Как сделать "кластеризацию слов" в R с помощью пакета udpipe?
Я использую udpipe пакет в R, чтобы сделать текстовое майнинг. Я следовал этому руководству: https://cran.r-project.org/web/packages/udpipe/vignettes/udpipe-usecase-postagging-lemmatisation.html, но сейчас я немного застрял.
Действительно, я хотел бы сгруппировать более двух слов, чтобы иметь возможность идентифицировать, например, ключевые выражения типа "от заката до рассвета".
Итак, мне было интересно, возможно ли, основываясь на графике в приведенном выше туто, сделать своего рода алгоритм кластеризации, чтобы "объединить" слова, которые сильно - и часто! - связаны вместе? Если да, то как?
Есть ли другой способ сделать это?
Спасибо
1 ответ
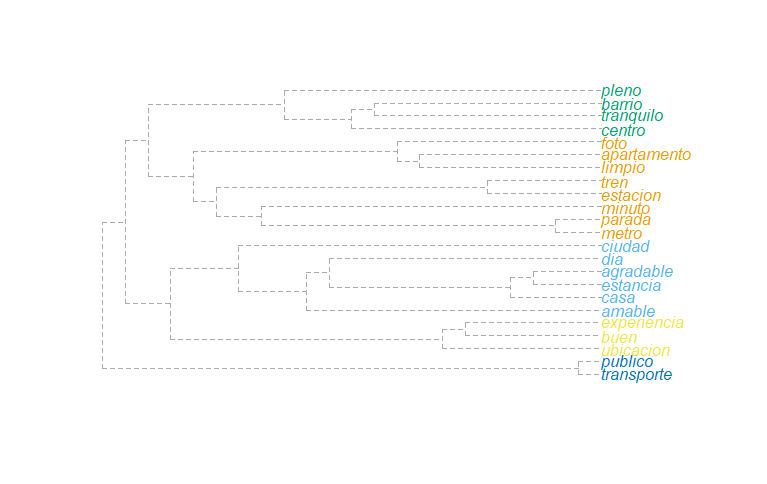
Вот два варианта (с использованием эго-сетей и обнаружения сообщества) на основе предоставленного вами учебника.
library(udpipe)
data(brussels_reviews)
comments <- subset(brussels_reviews, language %in% "es")
ud_model <- udpipe_download_model(language = "spanish")
ud_model <- udpipe_load_model(ud_model$file_model)
x <- udpipe_annotate(ud_model, x = comments$feedback, doc_id = comments$id)
x <- as.data.frame(x)
cooc <- cooccurrence(x = subset(x, upos %in% c("NOUN", "ADJ")),
term = "lemma",
group = c("doc_id", "paragraph_id", "sentence_id"))
head(cooc)
library(igraph)
library(ggraph)
library(ggplot2)
wordnetwork <- head(cooc, 30)
wordnetwork <- graph_from_data_frame(wordnetwork)
ggraph(wordnetwork, layout = "fr") +
geom_edge_link(aes(width = cooc, edge_alpha = cooc), edge_colour = "pink") +
geom_node_text(aes(label = name), col = "darkgreen", size = 4) +
theme_graph(base_family = "Arial Narrow") +
theme(legend.position = "none") +
labs(title = "Cooccurrences within sentence", subtitle = "Nouns & Adjective")
### Option 1: using ego-networks
V(wordnetwork) # the graph has 23 vertices
ego(wordnetwork, order = 2) # 2.0 level ego network for each vertex
ego(wordnetwork, order = 1, nodes = 10) # 1.0 level ego network for the 10th vertex (publico)
### Option 2: using community detection
# Community structure detection based on edge betweenness (http://igraph.org/r/doc/cluster_edge_betweenness.html)
cluster_edge_betweenness(wordnetwork, weights = E(wordnetwork)$cooc)
# Community detection via random walks (http://igraph.org/r/doc/cluster_walktrap.html)
cluster_walktrap(wordnetwork, weights = E(wordnetwork)$cooc, steps = 2)
# Community detection via optimization of modularity score
# This works for undirected graphs only
wordnetwork2 <- as.undirected(wordnetwork) # an undirected graph
cluster_fast_greedy(wordnetwork2, weights = E(wordnetwork2)$cooc)
# Note that you can plot community object
comm <- cluster_fast_greedy(wordnetwork2, weights = E(wordnetwork2)$cooc)
plot_dendrogram(comm)