Как убрать застрявших / устаревших работников Resque?
Как видно из прикрепленного изображения, у меня есть пара рабочих, которые, похоже, застряли. Эти процессы не должны занимать больше пары секунд.
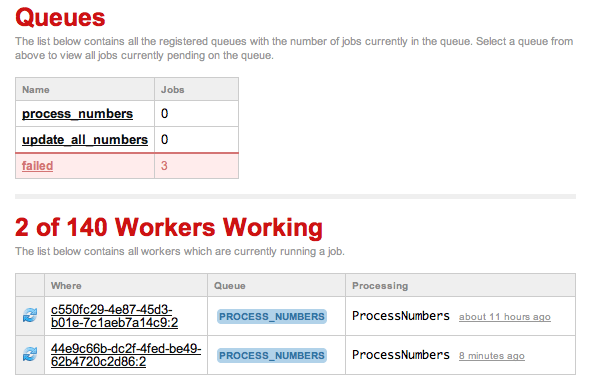
Я не уверен, почему они не будут очищены или как их вручную удалить.
Я на Heroku использую Resque с Redis-to-Go и HireFire для автоматического масштабирования рабочих.
17 ответов
Ни одно из этих решений не работало для меня, я все еще видел бы это в redis-web:
0 out of 10 Workers Working
Наконец, это помогло мне очистить всех рабочих:
Resque.workers.each {|w| w.unregister_worker}
В вашей консоли:
queue_name = "process_numbers"
Resque.redis.del "queue:#{queue_name}"
В противном случае вы можете попытаться подделать их как выполненные, чтобы удалить их, с помощью:
Resque::Worker.working.each {|w| w.done_working}
РЕДАКТИРОВАТЬ
Многие люди проголосовали против этого ответа, и я чувствую, что важно, чтобы люди попробовали решение hagope, которое отменяет регистрацию работников вне очереди, тогда как приведенный выше код удаляет очереди. Если ты счастлив имитировать их, тогда круто.
Возможно, у вас установлен Resque Gem, так что вы можете открыть консоль и получить текущие рабочие
Resque.workers
Возвращает список работников
#=> [#<Worker infusion.local:40194-0:JAVA_DYNAMIC_QUEUES,index_migrator,converter,extractor>]
выбрать работника и prune_dead_workersнапример первый
Resque.workers.first.prune_dead_workers
Добавляя ответить hagope, я хотел иметь возможность отменить регистрацию только тех работников, которые работали в течение определенного времени. Приведенный ниже код отменяет регистрацию только рабочих, работающих более 300 секунд (5 минут).
Resque.workers.each {|w| w.unregister_worker if w.processing['run_at'] && Time.now - w.processing['run_at'].to_time > 300}
У меня есть текущая коллекция задач Rake, связанных с Resque, к которым я также добавил это: https://gist.github.com/ewherrmann/8809350
Запускайте эту команду везде, где вы запускали команду для запуска сервера
$ ps -e -o pid,command | grep [r]esque
вы должны увидеть что-то вроде этого:
92102 resque: Processing ProcessNumbers since 1253142769
Запишите PID (идентификатор процесса) в моем примере это 92102
Тогда вы можете выйти из процесса 1 из 2 способов.
Изящно использовать
QUIT 92102Принудительно использовать
TERM 92102
* Я не уверен в синтаксисе это либо QUIT 92102 или же QUIT -92102
Дайте мне знать, если у вас возникнут проблемы.
Я только что сделал:
% rails c production
irb(main):001:0>Resque.workers
Получил список работников.
irb(main):002:0>Resque.remove_worker(Resque.workers[n].id)
... где n - нулевой индекс нежелательного работника.
Я столкнулся с этой проблемой и пошел по пути реализации многих предложений здесь. Тем не менее, я обнаружил, что основной причиной, которая создавала эту проблему, было то, что я использовал gem redis-rb 3.3.0. Понижение до redis-rb 3.2.2 не позволило этим работникам застрять в первую очередь.
Недавно начал работать над https://github.com/shaiguitar/resque_stuck_queue/. Это не решение того, как исправить застрявших рабочих, но оно решает проблему зависания / зависания в реске, поэтому я подумал, что это может быть полезно для людей в этой теме. От README:
"Если resque не запускает задания в течение определенного периода времени, он вызовет предопределенный обработчик по вашему выбору. Вы можете использовать это для отправки электронной почты, обязанности пейджера, добавления дополнительных работников resque, перезапуска resque, отправки вам текста.... все, что тебе подходит."
Используется в производстве и пока работает для меня довольно хорошо.
Вот как вы можете удалить их из Redis по имени хоста. Это происходит со мной, когда я списываю сервер, и рабочие не выходят изящно.
Resque.workers.each { |w| w.unregister_worker if w.id.start_with?(hostname) }
У меня была похожая проблема, что Redis сохранил БД на диск, который содержал недействительных (не работающих) рабочих. Каждый раз, когда Redis/ Resque был запущен, они появлялись.
Исправьте это, используя:
Resque::Worker.working.each {|w| w.done_working}
Resque.redis.save # Save the DB to disk without ANY workers
Убедитесь, что вы перезапустили Redis и ваших сотрудников Resque.
В resque 2.0.0 есть один способ, который, кажется, работает для удаления только фактически кажущихся мертвыми рабочих в resque 2.0.0:
Resque::Worker.all_workers_with_expired_heartbeats.each { |w| w.unregister_worker }
Я не эксперт в том, что происходит, возможно, есть лучший способ сделать то или иное, что будет иметь проблемы. Я тоже пытаюсь понять это.
Похоже, это удаляет рабочих, которые не отправляли «сердцебиение» намного дольше, чем ожидалось, из списка восстановленных рабочих .
Если фантомный рабочий находился в состоянии «запущен», то в очереди «сбойных» заданий будет создана новая запись, соответствующая фантомному заданию.
Я очистил их от Redis-Cli напрямую. К счастью, redistogo.com позволяет получить доступ из среды вне герои. Получить идентификатор мертвого работника из списка. Мой был
55ba6f3b-9287-4f81-987a-4e8ae7f51210:2
Запустите эту команду в Redis напрямую.
del "resque:worker:55ba6f3b-9287-4f81-987a-4e8ae7f51210:2:*"
Вы можете отслеживать redis db, чтобы увидеть, что он делает за кулисами.
redis xxx.redistogo.com> MONITOR
OK
1380274567.540613 "MONITOR"
1380274568.345198 "incrby" "resque:stat:processed" "1"
1380274568.346898 "incrby" "resque:stat:processed:c65c8e2b-555a-4a57-aaa6-477b27d6452d:2:*" "1"
1380274568.346920 "del" "resque:worker:c65c8e2b-555a-4a57-aaa6-477b27d6452d:2:*"
1380274568.348803 "smembers" "resque:queues"
Вторая последняя строка удаляет работника.
Я тоже застрял / устарел, и я должен сказать "рабочие места", потому что работник на самом деле все еще там и работает нормально, это застрявший процесс.
Я выбрал жестокое решение по уничтожению разветвленного процесса "Обработка", так как более 5 минут с помощью bash-скрипта работник просто порождает следующего в очереди, и все продолжается
посмотрите мой сценарий здесь: https://gist.github.com/jobwat/5712437
Вы также можете использовать команду ниже, чтобы остановить все rescue работник
sudo kill -9 `ps aux | grep resque | grep -v grep | cut -c 10-16`
Если вы используете более новые версии Resque, вам нужно будет использовать следующую команду, поскольку внутренние API изменились...
Resque::WorkerRegistry.working.each {|work| Resque::WorkerRegistry.remove(work.id)}
Это позволяет избежать проблемы до тех пор, пока у вас есть версия Resque, более новая, чем 1.26.0:
resque: env QUEUE=foo TERM_CHILD=1 bundle exec rake resque:work
Имейте в виду, что это не позволяет текущему заданию завершиться.
Если вы используете Docker, вы также можете использовать эту команду:
<id> это идентификатор рабочего.
docker stop <id>
docker start <id>