Как посчитать все строки кода в каталоге рекурсивно?
У нас есть приложение PHP, и мы хотим подсчитать все строки кода в определенном каталоге и его подкаталогах. Нам не нужно игнорировать комментарии, так как мы просто пытаемся получить грубое представление.
wc -l *.php
Эта команда прекрасно работает в данном каталоге, но игнорирует подкаталоги. Я думал, что это может сработать, но возвращается 74, что, безусловно, не так...
find . -name '*.php' | wc -l
Какой правильный синтаксис для подачи во всех файлах?
53 ответа
Пытаться:
find . -name '*.php' | xargs wc -l
Инструмент SLOCCount также может помочь.
Это даст точные исходные строки кода для любой иерархии, на которую вы указываете, а также некоторую дополнительную статистику.
Вы можете использовать cloc Утилита, которая построена именно для этой цели. Он сообщает каждому количество строк на каждом языке, а также количество комментариев и т. Д. CLOC доступен в Linux, Mac и Windows.
Пример использования и вывода:
$ cloc --exclude-lang=DTD,Lua,make,Python .
2570 text files.
2200 unique files.
8654 files ignored.
http://cloc.sourceforge.net v 1.53 T=8.0 s (202.4 files/s, 99198.6 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Javascript 1506 77848 212000 366495
CSS 56 9671 20147 87695
HTML 51 1409 151 7480
XML 6 3088 1383 6222
-------------------------------------------------------------------------------
SUM: 1619 92016 233681 467892
-------------------------------------------------------------------------------
Для другого однострочника:
( find ./ -name '*.php' -print0 | xargs -0 cat ) | wc -l
работает с именами с пробелами, выводит только одно число.
Если вы используете довольно свежую версию Bash (или ZSH), это намного проще:
wc -l **/*.php
В оболочке Bash это требует globstar опция должна быть установлена, в противном случае ** Глоб-оператор не является рекурсивным. Чтобы включить этот параметр, выполните команду
shopt -s globstar
Чтобы сделать это постоянным, добавьте его в один из файлов инициализации (~/.bashrc, ~/.bash_profile так далее.).
В UNIX-подобных системах есть инструмент под названием cloc который предоставляет статистику кода.
Я наткнулся на случайный каталог в нашей кодовой базе:
59 text files.
56 unique files.
5 files ignored.
http://cloc.sourceforge.net v 1.53 T=0.5 s (108.0 files/s, 50180.0 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 36 3060 1431 16359
C/C++ Header 16 689 393 3032
make 1 17 9 54
Teamcenter def 1 10 0 36
-------------------------------------------------------------------------------
SUM: 54 3776 1833 19481
-------------------------------------------------------------------------------
Вы не указали, сколько там файлов или какой желаемый результат. Это то, что вы ищите:
find . -name '*.php' | xargs wc -l
Еще один вариант:)
$ find -name '*.php' | xargs cat | wc -l
Изменить: это даст общую сумму, а не файл за файлом.
Удивительно, но нет ответа, основанного на находке -exec а также awk, Вот так:
find . -type f -exec wc -l {} \; | awk '{ SUM += $0} END { print SUM }'
Этот фрагмент находит для всех файлов (-type f). Чтобы найти по расширению файла, используйте -name:
find . -name *.py -exec wc -l {} \; | awk '{ SUM += $0} END { print SUM }'
Инструмент Tokei отображает статистику кода в каталоге. Tokei покажет количество файлов, общее количество строк в этих файлах и код, комментарии и пробелы, сгруппированные по языку. Tokei также доступен на Mac, Linux и Windows.
Пример вывода Tokei выглядит следующим образом:
$ tokei
-------------------------------------------------------------------------------
Language Files Lines Code Comments Blanks
-------------------------------------------------------------------------------
CSS 2 12 12 0 0
JavaScript 1 435 404 0 31
JSON 3 178 178 0 0
Markdown 1 9 9 0 0
Rust 10 408 259 84 65
TOML 3 69 41 17 11
YAML 1 30 25 0 5
-------------------------------------------------------------------------------
Total 21 1141 928 101 112
-------------------------------------------------------------------------------
Tokei можно установить, следуя инструкциям в файле README в репозитории.
Более распространенный и простой, как для меня, предположим, что вам нужно считать файлы с разными расширениями имен (скажем, также нативные)
wc `find . -name '*.[h|c|cpp|php|cc]'`
POSIX
В отличие от большинства других ответов здесь, они работают в любой системе POSIX, для любого количества файлов и с любыми именами файлов (кроме отмеченных).
Строки в каждом файле:
find . -name '*.php' -type f -exec wc -l {} \;
# faster, but includes total at end if there are multiple files
find . -name '*.php' -type f -exec wc -l {} +
Строки в каждом файле, отсортированные по пути к файлу
find . -name '*.php' -type f | sort | xargs -L1 wc -l
# for files with spaces or newlines, use the non-standard sort -z
find . -name '*.php' -type f -print0 | sort -z | xargs -0 -L1 wc -l
Строки в каждом файле, отсортированные по убыванию
find . -name '*.php' -type f -exec wc -l {} \; | sort -nr
# faster, but includes total at end if there are multiple files
find . -name '*.php' -type f -exec wc -l {} + | sort -nr
Всего строк во всех файлах
find . -name '*.php' -type f -exec cat {} + | wc -l
Есть небольшой инструмент под названием sloccount для подсчета строк кода в каталоге. Следует отметить, что он делает больше, чем вы хотите, так как он игнорирует пустые строки / комментарии, группирует результаты по языкам программирования и вычисляет некоторую статистику.
То, что вы хотите, это просто for цикл:
total_count=0
for file in $(find . -name *.php -print)
do
count=$(wc -l $file)
let total_count+=count
done
echo "$total_count"
Только для источников:
wc `find`
для фильтрации, просто используйте grep
wc `find | grep .php$`
Простой, который будет быстрым, будет использовать всю мощь поиска / фильтрации find, не сбой при слишком большом количестве файлов (переполнение аргументов чисел), отлично работает с файлами с забавными символами в имени, без использования xargs, не будет запускать бесполезно большое количество внешних команд (благодаря + за find"s -exec). Ну вот:
find . -name '*.php' -type f -exec cat -- {} + | wc -l
Полагаю, никто никогда не увидит, что это закопано сзади... И все же ни один из ответов до сих пор не касается проблемы имен файлов с пробелами. Кроме того, все, что используют xargs могут потерпеть неудачу, если общая длина путей в дереве превышает предельный размер среды оболочки (по умолчанию - несколько мегабайт в Linux). Вот тот, который решает эти проблемы довольно прямо. Подоболочка заботится о файлах с пробелами. awk Суммирует поток отдельного файла wc выходы, поэтому никогда не должно выходить из космоса. Это также ограничивает exec только для файлов (пропуская каталоги):
find . -type f -name '*.php' -exec bash -c 'wc -l "$0"' {} \; | awk '{s+=$1} END {print s}'
Я знаю, что вопрос помечен как bash, но кажется, что проблема, которую вы пытаетесь решить, также связана с PHP.
Себастьян Бергманн написал инструмент под названием PHPLOC, который делает то, что вы хотите, и, кроме того, предоставляет вам обзор сложности проекта. Вот пример его отчета:
Size
Lines of Code (LOC) 29047
Comment Lines of Code (CLOC) 14022 (48.27%)
Non-Comment Lines of Code (NCLOC) 15025 (51.73%)
Logical Lines of Code (LLOC) 3484 (11.99%)
Classes 3314 (95.12%)
Average Class Length 29
Average Method Length 4
Functions 153 (4.39%)
Average Function Length 1
Not in classes or functions 17 (0.49%)
Complexity
Cyclomatic Complexity / LLOC 0.51
Cyclomatic Complexity / Number of Methods 3.37
Как видите, предоставленная информация намного полезнее с точки зрения разработчика, поскольку она может примерно сказать вам, насколько сложен проект, прежде чем вы начнете работать с ним.
bashинструменты всегда приятны в использовании, но для этой цели кажется более эффективным просто использовать инструмент, который это делает. Я играл с некоторыми из основных по состоянию на 2022 год, а именно с cloc (perl), gocloc (go), pygount (python).
Получил различные результаты, не слишком их настраивая. Кажется, наиболее точным и невероятно быстрым является .
Пример небольшого проекта laravel с интерфейсом vue:
гоклок
$ ~/go/bin/gocloc /home/jmeyo/project/sequasa
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
JSON 5 0 0 16800
Vue 96 1181 137 8993
JavaScript 37 999 454 7604
PHP 228 1493 2622 7290
CSS 2 157 44 877
Sass 5 72 426 466
XML 11 0 2 362
Markdown 2 45 0 111
YAML 1 0 0 13
Plain Text 1 0 0 2
-------------------------------------------------------------------------------
TOTAL 388 3947 3685 42518
-------------------------------------------------------------------------------
часы
$ cloc /home/jmeyo/project/sequasa
450 text files.
433 unique files.
40 files ignored.
github.com/AlDanial/cloc v 1.90 T=0.24 s (1709.7 files/s, 211837.9 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
JSON 5 0 0 16800
Vuejs Component 95 1181 370 8760
JavaScript 37 999 371 7687
PHP 180 1313 2600 5321
Blade 48 180 187 1804
SVG 27 0 0 1273
CSS 2 157 44 877
XML 12 0 2 522
Sass 5 72 418 474
Markdown 2 45 0 111
YAML 4 11 37 53
-------------------------------------------------------------------------------
SUM: 417 3958 4029 43682
-------------------------------------------------------------------------------
pygcount
$ pygount --format=summary /home/jmeyo/project/sequasa
┏━━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━┳━━━━━━━━━┳━━━━━━┓
┃ Language ┃ Files ┃ % ┃ Code ┃ % ┃ Comment ┃ % ┃
┡━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━╇━━━━━━━━━╇━━━━━━┩
│ JSON │ 5 │ 1.0 │ 12760 │ 76.0 │ 0 │ 0.0 │
│ PHP │ 182 │ 37.1 │ 4052 │ 43.8 │ 1288 │ 13.9 │
│ JavaScript │ 37 │ 7.5 │ 3654 │ 40.4 │ 377 │ 4.2 │
│ XML+PHP │ 43 │ 8.8 │ 1696 │ 89.6 │ 39 │ 2.1 │
│ CSS+Lasso │ 2 │ 0.4 │ 702 │ 65.2 │ 44 │ 4.1 │
│ SCSS │ 5 │ 1.0 │ 368 │ 38.2 │ 419 │ 43.5 │
│ HTML+PHP │ 2 │ 0.4 │ 171 │ 85.5 │ 0 │ 0.0 │
│ Markdown │ 2 │ 0.4 │ 86 │ 55.1 │ 4 │ 2.6 │
│ XML │ 1 │ 0.2 │ 29 │ 93.5 │ 2 │ 6.5 │
│ Text only │ 1 │ 0.2 │ 2 │ 100.0 │ 0 │ 0.0 │
│ __unknown__ │ 132 │ 26.9 │ 0 │ 0.0 │ 0 │ 0.0 │
│ __empty__ │ 6 │ 1.2 │ 0 │ 0.0 │ 0 │ 0.0 │
│ __duplicate__ │ 6 │ 1.2 │ 0 │ 0.0 │ 0 │ 0.0 │
│ __binary__ │ 67 │ 13.6 │ 0 │ 0.0 │ 0 │ 0.0 │
├───────────────┼───────┼───────┼───────┼───────┼─────────┼──────┤
│ Sum │ 491 │ 100.0 │ 23520 │ 59.7 │ 2173 │ 5.5 │
└───────────────┴───────┴───────┴───────┴───────┴─────────┴──────┘
Результаты неоднозначны, наиболее близким к реальности кажетсяgoclocone, а также, безусловно, самый быстрый:
- часы: 0м0.430с
- гоклок: 0м0.059с
- pygcount: 0m39.980s
Если вы хотите, чтобы все было просто, отключите посредника и просто позвоните wc со всеми именами файлов:
wc -l `find . -name "*.php"`
Или в современном синтаксисе:
wc -l $(find . -name "*.php")
Работает, пока нет пробелов ни в одном из имен каталогов или имен файлов. И до тех пор, пока у вас нет десятков тысяч файлов (современные оболочки поддерживают очень длинные командные строки). В вашем проекте 74 файла, поэтому у вас есть много возможностей для роста.
WC -L? лучше использовать GREP -C ^
wc -l? Неправильно! Команда wc считает коды новых строк, а не строк! Если последняя строка в файле не заканчивается кодом новой строки, это не засчитывается!
если вы все еще хотите считать строки, используйте grep -c ^, полный пример:
#this example prints line count for all found files
total=0
find /path -type f -name "*.php" | while read FILE; do
#you see use grep instead wc ! for properly counting
count=$(grep -c ^ < "$FILE")
echo "$FILE has $count lines"
let total=total+count #in bash, you can convert this for another shell
done
echo TOTAL LINES COUNTED: $total
наконец, следите за ловушкой wc -l (число вводов, а не строк!!!)
Для Windows простым и быстрым инструментом является LocMetrics.
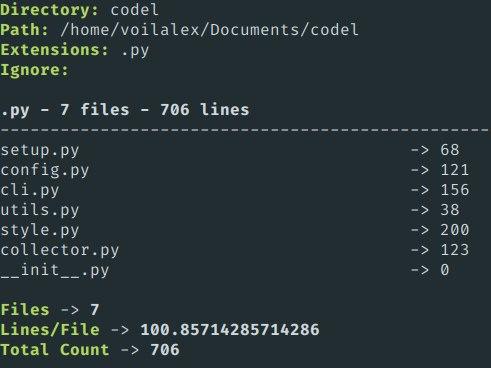
Вы можете использовать утилиту под названием codel(ссылка). Это простой модуль Python для подсчета строк с красочным форматированием.
Установка
pip install codel
Применение
Для подсчета строк файлов C++ (с .cpp а также .h расширения) используйте:
codel count -e .cpp .h
Вы также можете игнорировать некоторые файлы / папки с форматом.gitignore:
codel count -e .py -i tests/**
Он проигнорирует все файлы в tests/ папка.
Результат выглядит так:
Вы также можете сократить вывод с помощью -sфлаг. Он скроет информацию о каждом файле и покажет только информацию о каждом расширении. Пример ниже:
Сначала выдает самые длинные файлы (т. Е. Может быть, эти длинные файлы нуждаются в некотором рефакторинге?), Исключая некоторые каталоги поставщиков:
find . -name '*.php' | xargs wc -l | sort -nr | egrep -v "libs|tmp|tests|vendor" | less
С zsh globs это очень просто:
wc -l ./**/*.php
Если вы используете Bash, вам просто нужно обновить. Нет абсолютно никакой причины использовать bash.
Очень просто
find /path -type f -name "*.php" | while read FILE
do
count=$(wc -l < $FILE)
echo "$FILE has $count lines"
done
Что-то другое:
wc -l `tree -if --noreport | grep -e'\.php$'`
Это хорошо работает, но вам нужно иметь хотя бы один *.php файл в текущей папке или в одной из ее подпапок, либо wc киосков
Если вы хотите, чтобы ваши результаты сортировались по количеству строк, вы можете просто добавить | sort или же | sort -r (-r по убыванию) к первому ответу, вот так:
find . -name '*.php' | xargs wc -l | sort -r
Если файлов слишком много, лучше просто посмотреть общее количество строк.
find . -name '*.php' | xargs wc -l | grep -i ' total' | awk '{print $1}'
В то время как мне нравятся сценарии, я предпочитаю этот, так как он также показывает сводку по каждому файлу, пока общая
wc -l `find . -name "*.php"`