки на 2.7 и 3.4