hasChildNodes vs firstChild
while (div.hasChildNodes()) {
fragment.appendChild(div.firstChild)
}
while (div.firstChild) {
fragment.appendChild(div.firstChild)
}
Сравнивая два фрагмента псевдокода выше, они оба добавляют каждого потомка div в fragment пока нет больше детей.
- Когда бы вы предпочли
hasChildNodesили жеfirstChildони кажутся идентичными. - Если API очень похожи, то почему они оба существуют. Почему
hasChildNodes()существовать, когда я могу просто принуждатьfirstChildотnullвfalse
5 ответов
А) микрооптимизация!
б) Хотя это кажется обычной практикой, я не люблю полагаться на нулевые / ненулевые значения, используемые вместо ложных / истинных. Это экономия места, которая не нужна при включенном сжатии сервера (и иногда может вызывать скрытые ошибки). Выбирайте ясность каждый раз, если только это не вызывает узких мест.
Я бы выбрал первый вариант, потому что он отлично объясняет ваши намерения.
Там нет функциональной разницы между вашими двумя реализациями. Оба дают одинаковые результаты при любых обстоятельствах.
Если вы хотите выяснить, есть ли разница в производительности между ними, вам нужно будет запустить тесты производительности в нужных целевых браузерах, чтобы увидеть, есть ли существенная разница.
Вот тест производительности двух. Кажется, это зависит от браузера, для которого быстрее. hasChildNodes() значительно быстрее в Chrome, но firstChild немного быстрее в IE9 и Firefox.
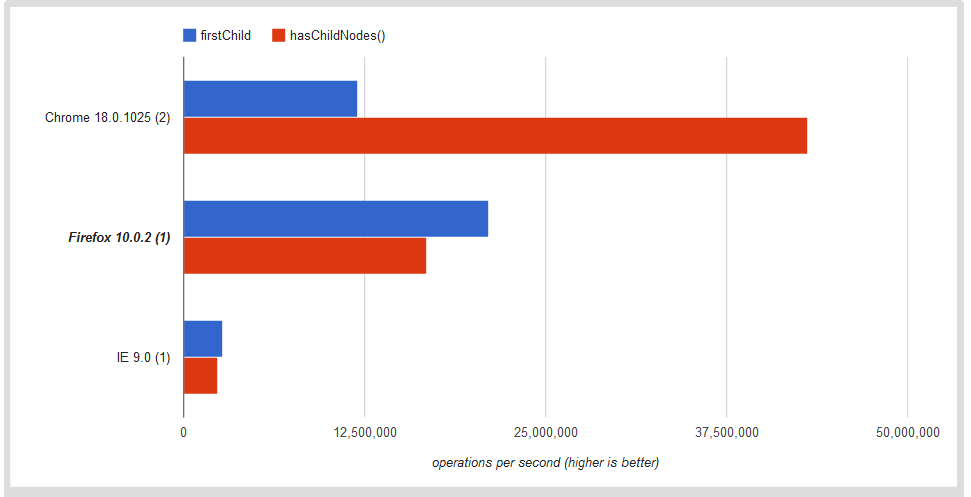
Если предположить, что вызовы DOM выполняются медленно, вы можете оптимизировать их дополнительно (за счет читабельности), используя один вызов firstChild:
var child;
while ( (child = div.firstChild) ) {
fragment.appendChild(child);
}
... хотя (странно, для меня) это, по-видимому, совсем не помогает и ухудшает положение, согласно этому jsPerf: http://jsperf.com/haschildnodes-vs-firstchild/2
Что касается того, почему существуют оба метода, помните, что DOM не является эксклюзивным для JavaScript. Например, в реализации Java DOM вам придется явно сравнивать firstChild (или, скорее всего, firstChild()) чтобы null,
Ваши два примера обычно * ведут себя одинаково, за исключением некоторых (вероятно) незначительных различий в скорости.
Единственная причина отдавать предпочтение одному над другим - это ясность, в частности, насколько хорошо каждая конструкция представляет идеи, которые реализует остальная часть вашего кода, модулируемая тем, легче ли вам визуально анализировать одну из них при чтении кода. Я советую отдавать предпочтение ясности, а не излишней педантичности, когда это возможно.
* Примечание: я предполагаю, что вы запускаете этот код на веб-странице в неопределенно современном браузере. Если ваш код должен выполняться в других контекстах, между.hasChildNodes() и.firstChild могут быть существенные различия в скорости или даже функциональные (побочные эффекты): один требует установки и выполнения вызова функции, другой требует чтобы DOM-совместимое представление первого потомка было готово для сценариев, если оно еще не доступно.
Я бы предложил hasChildNodes() поверх firstChild только из-за return; hasChildNodes() возвращается false если пусто firstChild возвращается null; что позволяет вам более эффективно анализировать данные, когда дело доходит до проверки их существования. На самом деле, это зависит от того, как вы планируете манипулировать DOM для достижения ваших результатов.