Как я могу горячо кодировать в Python?
У меня есть проблема классификации машинного обучения с 80% категориальных переменных. Должен ли я использовать одну горячую кодировку, если я хочу использовать какой-то классификатор для классификации? Могу ли я передать данные в классификатор без кодировки?
Я пытаюсь сделать следующее для выбора функции:
Я прочитал файл поезда:
num_rows_to_read = 10000 train_small = pd.read_csv("../../dataset/train.csv", nrows=num_rows_to_read)Я изменяю тип категориальных функций на "категория":
non_categorial_features = ['orig_destination_distance', 'srch_adults_cnt', 'srch_children_cnt', 'srch_rm_cnt', 'cnt'] for categorical_feature in list(train_small.columns): if categorical_feature not in non_categorial_features: train_small[categorical_feature] = train_small[categorical_feature].astype('category')Я использую одну горячую кодировку:
train_small_with_dummies = pd.get_dummies(train_small, sparse=True)
Проблема в том, что 3-я часть часто застревает, хотя я использую сильную машину.
Таким образом, без одного горячего кодирования я не смогу сделать какой-либо выбор функции для определения важности функций.
Что вы порекомендуете?
22 ответа
Подход 1: Вы можете использовать get_dummies на кадре данных панд.
Пример 1:
import pandas as pd
s = pd.Series(list('abca'))
pd.get_dummies(s)
Out[]:
a b c
0 1.0 0.0 0.0
1 0.0 1.0 0.0
2 0.0 0.0 1.0
3 1.0 0.0 0.0
Пример 2:
Следующее преобразует данный столбец в один горячий. Используйте префикс для нескольких манекенов.
import pandas as pd
df = pd.DataFrame({
'A':['a','b','a'],
'B':['b','a','c']
})
df
Out[]:
A B
0 a b
1 b a
2 a c
# Get one hot encoding of columns B
one_hot = pd.get_dummies(df['B'])
# Drop column B as it is now encoded
df = df.drop('B',axis = 1)
# Join the encoded df
df = df.join(one_hot)
df
Out[]:
A a b c
0 a 0 1 0
1 b 1 0 0
2 a 0 0 1
Подход 2: Используйте Scikit-Learn
Учитывая набор данных с тремя признаками и четырьмя выборками, мы позволяем кодировщику найти максимальное значение для признака и преобразовать данные в двоичное кодирование в горячем режиме.
>>> from sklearn.preprocessing import OneHotEncoder
>>> enc = OneHotEncoder()
>>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
OneHotEncoder(categorical_features='all', dtype=<class 'numpy.float64'>,
handle_unknown='error', n_values='auto', sparse=True)
>>> enc.n_values_
array([2, 3, 4])
>>> enc.feature_indices_
array([0, 2, 5, 9], dtype=int32)
>>> enc.transform([[0, 1, 1]]).toarray()
array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.]])
Вот ссылка для этого примера: http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
Гораздо проще использовать Pandas для базового однократного кодирования. Если вы ищете больше вариантов, вы можете использовать scikit-learn.
Для базового однократного кодирования с помощью Pandas вы просто передаете свой фрейм данных в функцию get_dummies.
Например, если у меня есть датафрейм с именем imdb_movies:

... и я хочу горячо закодировать столбец Rated, я просто делаю это:
pd.get_dummies(imdb_movies.Rated)
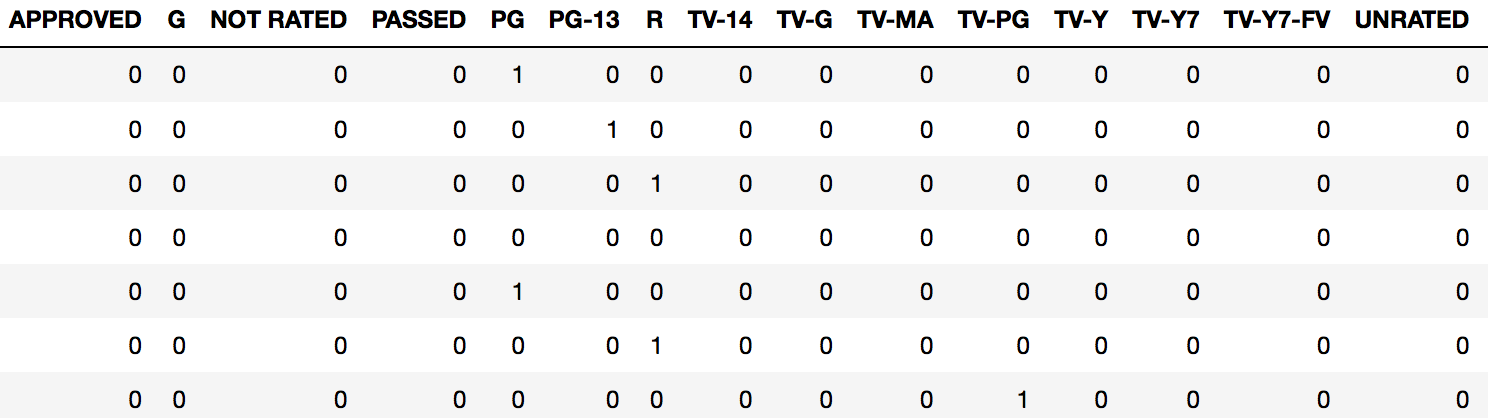
Это возвращает новый фрейм данных со столбцом для каждого существующего " уровня " рейтинга, а также 1 или 0, указывающий наличие этого рейтинга для данного наблюдения.
Обычно мы хотим, чтобы это было частью исходного кадра данных. В этом случае мы просто присоединяем наш новый фиктивный кадр к исходному кадру, используя " привязку столбцов".
Мы можем связать столбцы, используя функцию Pandas concat:
rated_dummies = pd.get_dummies(imdb_movies.Rated)
pd.concat([imdb_movies, rated_dummies], axis=1)
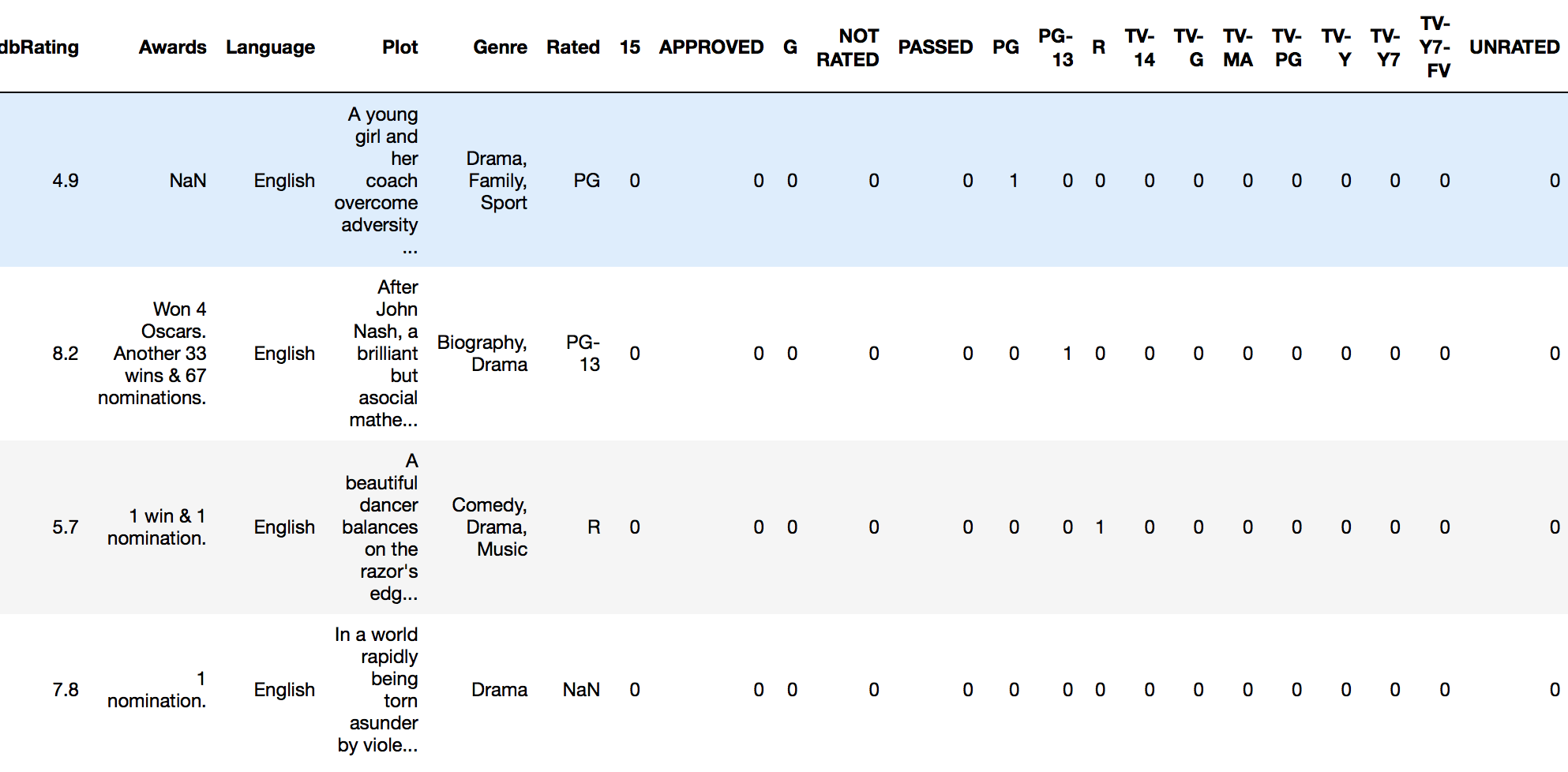
Теперь мы можем запустить анализ на нашем полном кадре данных.
ПРОСТАЯ ФУНКЦИЯ УТИЛИТЫ
Я бы порекомендовал сделать себе полезную функцию, чтобы сделать это быстро:
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
return(res)
Использование:
encode_and_bind(imdb_movies, 'Rated')
Результат:

Вы можете сделать это с numpy.eye и использование механизма выбора элементов массива:
import numpy as np
nb_classes = 6
data = [[2, 3, 4, 0]]
def indices_to_one_hot(data, nb_classes):
"""Convert an iterable of indices to one-hot encoded labels."""
targets = np.array(data).reshape(-1)
return np.eye(nb_classes)[targets]
Возвращаемое значение indices_to_one_hot(nb_classes, data) сейчас
array([[[ 0., 0., 1., 0., 0., 0.],
[ 0., 0., 0., 1., 0., 0.],
[ 0., 0., 0., 0., 1., 0.],
[ 1., 0., 0., 0., 0., 0.]]])
.reshape(-1) чтобы убедиться, что у вас есть правильный формат меток (вы также можете иметь [[2], [3], [4], [0]]).
Одно горячее кодирование с пандами очень просто:
def one_hot(df, cols):
"""
@param df pandas DataFrame
@param cols a list of columns to encode
@return a DataFrame with one-hot encoding
"""
for each in cols:
dummies = pd.get_dummies(df[each], prefix=each, drop_first=False)
df = pd.concat([df, dummies], axis=1)
return df
РЕДАКТИРОВАТЬ:
Еще один способ one_hot, используя склеарн LabelBinarizer:
from sklearn.preprocessing import LabelBinarizer
label_binarizer = LabelBinarizer()
label_binarizer.fit(all_your_labels_list) # need to be global or remembered to use it later
def one_hot_encode(x):
"""
One hot encode a list of sample labels. Return a one-hot encoded vector for each label.
: x: List of sample Labels
: return: Numpy array of one-hot encoded labels
"""
return label_binarizer.transform(x)
Во-первых, самый простой способ горячего кодирования: используйте Sklearn.
http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
Во-вторых, я не думаю, что использование панд для горячего кодирования настолько просто (хотя и не подтверждено)
Создание фиктивных переменных в пандах для python
Наконец, нужно ли вам одно горячее кодирование? Одно горячее кодирование экспоненциально увеличивает число функций, резко увеличивая время выполнения любого классификатора или чего-либо еще, что вы собираетесь запустить. Особенно, когда каждая категориальная особенность имеет много уровней. Вместо этого вы можете сделать фиктивное кодирование.
Использование фиктивного кодирования обычно работает хорошо, для гораздо меньшего времени выполнения и сложности. Один мудрый профессор однажды сказал мне: "Меньше значит больше".
Вот код для моей пользовательской функции кодирования, если хотите.
from sklearn.preprocessing import LabelEncoder
#Auto encodes any dataframe column of type category or object.
def dummyEncode(df):
columnsToEncode = list(df.select_dtypes(include=['category','object']))
le = LabelEncoder()
for feature in columnsToEncode:
try:
df[feature] = le.fit_transform(df[feature])
except:
print('Error encoding '+feature)
return df
РЕДАКТИРОВАТЬ: Сравнение будет понятнее:
Горячее кодирование: преобразование n уровней в n-1 столбцы.
Index Animal Index cat mouse
1 dog 1 0 0
2 cat --> 2 1 0
3 mouse 3 0 1
Вы можете увидеть, как это взорвет вашу память, если у вас есть много разных типов (или уровней) в вашей категориальной функции. Имейте в виду, это только одна колонка.
Фиктивная кодировка:
Index Animal Index Animal
1 dog 1 0
2 cat --> 2 1
3 mouse 3 2
Вместо этого преобразуйте в числовые представления. Значительно экономит пространство функций за счет небольшой точности.
Вы можете использовать функцию numpy.eye.
import numpy as np
def one_hot_encode(x, n_classes):
"""
One hot encode a list of sample labels. Return a one-hot encoded vector for each label.
: x: List of sample Labels
: return: Numpy array of one-hot encoded labels
"""
return np.eye(n_classes)[x]
def main():
list = [0,1,2,3,4,3,2,1,0]
n_classes = 5
one_hot_list = one_hot_encode(list, n_classes)
print(one_hot_list)
if __name__ == "__main__":
main()
Результат
D:\Desktop>python test.py
[[ 1. 0. 0. 0. 0.]
[ 0. 1. 0. 0. 0.]
[ 0. 0. 1. 0. 0.]
[ 0. 0. 0. 1. 0.]
[ 0. 0. 0. 0. 1.]
[ 0. 0. 0. 1. 0.]
[ 0. 0. 1. 0. 0.]
[ 0. 1. 0. 0. 0.]
[ 1. 0. 0. 0. 0.]]
pandas as имеет встроенную функцию "get_dummies", чтобы получить одну горячую кодировку этого конкретного столбца / столбцов.
однострочный код для горячего кодирования:
df=pd.concat([df,pd.get_dummies(df['column name'],prefix='column name')],axis=1).drop(['column name'],axis=1)
Вот решение с использованием DictVectorizer и панды DataFrame.to_dict('records') метод.
>>> import pandas as pd
>>> X = pd.DataFrame({'income': [100000,110000,90000,30000,14000,50000],
'country':['US', 'CAN', 'US', 'CAN', 'MEX', 'US'],
'race':['White', 'Black', 'Latino', 'White', 'White', 'Black']
})
>>> from sklearn.feature_extraction import DictVectorizer
>>> v = DictVectorizer()
>>> qualitative_features = ['country','race']
>>> X_qual = v.fit_transform(X[qualitative_features].to_dict('records'))
>>> v.vocabulary_
{'country=CAN': 0,
'country=MEX': 1,
'country=US': 2,
'race=Black': 3,
'race=Latino': 4,
'race=White': 5}
>>> X_qual.toarray()
array([[ 0., 0., 1., 0., 0., 1.],
[ 1., 0., 0., 1., 0., 0.],
[ 0., 0., 1., 0., 1., 0.],
[ 1., 0., 0., 0., 0., 1.],
[ 0., 1., 0., 0., 0., 1.],
[ 0., 0., 1., 1., 0., 0.]])
Вы также можете сделать следующее. Обратите внимание на то, что ниже вам не нужно использоватьpd.concat.
import pandas as pd
# intialise data of lists.
data = {'Color':['Red', 'Yellow', 'Red', 'Yellow'], 'Length':[20.1, 21.1, 19.1, 18.1],
'Group':[1,2,1,2]}
# Create DataFrame
df = pd.DataFrame(data)
for _c in df.select_dtypes(include=['object']).columns:
print(_c)
df[_c] = pd.Categorical(df[_c])
df_transformed = pd.get_dummies(df)
df_transformed
Вы также можете изменить явные столбцы на категориальные. Например, здесь я меняюColor а также Group
import pandas as pd
# intialise data of lists.
data = {'Color':['Red', 'Yellow', 'Red', 'Yellow'], 'Length':[20.1, 21.1, 19.1, 18.1],
'Group':[1,2,1,2]}
# Create DataFrame
df = pd.DataFrame(data)
columns_to_change = list(df.select_dtypes(include=['object']).columns)
columns_to_change.append('Group')
for _c in columns_to_change:
print(_c)
df[_c] = pd.Categorical(df[_c])
df_transformed = pd.get_dummies(df)
df_transformed
Горячее кодирование требует чуть больше, чем преобразование значений в индикаторные переменные. Как правило, процесс ML требует от вас применения этого кодирования несколько раз для валидации или тестирования наборов данных и применения построенной вами модели к наблюдаемым данным в реальном времени. Вы должны сохранить отображение (преобразование), которое использовалось для построения модели. Хорошее решение будет использовать DictVectorizer или же LabelEncoder (с последующим get_dummies, Вот функция, которую вы можете использовать:
def oneHotEncode2(df, le_dict = {}):
if not le_dict:
columnsToEncode = list(df.select_dtypes(include=['category','object']))
train = True;
else:
columnsToEncode = le_dict.keys()
train = False;
for feature in columnsToEncode:
if train:
le_dict[feature] = LabelEncoder()
try:
if train:
df[feature] = le_dict[feature].fit_transform(df[feature])
else:
df[feature] = le_dict[feature].transform(df[feature])
df = pd.concat([df,
pd.get_dummies(df[feature]).rename(columns=lambda x: feature + '_' + str(x))], axis=1)
df = df.drop(feature, axis=1)
except:
print('Error encoding '+feature)
#df[feature] = df[feature].convert_objects(convert_numeric='force')
df[feature] = df[feature].apply(pd.to_numeric, errors='coerce')
return (df, le_dict)
Это работает на фрейме данных pandas и для каждого столбца фрейма данных создает и возвращает отображение обратно. Итак, вы бы назвали это так:
train_data, le_dict = oneHotEncode2(train_data)
Затем по тестовым данным вызов выполняется путем передачи словаря, возвращенного из обучения:
test_data, _ = oneHotEncode2(test_data, le_dict)
Эквивалентный метод заключается в использовании DictVectorizer, Соответствующий пост на том же есть в моем блоге. Я упоминаю об этом здесь, так как он предоставляет некоторые аргументы в пользу этого подхода, а не просто использования сообщения get_dummies (раскрытие: это мой собственный блог).
Вы можете передавать данные в классификатор catboost без кодирования. Catboost сам обрабатывает категориальные переменные, выполняя однозначное и целевое расширяющее среднее кодирование.
Попробуй это:
!pip install category_encoders
import category_encoders as ce
categorical_columns = [...the list of names of the columns you want to one-hot-encode ...]
encoder = ce.OneHotEncoder(cols=categorical_columns, use_cat_names=True)
df_train_encoded = encoder.fit_transform(df_train_small)
df_encoded.head()
Результирующий фрейм данных df_train_encoded такой же, как и оригинал, но категориальные функции теперь заменены их версиями с горячим кодированием.
Больше информации о category_encoders здесь.
Я знаю, что опоздал на эту вечеринку, но самый простой способ автоматически кодировать фрейм данных - использовать эту функцию:
def hot_encode(df):
obj_df = df.select_dtypes(include=['object'])
return pd.get_dummies(df, columns=obj_df.columns).values
Это работает для меня:
pandas.factorize( ['B', 'C', 'D', 'B'] )[0]
Выход:
[0, 1, 2, 0]
Я использовал это в своей акустической модели: вероятно, это помогает в вашей модели.
def one_hot_encoding(x, n_out):
x = x.astype(int)
shape = x.shape
x = x.flatten()
N = len(x)
x_categ = np.zeros((N,n_out))
x_categ[np.arange(N), x] = 1
return x_categ.reshape((shape)+(n_out,))
Короткий ответ
Вот функция для выполнения однократного кодирования без использования numpy, pandas или других пакетов. Он принимает список целых чисел, логических значений или строк (а также, возможно, других типов).
import typing
def one_hot_encode(items: list) -> typing.List[list]:
results = []
# find the unique items (we want to unique items b/c duplicate items will have the same encoding)
unique_items = list(set(items))
# sort the unique items
sorted_items = sorted(unique_items)
# find how long the list of each item should be
max_index = len(unique_items)
for item in items:
# create a list of zeros the appropriate length
one_hot_encoded_result = [0 for i in range(0, max_index)]
# find the index of the item
one_hot_index = sorted_items.index(item)
# change the zero at the index from the previous line to a one
one_hot_encoded_result[one_hot_index] = 1
# add the result
results.append(one_hot_encoded_result)
return results
Пример:
one_hot_encode([2, 1, 1, 2, 5, 3])
# [[0, 1, 0, 0],
# [1, 0, 0, 0],
# [1, 0, 0, 0],
# [0, 1, 0, 0],
# [0, 0, 0, 1],
# [0, 0, 1, 0]]
one_hot_encode([True, False, True])
# [[0, 1], [1, 0], [0, 1]]
one_hot_encode(['a', 'b', 'c', 'a', 'e'])
# [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [1, 0, 0, 0], [0, 0, 0, 1]]
Длинный (эр) ответ
Я знаю, что на этот вопрос уже есть много ответов, но я заметил две вещи. Во-первых, в большинстве ответов используются такие пакеты, как numpy и / или pandas. И это хорошо. Если вы пишете производственный код, вам, вероятно, следует использовать надежные и быстрые алгоритмы, подобные тем, которые представлены в пакетах numpy/pandas. Но я считаю, что ради образования кто-то должен дать ответ, который имеет прозрачный алгоритм, а не просто реализацию чужого алгоритма. Во-вторых, я заметил, что многие ответы не обеспечивают надежной реализации однократного кодирования, потому что они не соответствуют одному из требований ниже. Ниже приведены некоторые требования (как я их вижу) для полезной, точной и надежной функции однократного кодирования:
Функция однократного кодирования должна:
- обрабатывать список различных типов (например, целые числа, строки, числа с плавающей запятой и т. д.) в качестве входных данных
- обрабатывать список ввода с дубликатами
- вернуть список списков, соответствующих (в том же порядке, что и) входам
- вернуть список списков, где каждый список как можно короче
Я проверил многие ответы на этот вопрос, и большинство из них не соответствуют одному из приведенных выше требований.
Расширение ответа @Martin Thoma
def one_hot_encode(y):
"""Convert an iterable of indices to one-hot encoded labels."""
y = y.flatten() # Sometimes not flattened vector is passed e.g (118,1) in these cases
# the function ends up creating a tensor e.g. (118, 2, 1). flatten removes this issue
nb_classes = len(np.unique(y)) # get the number of unique classes
standardised_labels = dict(zip(np.unique(y), np.arange(nb_classes))) # get the class labels as a dictionary
# which then is standardised. E.g imagine class labels are (4,7,9) if a vector of y containing 4,7 and 9 is
# directly passed then np.eye(nb_classes)[4] or 7,9 throws an out of index error.
# standardised labels fixes this issue by returning a dictionary;
# standardised_labels = {4:0, 7:1, 9:2}. The values of the dictionary are mapped to keys in y array.
# standardised_labels also removes the error that is raised if the labels are floats. E.g. 1.0; element
# cannot be called by an integer index e.g y[1.0] - throws an index error.
targets = np.vectorize(standardised_labels.get)(y) # map the dictionary values to array.
return np.eye(nb_classes)[targets]
Чтобы добавить к другим вопросам, позвольте мне рассказать, как я это сделал с помощью функции Python 2.0 с использованием Numpy:
def one_hot(y_):
# Function to encode output labels from number indexes
# e.g.: [[5], [0], [3]] --> [[0, 0, 0, 0, 0, 1], [1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0]]
y_ = y_.reshape(len(y_))
n_values = np.max(y_) + 1
return np.eye(n_values)[np.array(y_, dtype=np.int32)] # Returns FLOATS
Линия n_values = np.max(y_) + 1 может быть жестко закодировано для вас, чтобы использовать большое количество нейронов в случае, если вы используете, например, мини-партии.
Демонстрационный проект / учебное пособие, где использовалась эта функция: https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition
Это может и должно быть легко, как:
class OneHotEncoder:
def __init__(self,optionKeys):
length=len(optionKeys)
self.__dict__={optionKeys[j]:[0 if i!=j else 1 for i in range(length)] for j in range(length)}
Использование:
ohe=OneHotEncoder(["A","B","C","D"])
print(ohe.A)
print(ohe.D)
Предположим, что из 10 переменных у вас есть 3 категориальные переменные в вашем фрейме данных с именами cname1, cname2 и cname3. Затем следующий код автоматически создаст одну переменную с горячим кодированием в новом фрейме данных.
import category_encoders as ce
encoder_var=ce.OneHotEncoder(cols=['cname1','cname2','cname3'],handle_unknown='return_nan',return_df=True,use_cat_names=True)
new_df = encoder_var.fit_transform(old_df)
Простой пример использования векторизации в numpy и применения примера в пандах:
import numpy as np
a = np.array(['male','female','female','male'])
#define function
onehot_function = lambda x: 1.0 if (x=='male') else 0.0
onehot_a = np.vectorize(onehot_function)(a)
print(onehot_a)
# [1., 0., 0., 1.]
# -----------------------------------------
import pandas as pd
s = pd.Series(['male','female','female','male'])
onehot_s = s.apply(onehot_function)
print(onehot_s)
# 0 1.0
# 1 0.0
# 2 0.0
# 3 1.0
# dtype: float64
Здесь я попробовал с этим подходом:
import numpy as np
#converting to one_hot
def one_hot_encoder(value, datal):
datal[value] = 1
return datal
def _one_hot_values(labels_data):
encoded = [0] * len(labels_data)
for j, i in enumerate(labels_data):
max_value = [0] * (np.max(labels_data) + 1)
encoded[j] = one_hot_encoder(i, max_value)
return np.array(encoded)