Построение эффекта сокращения документа на корпусе текста в R text2vec
Можно ли проверить, сколько документов осталось в корпусе после подачи заявления? prune_vocabulary в text2vec пакет?
Вот пример получения набора данных и сокращения словарного запаса
library(text2vec)
library(data.table)
library(tm)
#Load movie review dataset
data("movie_review")
setDT(movie_review)
setkey(movie_review, id)
set.seed(2016L)
#Tokenize
prep_fun = tolower
tok_fun = word_tokenizer
it_train = itoken(movie_review$review,
preprocessor = prep_fun,
tokenizer = tok_fun,
ids = movie_review$id,
progressbar = FALSE)
#Generate vocabulary
vocab = create_vocabulary(it_train
, stopwords = tm::stopwords())
#Prune vocabulary
#How do I ascertain how many documents got kicked out of my training set because of the pruning criteria?
pruned_vocab = prune_vocabulary(vocab,
term_count_min = 10,
doc_proportion_max = 0.5,
doc_proportion_min = 0.001)
# create document term matrix with new pruned vocabulary vectorizer
vectorizer = vocab_vectorizer(pruned_vocab)
dtm_train = create_dtm(it_train, vectorizer)
Есть ли простой способ понять, насколько агрессивно term_count_min а также doc_proportion_min параметры находятся в моем текстовом корпусе. Я пытаюсь сделать что-то похожее на то, как stm Пакет позволяет нам справиться с этим, используя plotRemoved функция, которая производит сюжет, как это:
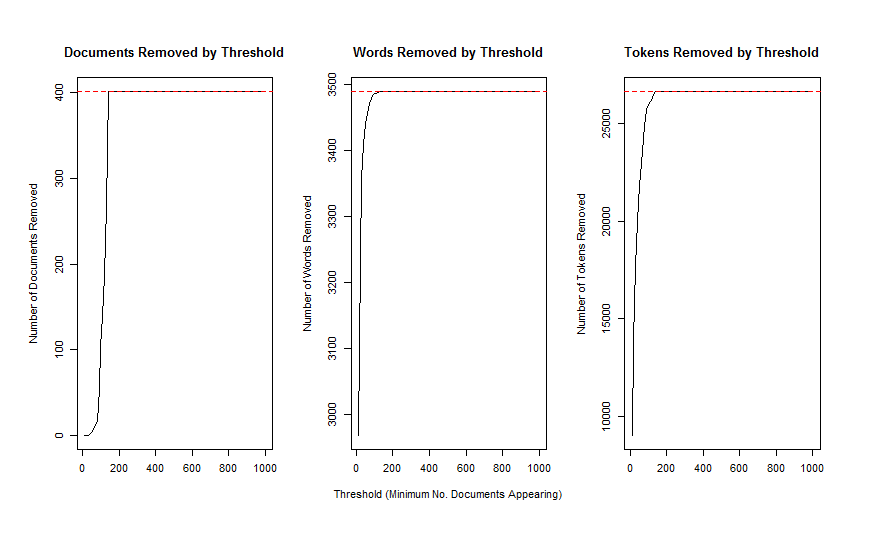
1 ответ
vocab $vocab это data.table который содержит много статистики о вашем корпусе. prune_vocabulary с term_count_min, doc_proportion_min параметры просто фильтруют это data.table, Например, вот как вы можете рассчитать количество удаленных токенов:
total_tokens = sum(v$vocab$terms_counts)
total_tokens
# 1230342
# now lets prune
v2 = prune_vocabulary(v, term_count_min = 10)
total_tokens - sum(v2$vocab$terms_counts)
# 78037
# effectively this will remove 78037 tokens
С другой стороны, вы можете создавать матрицы терминов документа с разными словарями и проверять разные статистические данные с помощью функций из Matrix пакет: colMeans(), colSums(), rowMeans(), rowSums()и т.д. Я уверен, что вы можете получить любой из показателей выше.
Например, вот как найти пустые документы:
doc_word_count = Matrix::rowSums(dtm)
indices_empty_docs = which(doc_word_count == 0)