Параллельность в CUDA для нескольких GPU
Я запускаю функцию ядра cuda в системе с несколькими графическими процессорами, с 4 Графические процессоры. Я ожидал, что они будут запущены одновременно, но это не так. Я измеряю время запуска каждого ядра, и второе ядро запускается после того, как первое завершает свое выполнение. Итак, запуск ядра на 4 GPU не быстрее чем 1 одиночный графический процессор
Как я могу заставить их работать одновременно?
Это мой код:
cudaSetDevice(0);
GPU_kernel<<< gridDim, threadsPerBlock >>>(d_result_0, parameterA +(0*rateA), parameterB + (0*rateB));
cudaMemcpyAsync(h_result_0, d_result_0, mem_size_result, cudaMemcpyDeviceToHost);
cudaSetDevice(1);
GPU_kernel<<< gridDim, threadsPerBlock >>>(d_result_1, parameterA +(1*rateA), parameterB + (1*rateB));
cudaMemcpyAsync(h_result_1, d_result_1, mem_size_result, cudaMemcpyDeviceToHost);
cudaSetDevice(2);
GPU_kernel<<< gridDim, threadsPerBlock >>>(d_result_2, parameterA +(2*rateA), parameterB + (2*rateB));
cudaMemcpyAsync(h_result_2, d_result_2, mem_size_result, cudaMemcpyDeviceToHost);
cudaSetDevice(3);
GPU_kernel<<< gridDim, threadsPerBlock >>>(d_result_3, parameterA +(3*rateA), parameterB + (3*rateB));
cudaMemcpyAsync(h_result_3, d_result_3, mem_size_result, cudaMemcpyDeviceToHost);
2 ответа
Я провел несколько экспериментов по достижению одновременного выполнения на кластере 4 Графические процессоры Kepler K20c. Я рассмотрел 8 тестовые случаи, соответствующие коды которых вместе с временными шкалами профилировщика представлены ниже.
Тестовый пример № 1 - подход "в ширину" - синхронная копия
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices = (double *)malloc(N * sizeof(double));
// --- "Breadth-first" approach - no async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля - 
Как видно, использование cudaMemcpy не позволяет достичь параллелизма в копиях, но параллелизм достигается при выполнении ядра.
Контрольный пример № 2 - подход "Глубина-первая" - синхронная копия
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
double *inputMatrices = (double *)malloc(N * sizeof(double));
// --- "Depth-first" approach - no async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpy(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpy(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля -

На этот раз параллелизм не достигается ни в копиях памяти, ни в ядрах.
Тестовый пример № 3 - подход "Глубина-первая" - асинхронное копирование с потоками
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
T *h_data;
cudaStream_t stream;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
gpuErrchk(cudaStreamCreate(&plan.stream));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Depth-first" approach - async
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice, plan[k].stream));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE, 0, plan[k].stream>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost, plan[k].stream));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля -

Параллельность достигается, как и ожидалось.
Контрольный пример № 4 - подход "Глубина-первая" - асинхронное копирование в потоках по умолчанию
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
T *h_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Depth-first" approach - no stream
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля -

Несмотря на использование потока по умолчанию, достигается параллелизм.
Тестовый пример № 5 - подход "Глубина-первая" - асинхронное копирование в потоке по умолчанию и на уникальном хосте cudaMallocHost ред вектор
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Depth-first" approach - no stream
double *inputMatrices; gpuErrchk(cudaMallocHost(&inputMatrices, N * sizeof(double)));
for (int k = 0; k < numGPUs; k++)
{
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
gpuErrchk(cudaMemcpyAsync(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля -

Параллельность достигается еще раз.
Тестовый пример № 6 - подход "в ширину" с асинхронным копированием с потоками
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
// --- Async
template<class T>
struct plan {
T *d_data;
T *h_data;
cudaStream_t stream;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
gpuErrchk(cudaStreamCreate(&plan.stream));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Breadth-first" approach - async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice, plan[k].stream));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE, 0, plan[k].stream>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost, plan[k].stream));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля -

Достигнута параллелизм, как в соответствующем подходе "сначала глубина".
Тестовый пример № 7 - подход "в ширину" - асинхронное копирование в потоках по умолчанию
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
// --- Async
template<class T>
struct plan {
T *d_data;
T *h_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
gpuErrchk(cudaMallocHost((void **)&plan.h_data, NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Breadth-first" approach - async
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, plan[k].h_data, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].h_data, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля -
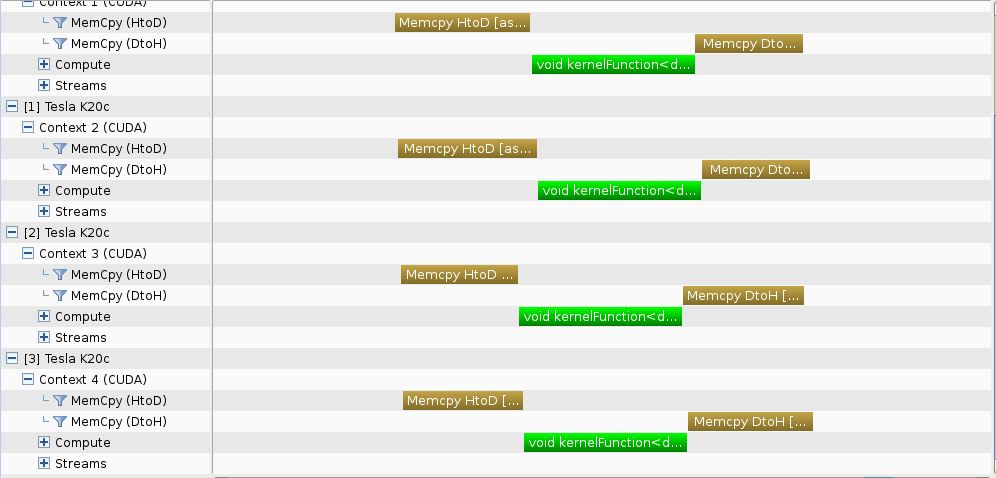
Параллелизм достигается, как в соответствующем подходе "сначала глубина".
Контрольный пример № 8 - подход "в ширину" - асинхронная копия в потоке по умолчанию и на уникальном хосте cudaMallocHost ред вектор
- код -
#include "Utilities.cuh"
#include "InputOutput.cuh"
#define BLOCKSIZE 128
/*******************/
/* KERNEL FUNCTION */
/*******************/
template<class T>
__global__ void kernelFunction(T * __restrict__ d_data, const unsigned int NperGPU) {
const int tid = threadIdx.x + blockIdx.x * blockDim.x;
if (tid < NperGPU) for (int k = 0; k < 1000; k++) d_data[tid] = d_data[tid] * d_data[tid];
}
/******************/
/* PLAN STRUCTURE */
/******************/
// --- Async
template<class T>
struct plan {
T *d_data;
};
/*********************/
/* SVD PLAN CREATION */
/*********************/
template<class T>
void createPlan(plan<T>& plan, unsigned int NperGPU, unsigned int gpuID) {
// --- Device allocation
gpuErrchk(cudaSetDevice(gpuID));
gpuErrchk(cudaMalloc(&(plan.d_data), NperGPU * sizeof(T)));
}
/********/
/* MAIN */
/********/
int main() {
const int numGPUs = 4;
const int NperGPU = 500000;
const int N = NperGPU * numGPUs;
plan<double> plan[numGPUs];
for (int k = 0; k < numGPUs; k++) createPlan(plan[k], NperGPU, k);
// --- "Breadth-first" approach - async
double *inputMatrices; gpuErrchk(cudaMallocHost(&inputMatrices, N * sizeof(double)));
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(plan[k].d_data, inputMatrices + k * NperGPU, NperGPU * sizeof(double), cudaMemcpyHostToDevice));
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
kernelFunction<<<iDivUp(NperGPU, BLOCKSIZE), BLOCKSIZE>>>(plan[k].d_data, NperGPU);
}
for (int k = 0; k < numGPUs; k++) {
gpuErrchk(cudaSetDevice(k));
gpuErrchk(cudaMemcpyAsync(inputMatrices + k * NperGPU, plan[k].d_data, NperGPU * sizeof(double), cudaMemcpyDeviceToHost));
}
gpuErrchk(cudaDeviceReset());
}
- Хронология профиля -

Параллелизм достигается, как в соответствующем подходе "сначала глубина".
Заключение Использование асинхронных копий гарантирует одновременное выполнение либо с использованием специально созданных потоков, либо с использованием потока по умолчанию.
Примечание. Во всех приведенных выше примерах я позаботился о том, чтобы обеспечить достаточное количество работы для графических процессоров, будь то копирование или вычислительные задачи. Отсутствие достаточной работы для кластера может помешать наблюдению за одновременным выполнением.
Возможно, вам придется использовать cudaMemcpyAsync, cudaMemcpy блокирует вызов, поэтому он не возвращает выполнение вашему коду до его завершения, поэтому ваш код просто не переключает графический процессор, пока не завершит процедуру для текущего.
Тем не менее, вызовы ядра являются асинхронными (для ЦП), поэтому размещенный вами код может вызывать некоторые гоночные условия ( cudaMemcpy может начать выполнение до завершения работы ядра). Как отметил @talonmies в комментариях, так как cudaMemcpy / cudaMemcpyAsync идет в тот же поток, что и запуск ядра, все выполняется в правильном порядке.
Я бы порекомендовал вам использовать CUDA Streams; Вот краткое введение в программирование MultiGPU с использованием потоков. Это не очень полезно в вашем случае, но может быть очень удобно для использования в более сложных приложениях, например, если вам нужно синхронизировать вызовы функций между различными устройствами.