Что делает системный вызов brk()?
Согласно руководству для программистов Linux:
brk () и sbrk() изменяют место остановки программы, которое определяет конец сегмента данных процесса.
Что здесь означает сегмент данных? Это просто сегмент данных или данные, BSS и куча вместе взятые?
Согласно вики:
Иногда данные, BSS и области кучи совместно называются "сегментом данных".
Я не вижу причин для изменения размера только сегмента данных. Если это данные, BSS и куча вместе, то это имеет смысл, поскольку куча получит больше места.
Что подводит меня ко второму вопросу. Во всех статьях, которые я до сих пор читал, автор говорит, что куча растет вверх, а стек - вниз. Но они не объясняют, что происходит, когда куча занимает все пространство между кучей и стеком?
9 ответов
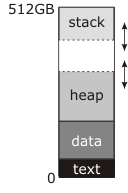
На диаграмме, которую вы разместили, "разрыв" - адрес, которым манипулируют brk а также sbrk- пунктирная линия наверху кучи.
В прочитанной вами документации это описывается как конец "сегмента данных", потому что в традиционных (pre-shared-library, premmap) Unix сегмент данных был непрерывным с кучей; перед запуском программы ядро загружало бы блоки "текст" и "данные" в ОЗУ, начиная с нулевого адреса (фактически немного выше нулевого адреса, так что указатель NULL на самом деле ни на что не указывал) и устанавливая адрес прерывания равным конец сегмента данных. Первый звонок malloc будет тогда использовать sbrk переместить разбиение и создать кучу между вершиной сегмента данных и новым, более высоким адресом разрыва, как показано на схеме, и последующим использованием malloc будет использовать его для увеличения кучи по мере необходимости.
Между тем, стек начинается с верхней части памяти и уменьшается. Стек не нуждается в явных системных вызовах, чтобы увеличить его; либо он запускается с выделением для него столько оперативной памяти, сколько у него когда-либо было (это был традиционный подход), либо область зарезервированных адресов под стеком, которой ядро автоматически выделяет ОЗУ, когда замечает попытку записи туда (это современный подход). В любом случае, в нижней части адресного пространства может быть или не быть "защитная" область, которую можно использовать для стека. Если этот регион существует (все современные системы делают это), он постоянно не отображается; если либо стек, либо куча пытается врасти в него, вы получаете ошибку сегментации. Традиционно, однако, ядро не делало попыток установить границы; стек может вырасти в кучу, или куча может вырасти в стек, и в любом случае они будут перебирать данные друг друга, и программа будет аварийно завершать работу. Если вам очень повезет, он сразу же потерпит крах.
Я не уверен, откуда исходит число 512 ГБ в этой диаграмме. Это подразумевает 64-битное виртуальное адресное пространство, которое несовместимо с очень простой картой памяти, которая у вас есть. Реальное 64-битное адресное пространство выглядит примерно так:

Это не для удаленного масштабирования, и его не следует интерпретировать как то, что делает любая конкретная ОС (после того, как я нарисовал ее, я обнаружил, что Linux фактически помещает исполняемый файл гораздо ближе к нулевому адресу, чем я думал, и разделяемые библиотеки). по удивительно высоким адресам). Черные области на этой диаграмме не отображены - любой доступ вызывает немедленную ошибку сегмента - и они гигантские по отношению к серым областям. Светло-серые области - это программа и ее общие библиотеки (могут быть десятки общих библиотек); у каждого есть независимый сегмент текста и данных (и сегмент "bss", который также содержит глобальные данные, но инициализируется нулевыми битами, а не занимает место в исполняемом файле или библиотеке на диске). Куча больше не обязательно непрерывна с сегментом данных исполняемого файла - я нарисовал его таким образом, но, похоже, Linux, по крайней мере, этого не делает. Стек больше не привязан к вершине виртуального адресного пространства, а расстояние между кучей и стеком настолько велико, что вам не нужно беспокоиться о его пересечении.
Разрыв по-прежнему является верхним пределом кучи. Однако я не показал, что где-то там могут быть десятки независимых распределений памяти, выполненных с mmap вместо brk, (ОС будет стараться держать их подальше от brk площадь, чтобы они не сталкивались.)
Минимальный работоспособный пример
Что делает системный вызов brk()?
Просит ядро разрешить вам читать и записывать в непрерывный кусок памяти, называемый кучей.
Если вы не спросите, это может вас обидеть.
Без brk:
#define _GNU_SOURCE
#include <unistd.h>
int main(void) {
/* Get the first address beyond the end of the heap. */
void *b = sbrk(0);
int *p = (int *)b;
/* May segfault because it is outside of the heap. */
*p = 1;
return 0;
}
С brk:
#define _GNU_SOURCE
#include <assert.h>
#include <unistd.h>
int main(void) {
void *b = sbrk(0);
int *p = (int *)b;
/* Move it 2 ints forward */
brk(p + 2);
/* Use the ints. */
*p = 1;
*(p + 1) = 2;
assert(*p == 1);
assert(*(p + 1) == 2);
/* Deallocate back. */
brk(b);
return 0;
}
Выше может не попасть на новую страницу и не segfault даже без brkтак что вот более агрессивная версия, которая выделяет 16MiB и очень вероятно, что segfault без brk:
#define _GNU_SOURCE
#include <assert.h>
#include <unistd.h>
int main(void) {
void *b;
char *p, *end;
b = sbrk(0);
p = (char *)b;
end = p + 0x1000000;
brk(end);
while (p < end) {
*(p++) = 1;
}
brk(b);
return 0;
}
Проверено на Ubuntu 18.04.
Визуализация виртуального адресного пространства
До brk:
+------+ <-- Heap Start == Heap End
После brk(p + 2):
+------+ <-- Heap Start + 2 * sizof(int) == Heap End
| |
| You can now write your ints
| in this memory area.
| |
+------+ <-- Heap Start
После brk(b):
+------+ <-- Heap Start == Heap End
Чтобы лучше понять адресные пространства, вы должны ознакомиться с подкачкой: как работает подкачка x86?
Больше информации
brk Раньше это был POSIX, но он был удален в POSIX 2001, поэтому необходимость _GNU_SOURCE чтобы получить доступ к оболочке glibc.
Удаление, вероятно, связано с введением mmap, который является надмножеством, которое позволяет распределить несколько диапазонов и больше опций выделения.
Внутренне ядро решает, может ли процесс иметь столько памяти, и выделяет страницы памяти для этого использования.
brk а также mmap общие механизмы, которые libc использует для реализации malloc в системах POSIX.
Это объясняет, как стек сравнивается с кучей: какова функция инструкций push / pop, используемых для регистров в сборке x86?
Ты можешь использовать brk а также sbrk самостоятельно, чтобы избежать "накладных расходов на malloc", на которые все всегда жалуются. Но вы не можете легко использовать этот метод в сочетании с malloc так что это подходит только тогда, когда вам не нужно free что-нибудь. Потому что ты не можешь. Кроме того, вы должны избегать любых библиотечных вызовов, которые могут использовать malloc внутренне. То есть. strlen вероятно безопасно, но fopen вероятно нет.
Вызов sbrk так же, как вы бы позвонили malloc, Он возвращает указатель на текущий разрыв и увеличивает разрыв на эту величину.
void *myallocate(int n){
return sbrk(n);
}
Несмотря на то, что вы не можете освободить отдельные выделения (так как помните, что нет служебных сигналов malloc), вы можете освободить все пространство, вызвав brk со значением, возвращаемым первым вызовом sbrk перематывая таким образом brk.
void *memorypool;
void initmemorypool(void){
memorypool = sbrk(0);
}
void resetmemorypool(void){
brk(memorypool);
}
Вы можете даже сложить эти регионы, отбросив самый последний регион, перемотав разрыв в начало региона.
Еще кое-что...
sbrk также полезно в коде гольф, потому что это на 2 символа короче malloc,
Существует специальное обозначенное анонимное сопоставление частной памяти (традиционно расположенное сразу за data/bss, но современный Linux фактически отрегулирует местоположение с помощью ASLR). В принципе, это не лучше, чем любое другое отображение, которое вы могли бы создать mmap, но в Linux есть некоторые оптимизации, которые позволяют расширить конец этого отображения (используя brk syscall) вверх с уменьшенной стоимостью блокировки относительно того, что mmap или же mremap понесет Это делает его привлекательным для malloc реализации для использования при реализации основной кучи.
malloc использует системный вызов brk для выделения памяти.
включают
int main(void){
char *a = malloc(10);
return 0;
}
запустите эту простую программу с помощью strace, она вызовет систему brk.
Куча помещается последней в сегменте данных программы. brk() используется для изменения (расширения) размера кучи. Когда куча больше не может расти malloc вызов не удастся.
Я могу ответить на ваш второй вопрос. Malloc потерпит неудачу и возвратит нулевой указатель. Вот почему вы всегда проверяете нулевой указатель при динамическом выделении памяти.
Сегмент данных - это часть памяти, которая содержит все ваши статические данные, считанные из исполняемого файла при запуске и обычно заполненные нулями.
Системный вызов, который обрабатывает выделение памяти
sbrk(2), Увеличивает или уменьшает адресное пространство процесса на указанное количество байтов.Функция выделения памяти,
malloc(3), реализует один конкретный тип распределения.malloc()функция, которая, вероятно, будет использоватьsbrk()системный вызов.
Системный вызов sbrk(2) в ядре выделяется дополнительный кусок пространства от имени процесса. malloc() Функция библиотеки управляет этим пространством с уровня пользователя.