Запутался в random_state в дереве решений scikit learn
Смущен random_state параметр, не уверен, почему обучение дерева решений требует некоторой случайности. Мои мысли, (1) это связано со случайным лесом? (2) это связано с набором данных раздельного обучения? Если это так, то почему бы не использовать метод раздельного тестирования обучения ( http://scikit-learn.org/stable/modules/generated/sklearn.cross_validation.train_test_split.html)?
http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
>>> from sklearn.datasets import load_iris
>>> from sklearn.cross_validation import cross_val_score
>>> from sklearn.tree import DecisionTreeClassifier
>>> clf = DecisionTreeClassifier(random_state=0)
>>> iris = load_iris()
>>> cross_val_score(clf, iris.data, iris.target, cv=10)
...
...
array([ 1. , 0.93..., 0.86..., 0.93..., 0.93...,
0.93..., 0.93..., 1. , 0.93..., 1. ])
С уважением, Лин
6 ответов
Это объясняется в документации
Известно, что проблема изучения дерева оптимальных решений является NP-полной по нескольким аспектам оптимальности и даже для простых концепций. Следовательно, практические алгоритмы обучения дерева решений основаны на эвристических алгоритмах, таких как жадный алгоритм, где локально оптимальные решения принимаются на каждом узле. Такие алгоритмы не могут гарантировать возвращение глобально оптимального дерева решений. Это может быть смягчено путем обучения нескольких деревьев в ученике ансамбля, где элементы и образцы выбираются случайным образом с заменой.
Таким образом, в основном, неоптимальный жадный алгоритм повторяется несколько раз с использованием случайного выбора признаков и выборок (подобный метод используется в случайных лесах). random_state Параметр позволяет контролировать эти случайные выборы.
В документации интерфейса конкретно говорится:
Если int, random_state - начальное число, используемое генератором случайных чисел; Если экземпляр RandomState, random_state является генератором случайных чисел; Если None, генератор случайных чисел является экземпляром RandomState, используемым np.random.
Таким образом, случайный алгоритм будет использоваться в любом случае. Передача любого значения (будь то конкретное int, например, 0 или RandomState экземпляр), это не изменит. Единственное обоснование для передачи значения int (0 или иного) состоит в том, чтобы согласовать результат между вызовами: если вы вызываете это с помощью random_state=0 (или любое другое значение), то каждый раз, вы получите один и тот же результат.
Параметр, представленный для деревьев решений в scikit-learn, определяет, какую функцию выбрать для разделения, если (и только если) есть два разделения, которые одинаково хороши (т.е. две функции дают точно такое же улучшение в выбранных критериях разделения (например, Джини)). Если это не так, параметр не действует.
Проблема , связанная с ответом teatrader, обсуждает это более подробно, и в результате этого обсуждения в документы был добавлен следующий раздел (выделение добавлено):
random_state int, экземпляр RandomState или None, по умолчанию =None
Управляет случайностью оценщика. Функции всегда случайным образом переставляются при каждом разделении, даже если разделитель установлен на «лучший». Когда max_features < n_features, алгоритм будет случайным образом выбирать max_features при каждом разделении, прежде чем найдет среди них наилучшее разделение. Но наилучшее разделение может варьироваться в зависимости от разных прогонов, даже если max_features=n_features. Это тот случай, когда улучшение критерия идентично для нескольких расщеплений и необходимо выбрать одно расщепление случайным образом. Чтобы получить детерминированное поведение во время подбора, random_state должно быть фиксированным целым числом. Подробнее см. в Глоссарии.
Чтобы проиллюстрировать это, давайте рассмотрим следующий пример с набором выборочных данных радужной оболочки и неглубоким деревом решений, содержащим только одно разбиение:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
iris = load_iris(as_frame=True)
clf = DecisionTreeClassifier(max_depth=1)
clf = clf.fit(iris.data, iris.target)
plot_tree(clf, feature_names=iris['feature_names'], class_names=iris['target_names']);
Вывод этого кода будет чередоваться между двумя следующими деревьями в зависимости от того, какое из них используется.
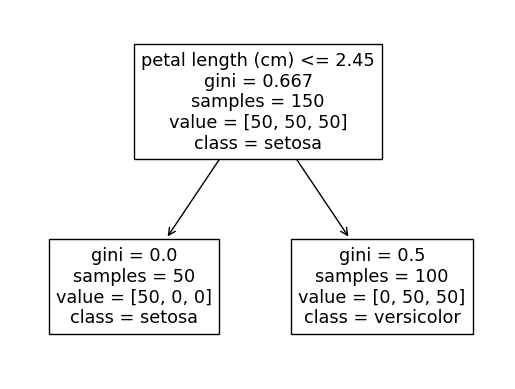
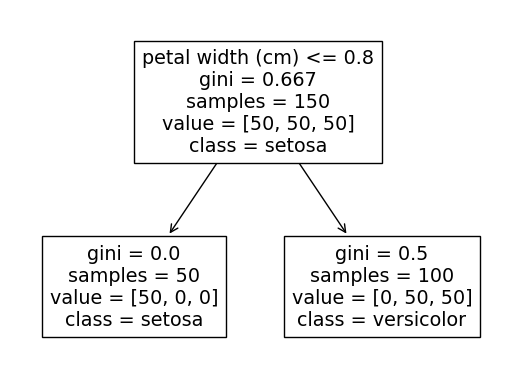
Причина этого в том, что разбиение на любой или на оба идеально отделит класс setosa от двух других классов (мы можем видеть, что крайний левый узел setosa содержит все 50 наблюдений setosa).
Если мы изменим только одно наблюдение за данными, чтобы один из двух предыдущих критериев разделения больше не давал идеального разделения, это не будет иметь никакого эффекта, и мы всегда будем получать один и тот же результат, например:
# Change the petal width for first observation of the "Setosa" class
# so that it overlaps with the values of the other two classes
iris['data'].loc[0, 'petal width (cm)'] = 5
clf = DecisionTreeClassifier(max_depth=1)
clf = clf.fit(iris.data, iris.target)
plot_tree(clf, feature_names=iris['feature_names'], class_names=iris['target_names']);

Первое разделение теперь всегда будет
Для случайного леса (который состоит из множества деревьев решений) мы создадим каждое отдельное дерево со случайным набором функций и образцов (см. https://scikit-learn.org/stable/modules/ensemble.html#random-forest ). -параметры для деталей), поэтому большую роль играет
Пара связанных вопросов:
Приведенная выше часть документации вводит в заблуждение, основная проблема не в жадности алгоритма. Алгоритм CART является детерминированным (см., например , здесь) и находит глобальный минимум взвешенных индексов Джини.
Повторные запуски дерева решений могут давать разные результаты, потому что иногда можно разделить данные, используя разные функции, и при этом получить тот же индекс Джини. Это описано здесь:https://github.com/scikit-learn/scikit-learn/issues/8443 .
Установка случайного состояния просто гарантирует, что реализация CART работает с тем же рандомизированным списком функций при поиске минимума.
Деревья решений используют эвристический процесс. Дерево решений не гарантирует глобального решения. Каждый раз, когда вы строите модель, в древовидной структуре будут появляться вариации. Передача определенного начального числа в random_state гарантирует, что каждый раз при построении модели будет генерироваться один и тот же результат.
Для воспроизводимого вывода при нескольких вызовах функций вам необходимо установить для random_state заданное целочисленное значение.
Многие модели машинного обучения допускают некоторую случайность в обучении моделей. Указание числа для random_state гарантирует, что вы получите одинаковые результаты при каждом запуске. Это считается хорошей практикой. Вы используете любое число, и качество модели не будет существенно зависеть от того, какое именно значение вы выберете.