Значительная аномалия производительности FMA в процессоре Intel Broadwell
Code1:
vzeroall mov rcx, 1000000 startLabel1: vfmadd231ps ymm0, ymm0, ymm0 vfmadd231ps ymm1, ymm1, ymm1 vfmadd231ps ymm2, ymm2, ymm2 vfmadd231ps ymm3, ymm3, ymm3 vfmadd231ps ymm4, ymm4, ymm4 vfmadd231ps ymm5, ymm5, ymm5 vfmadd231ps ymm6, ymm6, ymm6 vfmadd231ps ymm7, ymm7, ymm7 vfmadd231ps ymm8, ymm8, ymm8 vfmadd231ps ymm9, ymm9, ymm9 vpaddd ymm10, ymm10, ymm10 vpaddd ymm11, ymm11, ymm11 vpaddd ymm12, ymm12, ymm12 vpaddd ymm13, ymm13, ymm13 vpaddd ymm14, ymm14, ymm14 dec rcx jnz startLabel1Кодекса2:
vzeroall mov rcx, 1000000 startLabel2: vmulps ymm0, ymm0, ymm0 vmulps ymm1, ymm1, ymm1 vmulps ymm2, ymm2, ymm2 vmulps ymm3, ymm3, ymm3 vmulps ymm4, ymm4, ymm4 vmulps ymm5, ymm5, ymm5 vmulps ymm6, ymm6, ymm6 vmulps ymm7, ymm7, ymm7 vmulps ymm8, ymm8, ymm8 vmulps ymm9, ymm9, ymm9 vpaddd ymm10, ymm10, ymm10 vpaddd ymm11, ymm11, ymm11 vpaddd ymm12, ymm12, ymm12 vpaddd ymm13, ymm13, ymm13 vpaddd ymm14, ymm14, ymm14 dec rcx jnz startLabel2Code3 (аналогично Code2, но с длинным префиксом VEX):
vzeroall mov rcx, 1000000 startLabel3: byte 0c4h, 0c1h, 07ch, 059h, 0c0h ;long VEX form vmulps ymm0, ymm0, ymm0 byte 0c4h, 0c1h, 074h, 059h, 0c9h ;long VEX form vmulps ymm1, ymm1, ymm1 byte 0c4h, 0c1h, 06ch, 059h, 0d2h ;long VEX form vmulps ymm2, ymm2, ymm2 byte 0c4h, 0c1h, 06ch, 059h, 0dbh ;long VEX form vmulps ymm3, ymm3, ymm3 byte 0c4h, 0c1h, 05ch, 059h, 0e4h ;long VEX form vmulps ymm4, ymm4, ymm4 byte 0c4h, 0c1h, 054h, 059h, 0edh ;long VEX form vmulps ymm5, ymm5, ymm5 byte 0c4h, 0c1h, 04ch, 059h, 0f6h ;long VEX form vmulps ymm6, ymm6, ymm6 byte 0c4h, 0c1h, 044h, 059h, 0ffh ;long VEX form vmulps ymm7, ymm7, ymm7 vmulps ymm8, ymm8, ymm8 vmulps ymm9, ymm9, ymm9 vpaddd ymm10, ymm10, ymm10 vpaddd ymm11, ymm11, ymm11 vpaddd ymm12, ymm12, ymm12 vpaddd ymm13, ymm13, ymm13 vpaddd ymm14, ymm14, ymm14 dec rcx jnz startLabel3Code4 (аналогично Code1, но с регистрами xmm):
vzeroall mov rcx, 1000000 startLabel4: vfmadd231ps xmm0, xmm0, xmm0 vfmadd231ps xmm1, xmm1, xmm1 vfmadd231ps xmm2, xmm2, xmm2 vfmadd231ps xmm3, xmm3, xmm3 vfmadd231ps xmm4, xmm4, xmm4 vfmadd231ps xmm5, xmm5, xmm5 vfmadd231ps xmm6, xmm6, xmm6 vfmadd231ps xmm7, xmm7, xmm7 vfmadd231ps xmm8, xmm8, xmm8 vfmadd231ps xmm9, xmm9, xmm9 vpaddd xmm10, xmm10, xmm10 vpaddd xmm11, xmm11, xmm11 vpaddd xmm12, xmm12, xmm12 vpaddd xmm13, xmm13, xmm13 vpaddd xmm14, xmm14, xmm14 dec rcx jnz startLabel4Code5 (так же, как Code1, но с ненулевым vpsubd`s):
vzeroall mov rcx, 1000000 startLabel5: vfmadd231ps ymm0, ymm0, ymm0 vfmadd231ps ymm1, ymm1, ymm1 vfmadd231ps ymm2, ymm2, ymm2 vfmadd231ps ymm3, ymm3, ymm3 vfmadd231ps ymm4, ymm4, ymm4 vfmadd231ps ymm5, ymm5, ymm5 vfmadd231ps ymm6, ymm6, ymm6 vfmadd231ps ymm7, ymm7, ymm7 vfmadd231ps ymm8, ymm8, ymm8 vfmadd231ps ymm9, ymm9, ymm9 vpsubd ymm10, ymm10, ymm11 vpsubd ymm11, ymm11, ymm12 vpsubd ymm12, ymm12, ymm13 vpsubd ymm13, ymm13, ymm14 vpsubd ymm14, ymm14, ymm10 dec rcx jnz startLabel5Code6b: (исправлено, операнды памяти только для vpaddds)
vzeroall mov rcx, 1000000 startLabel6: vfmadd231ps ymm0, ymm0, ymm0 vfmadd231ps ymm1, ymm1, ymm1 vfmadd231ps ymm2, ymm2, ymm2 vfmadd231ps ymm3, ymm3, ymm3 vfmadd231ps ymm4, ymm4, ymm4 vfmadd231ps ymm5, ymm5, ymm5 vfmadd231ps ymm6, ymm6, ymm6 vfmadd231ps ymm7, ymm7, ymm7 vfmadd231ps ymm8, ymm8, ymm8 vfmadd231ps ymm9, ymm9, ymm9 vpaddd ymm10, ymm10, [mem] vpaddd ymm11, ymm11, [mem] vpaddd ymm12, ymm12, [mem] vpaddd ymm13, ymm13, [mem] vpaddd ymm14, ymm14, [mem] dec rcx jnz startLabel6Code7: (так же, как Code1, но vpaddds использует ymm15)
vzeroall mov rcx, 1000000 startLabel7: vfmadd231ps ymm0, ymm0, ymm0 vfmadd231ps ymm1, ymm1, ymm1 vfmadd231ps ymm2, ymm2, ymm2 vfmadd231ps ymm3, ymm3, ymm3 vfmadd231ps ymm4, ymm4, ymm4 vfmadd231ps ymm5, ymm5, ymm5 vfmadd231ps ymm6, ymm6, ymm6 vfmadd231ps ymm7, ymm7, ymm7 vfmadd231ps ymm8, ymm8, ymm8 vfmadd231ps ymm9, ymm9, ymm9 vpaddd ymm10, ymm15, ymm15 vpaddd ymm11, ymm15, ymm15 vpaddd ymm12, ymm15, ymm15 vpaddd ymm13, ymm15, ymm15 vpaddd ymm14, ymm15, ymm15 dec rcx jnz startLabel7Code8: (так же, как Code7, но использует xmm вместо ymm)
vzeroall mov rcx, 1000000 startLabel8: vfmadd231ps xmm0, ymm0, ymm0 vfmadd231ps xmm1, xmm1, xmm1 vfmadd231ps xmm2, xmm2, xmm2 vfmadd231ps xmm3, xmm3, xmm3 vfmadd231ps xmm4, xmm4, xmm4 vfmadd231ps xmm5, xmm5, xmm5 vfmadd231ps xmm6, xmm6, xmm6 vfmadd231ps xmm7, xmm7, xmm7 vfmadd231ps xmm8, xmm8, xmm8 vfmadd231ps xmm9, xmm9, xmm9 vpaddd xmm10, xmm15, xmm15 vpaddd xmm11, xmm15, xmm15 vpaddd xmm12, xmm15, xmm15 vpaddd xmm13, xmm15, xmm15 vpaddd xmm14, xmm15, xmm15 dec rcx jnz startLabel8
Измеренные часы TSC с отключенными Turbo и C1E:
Haswell Broadwell Skylake
CPUID 306C3, 40661 306D4, 40671 506E3
Code1 ~5000000 ~7730000 ->~54% slower ~5500000 ->~10% slower
Code2 ~5000000 ~5000000 ~5000000
Code3 ~6000000 ~5000000 ~5000000
Code4 ~5000000 ~7730000 ~5500000
Code5 ~5000000 ~7730000 ~5500000
Code6b ~5000000 ~8380000 ~5500000
Code7 ~5000000 ~5000000 ~5000000
Code8 ~5000000 ~5000000 ~5000000
Может кто-нибудь объяснить, что происходит с Code1 на Broadwell?
Я предполагаю, что Broadwell каким-то образом загрязняет Port1 с vpaddds в случае Code1, однако Haswell может использовать Port5, только если Port0 и Port1 заполнены;Есть ли у вас идеи выполнить ~5000000 clk на Broadwell с помощью инструкций FMA?
Я пытался изменить порядок. Схожее поведение с двойным и qword;
Я использовал Windows 8.1 и Win 10;
Обновить:
Добавил Code3 как идею Марата Духана с длинным VEX;
Расширенная таблица результатов с опытом Skylake;
Загрузил пример кода VS2015 Community + MASM здесь
Update2:
Я пробовал с регистрами xmm вместо ymm (код 4). Тот же результат на Бродвелле.
Update3:
Я добавил Code5 как идею Питера Кордеса (заменив vpaddd на другие интуиции (vpxor, vpor, vpand, vpandn, vpsubd)). Если новая инструкция не является идиомой обнуления (vpxor, vpsubd с тем же регистром), результат такой же на BDW. Пример проекта обновлен с помощью Code4 и Code5.
Update4:
Я добавил Code6 как идею Стивена Канона (операнды памяти). Результат ~8200000 кликов. Пример проекта обновлен с помощью Code6;
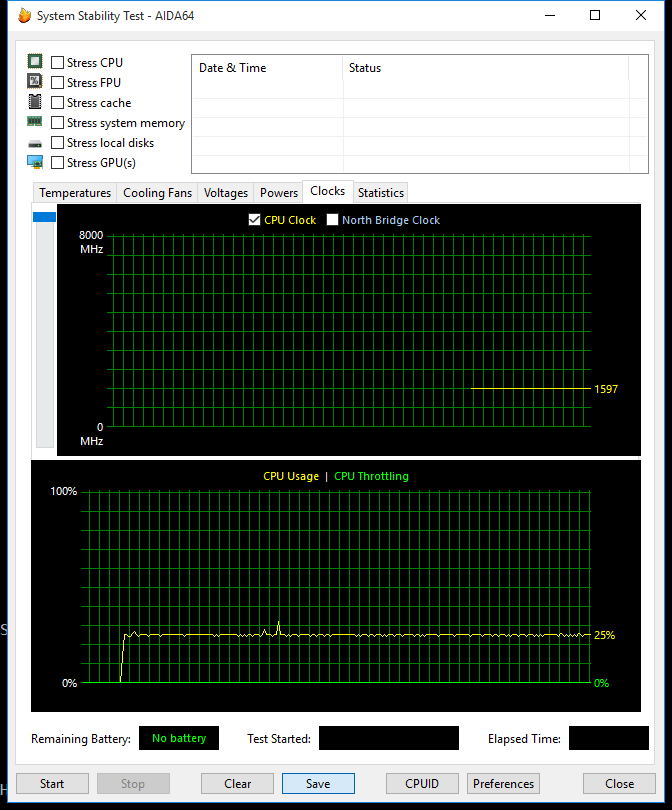
Я проверил частоту ЦП и возможное засорение с помощью теста стабильности системы AIDA64. Частота стабильна и никаких признаков дросселирования;
Анализ пропускной способности Intel IACA 2.1 Haswell:
Intel(R) Architecture Code Analyzer Version - 2.1 Analyzed File - Assembly.obj Binary Format - 64Bit Architecture - HSW Analysis Type - Throughput Throughput Analysis Report -------------------------- Block Throughput: 5.10 Cycles Throughput Bottleneck: Port0, Port1, Port5 Port Binding In Cycles Per Iteration: --------------------------------------------------------------------------------------- | Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 | --------------------------------------------------------------------------------------- | Cycles | 5.0 0.0 | 5.0 | 0.0 0.0 | 0.0 0.0 | 0.0 | 5.0 | 1.0 | 0.0 | --------------------------------------------------------------------------------------- | Num Of | Ports pressure in cycles | | | Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 | | --------------------------------------------------------------------------------- | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm0, ymm0, ymm0 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm1, ymm1, ymm1 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm2, ymm2, ymm2 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm3, ymm3, ymm3 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm4, ymm4, ymm4 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm5, ymm5, ymm5 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm6, ymm6, ymm6 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm7, ymm7, ymm7 | 1 | 1.0 | | | | | | | | CP | vfmadd231ps ymm8, ymm8, ymm8 | 1 | | 1.0 | | | | | | | CP | vfmadd231ps ymm9, ymm9, ymm9 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm10, ymm10, ymm10 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm11, ymm11, ymm11 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm12, ymm12, ymm12 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm13, ymm13, ymm13 | 1 | | | | | | 1.0 | | | CP | vpaddd ymm14, ymm14, ymm14 | 1 | | | | | | | 1.0 | | | dec rcx | 0F | | | | | | | | | | jnz 0xffffffffffffffaa Total Num Of Uops: 16Я следовал идее jcomeau_ictx и изменил testp.zip от Agner Fog (опубликовано 2015-12-22). Использование порта на BDW 306D4:
Clock Core cyc Instruct uop p0 uop p1 uop p5 uop p6 Code1: 7734720 7734727 17000001 4983410 5016592 5000001 1000001 Code2: 5000072 5000072 17000001 5000010 5000014 4999978 1000002Распределение портов почти идеальное, как на Haswell. Затем я проверил счетчики задержки ресурсов (событие 0xa2)
Clock Core cyc Instruct res.stl. RS stl. SB stl. ROB stl. Code1: 7736212 7736213 17000001 3736191 3736143 0 0 Code2: 5000068 5000072 17000001 1000050 999957 0 0Мне кажется, что разница между Code1 и Code2 исходит от киоска RS. Замечание от Intel SDM: "Циклы остановились из-за отсутствия доступной записи RS".
Как я могу избежать этого срыва с FMA?
Update5:
Код6 изменился, поскольку Питер Кордес привлек мое внимание, только vpaddds используют операнды памяти. Не влияет на HSW и SKL, BDW ухудшается.
Как показал Марат Духан, это касается не только vpadd/vpsub/vpand/vpandn/vpxor, но и других ограниченных инструкций Port5, таких как vmovaps, vblendps, vpermps, vshufps, vbroadcastss;
Как предположил IwillnotexistIdonotexist, я опробовал другие операнды. Успешная модификация - Code7, где все vpaddds используют ymm15. Эта версия может производить на BDW ~5000000 clks, но ненадолго. После ~6 миллионов пар FMA он достигает обычных ~7730000 clks:
Clock Core cyc Instruct res.stl. RS stl. SB stl. ROB stl. 5133724 5110723 17000001 1107998 946376 0 0 6545476 6545482 17000001 2545453 1 0 0 6545468 6545471 17000001 2545437 90910 0 0 5000016 5000019 17000001 999992 999992 0 0 7671620 7617127 17000003 3614464 3363363 0 0 7737340 7737345 17000001 3737321 3737259 0 0 7802916 7747108 17000003 3737478 3735919 0 0 7928784 7796057 17000007 3767962 3676744 0 0 7941072 7847463 17000003 3781103 3651595 0 0 7787812 7779151 17000005 3765109 3685600 0 0 7792524 7738029 17000002 3736858 3736764 0 0 7736000 7736007 17000001 3735983 3735945 0 0Я попробовал xmm версию Code7 как Code8. Эффект аналогичен, но более быстрое время выполнения сохраняется дольше. Я не нашел существенной разницы между 1,6 ГГц i5-5250U и 3,7 ГГц i7-5775C.
16 и 17 были сделаны с отключенным HyperThreading. При включенном HTT эффект меньше.
2 ответа
обновленный
У меня нет объяснения для вас, поскольку я работаю в Haswell, но у меня есть код, которым можно поделиться, который может помочь вам или кому-то еще с оборудованием Broadwell или Skylake изолировать вашу проблему. Если бы вы могли запустить его на своей машине и поделиться результатами, мы могли бы понять, что происходит с вашей машиной.
вступление
Последние процессоры Intel Core i7 имеют 7 счетчиков монитора производительности (3 PMC), 3 фиксированных и 4 универсальных, которые можно использовать для профилирования кода. PMC с фиксированной функцией:
- Инструкции на пенсию
- Небольшие циклы ядра (такты часов, включая эффекты TurboBoost)
- Unhalted Reference циклы (тактовые частоты с фиксированной частотой)
Соотношение тактовых импульсов ядро: эталон определяет относительное ускорение или замедление при динамическом масштабировании частоты.
Хотя существует программное обеспечение (см. Комментарии ниже), которое обращается к этим счетчикам, я их не знал и все же считаю, что они недостаточно детализированы.
Поэтому я написал себе модуль ядра Linux, perfcountза последние несколько дней, чтобы предоставить мне доступ к мониторам счетчиков производительности Intel, а также к тестовому пространству и библиотеке пользовательского пространства для вашего кода, который оборачивает ваш код FMA вокруг вызовов моего LKM. Инструкции по воспроизведению моих настроек будут следовать.
Мой исходный код testbench находится ниже. Он прогревается, затем запускает ваш код несколько раз, тестируя его по длинному списку метрик. Я изменил количество циклов до 1 миллиарда. Поскольку одновременно можно запрограммировать только 4 PMC общего назначения, я выполняю измерения по 4 одновременно.
perfcountdemo.c
/* Includes */
#include "libperfcount.h"
#include <ctype.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* Function prototypes */
void code1(void);
void code2(void);
void code3(void);
void code4(void);
void code5(void);
/* Global variables */
void ((*FN_TABLE[])(void)) = {
code1,
code2,
code3,
code4,
code5
};
/**
* Code snippets to bench
*/
void code1(void){
asm volatile(
".intel_syntax noprefix\n\t"
"vzeroall\n\t"
"mov rcx, 1000000000\n\t"
"LstartLabel1:\n\t"
"vfmadd231ps %%ymm0, %%ymm0, %%ymm0\n\t"
"vfmadd231ps ymm1, ymm1, ymm1\n\t"
"vfmadd231ps ymm2, ymm2, ymm2\n\t"
"vfmadd231ps ymm3, ymm3, ymm3\n\t"
"vfmadd231ps ymm4, ymm4, ymm4\n\t"
"vfmadd231ps ymm5, ymm5, ymm5\n\t"
"vfmadd231ps ymm6, ymm6, ymm6\n\t"
"vfmadd231ps ymm7, ymm7, ymm7\n\t"
"vfmadd231ps ymm8, ymm8, ymm8\n\t"
"vfmadd231ps ymm9, ymm9, ymm9\n\t"
"vpaddd ymm10, ymm10, ymm10\n\t"
"vpaddd ymm11, ymm11, ymm11\n\t"
"vpaddd ymm12, ymm12, ymm12\n\t"
"vpaddd ymm13, ymm13, ymm13\n\t"
"vpaddd ymm14, ymm14, ymm14\n\t"
"dec rcx\n\t"
"jnz LstartLabel1\n\t"
".att_syntax noprefix\n\t"
: /* No outputs we care about */
: /* No inputs we care about */
: "xmm0", "xmm1", "xmm2", "xmm3", "xmm4", "xmm5", "xmm6", "xmm7",
"xmm8", "xmm9", "xmm10", "xmm11", "xmm12", "xmm13", "xmm14", "xmm15",
"rcx",
"memory"
);
}
void code2(void){
}
void code3(void){
}
void code4(void){
}
void code5(void){
}
/* Test Schedule */
const char* const SCHEDULE[] = {
/* Batch */
"uops_issued.any",
"uops_issued.any<1",
"uops_issued.any>=1",
"uops_issued.any>=2",
/* Batch */
"uops_issued.any>=3",
"uops_issued.any>=4",
"uops_issued.any>=5",
"uops_issued.any>=6",
/* Batch */
"uops_executed_port.port_0",
"uops_executed_port.port_1",
"uops_executed_port.port_2",
"uops_executed_port.port_3",
/* Batch */
"uops_executed_port.port_4",
"uops_executed_port.port_5",
"uops_executed_port.port_6",
"uops_executed_port.port_7",
/* Batch */
"resource_stalls.any",
"resource_stalls.rs",
"resource_stalls.sb",
"resource_stalls.rob",
/* Batch */
"uops_retired.all",
"uops_retired.all<1",
"uops_retired.all>=1",
"uops_retired.all>=2",
/* Batch */
"uops_retired.all>=3",
"uops_retired.all>=4",
"uops_retired.all>=5",
"uops_retired.all>=6",
/* Batch */
"inst_retired.any_p",
"inst_retired.any_p<1",
"inst_retired.any_p>=1",
"inst_retired.any_p>=2",
/* Batch */
"inst_retired.any_p>=3",
"inst_retired.any_p>=4",
"inst_retired.any_p>=5",
"inst_retired.any_p>=6",
/* Batch */
"idq_uops_not_delivered.core",
"idq_uops_not_delivered.core<1",
"idq_uops_not_delivered.core>=1",
"idq_uops_not_delivered.core>=2",
/* Batch */
"idq_uops_not_delivered.core>=3",
"idq_uops_not_delivered.core>=4",
"rs_events.empty",
"idq.empty",
/* Batch */
"idq.mite_all_uops",
"idq.mite_all_uops<1",
"idq.mite_all_uops>=1",
"idq.mite_all_uops>=2",
/* Batch */
"idq.mite_all_uops>=3",
"idq.mite_all_uops>=4",
"move_elimination.int_not_eliminated",
"move_elimination.simd_not_eliminated",
/* Batch */
"lsd.uops",
"lsd.uops<1",
"lsd.uops>=1",
"lsd.uops>=2",
/* Batch */
"lsd.uops>=3",
"lsd.uops>=4",
"ild_stall.lcp",
"ild_stall.iq_full",
/* Batch */
"br_inst_exec.all_branches",
"br_inst_exec.0x81",
"br_inst_exec.0x82",
"icache.misses",
/* Batch */
"br_misp_exec.all_branches",
"br_misp_exec.0x81",
"br_misp_exec.0x82",
"fp_assist.any",
/* Batch */
"cpu_clk_unhalted.core_clk",
"cpu_clk_unhalted.ref_xclk",
"baclears.any"
};
const int NUMCOUNTS = sizeof(SCHEDULE)/sizeof(*SCHEDULE);
/**
* Main
*/
int main(int argc, char* argv[]){
int i;
/**
* Initialize
*/
pfcInit();
if(argc <= 1){
pfcDumpEvents();
exit(1);
}
pfcPinThread(3);
/**
* Arguments are:
*
* perfcountdemo #codesnippet
*
* There is a schedule of configuration that is followed.
*/
void (*fn)(void) = FN_TABLE[strtoull(argv[1], NULL, 0)];
static const uint64_t ZERO_CNT[7] = {0,0,0,0,0,0,0};
static const uint64_t ZERO_CFG[7] = {0,0,0,0,0,0,0};
uint64_t cnt[7] = {0,0,0,0,0,0,0};
uint64_t cfg[7] = {2,2,2,0,0,0,0};
/* Warmup */
for(i=0;i<10;i++){
fn();
}
/* Run master loop */
for(i=0;i<NUMCOUNTS;i+=4){
/* Configure counters */
const char* sched0 = i+0 < NUMCOUNTS ? SCHEDULE[i+0] : "";
const char* sched1 = i+1 < NUMCOUNTS ? SCHEDULE[i+1] : "";
const char* sched2 = i+2 < NUMCOUNTS ? SCHEDULE[i+2] : "";
const char* sched3 = i+3 < NUMCOUNTS ? SCHEDULE[i+3] : "";
cfg[3] = pfcParseConfig(sched0);
cfg[4] = pfcParseConfig(sched1);
cfg[5] = pfcParseConfig(sched2);
cfg[6] = pfcParseConfig(sched3);
pfcWrConfigCnts(0, 7, cfg);
pfcWrCountsCnts(0, 7, ZERO_CNT);
pfcRdCountsCnts(0, 7, cnt);
/* ^ Should report 0s, and launch the counters. */
/************** Hot section **************/
fn();
/************ End Hot section ************/
pfcRdCountsCnts(0, 7, cnt);
pfcWrConfigCnts(0, 7, ZERO_CFG);
/* ^ Should clear the counter config and disable them. */
/**
* Print the lovely results
*/
printf("Instructions Issued : %20llu\n", cnt[0]);
printf("Unhalted core cycles : %20llu\n", cnt[1]);
printf("Unhalted reference cycles : %20llu\n", cnt[2]);
printf("%-35s: %20llu\n", sched0, cnt[3]);
printf("%-35s: %20llu\n", sched1, cnt[4]);
printf("%-35s: %20llu\n", sched2, cnt[5]);
printf("%-35s: %20llu\n", sched3, cnt[6]);
}
/**
* Close up shop
*/
pfcFini();
}
На моей машине я получил следующие результаты:
Haswell Core i7-4700MQ
> ./perfcountdemo 0
Instructions Issued : 17000001807
Unhalted core cycles : 5305920785
Unhalted reference cycles : 4245764952
uops_issued.any : 16000811079
uops_issued.any<1 : 1311417889
uops_issued.any>=1 : 4000292290
uops_issued.any>=2 : 4000229358
Instructions Issued : 17000001806
Unhalted core cycles : 5303822082
Unhalted reference cycles : 4243345896
uops_issued.any>=3 : 4000156998
uops_issued.any>=4 : 4000110067
uops_issued.any>=5 : 0
uops_issued.any>=6 : 0
Instructions Issued : 17000001811
Unhalted core cycles : 5314227923
Unhalted reference cycles : 4252020624
uops_executed_port.port_0 : 5016261477
uops_executed_port.port_1 : 5036728509
uops_executed_port.port_2 : 5282
uops_executed_port.port_3 : 12481
Instructions Issued : 17000001816
Unhalted core cycles : 5329351248
Unhalted reference cycles : 4265809728
uops_executed_port.port_4 : 7087
uops_executed_port.port_5 : 4946019835
uops_executed_port.port_6 : 1000228324
uops_executed_port.port_7 : 1372
Instructions Issued : 17000001816
Unhalted core cycles : 5325153463
Unhalted reference cycles : 4261060248
resource_stalls.any : 1322734589
resource_stalls.rs : 844250210
resource_stalls.sb : 0
resource_stalls.rob : 0
Instructions Issued : 17000001814
Unhalted core cycles : 5327823817
Unhalted reference cycles : 4262914728
uops_retired.all : 16000445793
uops_retired.all<1 : 687284798
uops_retired.all>=1 : 4646263984
uops_retired.all>=2 : 4452324050
Instructions Issued : 17000001809
Unhalted core cycles : 5311736558
Unhalted reference cycles : 4250015688
uops_retired.all>=3 : 3545695253
uops_retired.all>=4 : 3341664653
uops_retired.all>=5 : 1016
uops_retired.all>=6 : 1
Instructions Issued : 17000001871
Unhalted core cycles : 5477215269
Unhalted reference cycles : 4383891984
inst_retired.any_p : 17000001871
inst_retired.any_p<1 : 891904306
inst_retired.any_p>=1 : 4593972062
inst_retired.any_p>=2 : 4441024510
Instructions Issued : 17000001835
Unhalted core cycles : 5377202052
Unhalted reference cycles : 4302895152
inst_retired.any_p>=3 : 3555852364
inst_retired.any_p>=4 : 3369559466
inst_retired.any_p>=5 : 999980244
inst_retired.any_p>=6 : 0
Instructions Issued : 17000001826
Unhalted core cycles : 5349373678
Unhalted reference cycles : 4280991912
idq_uops_not_delivered.core : 1580573
idq_uops_not_delivered.core<1 : 5354931839
idq_uops_not_delivered.core>=1 : 471248
idq_uops_not_delivered.core>=2 : 418625
Instructions Issued : 17000001808
Unhalted core cycles : 5309687640
Unhalted reference cycles : 4248083976
idq_uops_not_delivered.core>=3 : 280800
idq_uops_not_delivered.core>=4 : 247923
rs_events.empty : 0
idq.empty : 649944
Instructions Issued : 17000001838
Unhalted core cycles : 5392229041
Unhalted reference cycles : 4315704216
idq.mite_all_uops : 2496139
idq.mite_all_uops<1 : 5397877484
idq.mite_all_uops>=1 : 971582
idq.mite_all_uops>=2 : 595973
Instructions Issued : 17000001822
Unhalted core cycles : 5347205506
Unhalted reference cycles : 4278845208
idq.mite_all_uops>=3 : 394011
idq.mite_all_uops>=4 : 335205
move_elimination.int_not_eliminated: 0
move_elimination.simd_not_eliminated: 0
Instructions Issued : 17000001812
Unhalted core cycles : 5320621549
Unhalted reference cycles : 4257095280
lsd.uops : 15999287982
lsd.uops<1 : 1326629729
lsd.uops>=1 : 3999821996
lsd.uops>=2 : 3999821996
Instructions Issued : 17000001813
Unhalted core cycles : 5320533147
Unhalted reference cycles : 4257105096
lsd.uops>=3 : 3999823498
lsd.uops>=4 : 3999823498
ild_stall.lcp : 0
ild_stall.iq_full : 3468
Instructions Issued : 17000001813
Unhalted core cycles : 5323278281
Unhalted reference cycles : 4258969200
br_inst_exec.all_branches : 1000016626
br_inst_exec.0x81 : 1000016616
br_inst_exec.0x82 : 0
icache.misses : 294
Instructions Issued : 17000001812
Unhalted core cycles : 5315098728
Unhalted reference cycles : 4253082504
br_misp_exec.all_branches : 5
br_misp_exec.0x81 : 2
br_misp_exec.0x82 : 0
fp_assist.any : 0
Instructions Issued : 17000001819
Unhalted core cycles : 5338484610
Unhalted reference cycles : 4271432976
cpu_clk_unhalted.core_clk : 5338494250
cpu_clk_unhalted.ref_xclk : 177976806
baclears.any : 1
: 0
Мы можем видеть, что на Haswell все хорошо смазано. Я сделаю несколько заметок из приведенной выше статистики:
- Выданные инструкции невероятно последовательны для меня. Это всегда рядом
17000001800, что является хорошим признаком: это означает, что мы можем очень хорошо оценить наши накладные расходы. То же самое для других счетчиков с фиксированными функциями. Тот факт, что все они достаточно хорошо соответствуют друг другу, означает, что тесты в партиях по 4 являются сравнением яблок с яблоками. - При соотношении циклов ядро: эталон около 5305920785/4245764952 мы получаем среднее масштабирование частоты ~1,25; Это хорошо согласуется с моими наблюдениями, что мое ядро разогналось с 2,4 до 3, 0 ГГц.
cpu_clk_unhalted.core_clk/(10.0*cpu_clk_unhalted.ref_xclk)дает чуть менее 3 ГГц тоже. - Отношение команд, выданных к основным циклам, дает IPC 17000001807/5305920785 ~ 3,20, что также примерно правильно: 2 FMA+1 VPADDD на каждый тактовый цикл для 4 тактовых циклов и 2 дополнительные инструкции управления циклом на каждый 5-й тактовый цикл, которые входят в параллельно.
uops_issued.any: Количество выданных инструкций ~17B, но количество выданных мопов ~16B. Это потому, что две инструкции для управления циклом сливаются вместе; Хороший знак. Кроме того, около 1,3B тактовых циклов из 5,3B (25% времени) ни одного мопа не было выпущено, в то время как почти все остальное время (4B тактовых тактов) выдается 4 мопа за раз.uops_executed_port.port_[0-7]: Насыщенность порта. У нас хорошее здоровье. Из 16B мопов после слияния, порты 0, 1 и 5 съели 5B мопов каждый в течение 5,3B циклов (что означает, что они были распределены оптимально: Float, float, int соответственно), Порт 6 съел 1B (слитая операция dec-branch) и порты 2, 3, 4 и 7 потребляли незначительные количества по сравнению.resource_stalls: 1,3B из них произошли, 2/3 из которых были связаны со станцией бронирования (RS), а другая треть - по неизвестным причинам.- Из кумулятивного распределения мы построили с нашими сравнениями на
uops_retired.allа такжеinst_retired.allмы знаем, что мы удаляем 4 мопа 60% времени, 0 мопов 13% времени и 2 мопа в остальное время, в остальном незначительные суммы. - (Многочисленные
*idq*рассчитывает): IDQ очень редко поддерживает нас. lsd: Детектор петлевого потока работает; Оттуда на фронтэнд поступило около 16В слитых мопов.ild: Декодирование длины команды не является узким местом, и не встречается ни одного префикса, меняющего длину.br_inst_exec/br_misp_exec: Неправильное предсказание ветвлений - незначительная проблема.icache.missesНезначительный.fp_assistНезначительный. Денормали не встречаются. (Я полагаю, что без DAZ-промывки, равной нулю, им потребуется помощь, которую следует зарегистрировать здесь)
Так что на Intel Haswell все гладко. Если бы вы могли запустить мой пакет на своих машинах, это было бы здорово.
Инструкция по размножению
- Правило № 1: Проверяйте весь мой код, прежде чем что-либо делать с ним. Никогда не доверяйте слепо незнакомцам в Интернете.
- Возьмите perfcountdemo.c, libperfcount.c и libperfcount.h, поместите их в один каталог и скомпилируйте их вместе.
- Возьмите perfcount.c и Makefile, поместите их в один каталог и
makeмодуль ядра. - Перезагрузите компьютер с загрузочными флагами GRUB
nmi_watchdog=0 modprobe.blacklist=iTCO_wdt,iTCO_vendor_support, В противном случае сторожевой таймер NMI повлияет на счетчик циклов unhalted-core. insmod perfcount.koмодуль.dmesg | tail -n 10должен сказать, что он успешно загружен, и сказать, что есть 3 Ff-счетчика и 4 Gp-счетчика, или указать причину неудачи.- Запустите мое приложение, желательно, пока остальная часть системы не загружена. Попробуйте также изменить в
perfcountdemo.cядро, которым вы ограничиваете свою близость, изменяя аргумент наpfcPinThread(), - Отредактируйте здесь результаты.
Обновление: предыдущая версия содержала 6 VPADDD инструкции (против 5 в вопросе) и дополнительные VPADDD вызвал дисбаланс на Бродвеле. После исправления Haswell, Broadwell и Skylake выдают почти одинаковое количество мопов на порты 0, 1 и 5.
Загрязнения портов не происходит, но мопы планируются неоптимально, при этом большинство мопов отправляются в порт 5 на Бродвелле и делают это узким местом до насыщения портов 0 и 1.
Чтобы продемонстрировать, что происходит, я предлагаю (ab) использовать демонстрационную версию PeachPy.IO:
Откройте www.peachpy.io в Google Chrome (он не будет работать в других браузерах).
Замените код по умолчанию (который реализует функцию SDOT) приведенным ниже кодом, который буквально является вашим примером, портированным на синтаксис PeachPy:
n = Argument(size_t) x = Argument(ptr(const_float_)) incx = Argument(size_t) y = Argument(ptr(const_float_)) incy = Argument(size_t) with Function("sdot", (n, x, incx, y, incy)) as function: reg_n = GeneralPurposeRegister64() LOAD.ARGUMENT(reg_n, n) VZEROALL() with Loop() as loop: for i in range(15): ymm_i = YMMRegister(i) if i < 10: VFMADD231PS(ymm_i, ymm_i, ymm_i) else: VPADDD(ymm_i, ymm_i, ymm_i) DEC(reg_n) JNZ(loop.begin) RETURN()У меня есть несколько машин на разных микроархитектурах в качестве бэкэнда для PeachPy.io. Выберите Intel Haswell, Intel Broadwell или Intel Skylake и нажмите "Быстрый запуск". Система скомпилирует ваш код, загрузит его на сервер и визуализирует счетчики производительности, собранные во время выполнения.
Вот распределение мопов по портам выполнения на Intel Haswell:

- И вот тот же сюжет от Intel Broadwell:

- По-видимому, какой бы ни был недостаток в планировщике мопов, он был исправлен в Intel Skylake, потому что давление порта на этой машине такое же, как на Haswell.