Как мне интерпретировать эти результаты VTune?
Я пытаюсь распараллелить этот код с помощью OpenMP. OpenCV (построенный с использованием IPP для лучшей эффективности) используется в качестве внешней библиотеки.
У меня проблемы с несбалансированным использованием процессора в parallel for с, но кажется, что нет дисбаланса нагрузки. Как вы увидите, это может быть из-за KMP_BLOCKTIME=0, но это может быть необходимо из-за внешних библиотек (IPP, TBB, OpenMP, OpenCV). В остальных вопросах вы найдете более подробную информацию и данные, которые вы можете скачать.
Это ссылки Google Drive на мои результаты VTune:
c755823 basic KMP_BLOCKTIME=0 30 запусков: базовая точка доступа с переменной среды KMP_BLOCKTIME, установленной в 0 при 30 запусках одного и того же входа
c755823 basic 30 запусков: то же, что и выше, но по умолчанию KMP_BLOCKTIME = 200
c755823 расширенный KMP_BLOCKTIME=0 30 запусков: аналогично первому, но расширенная точка доступа
Для тех, кто заинтересован, могу как-то выслать вам оригинальный код.
На моем Intel i7-4700MQ фактическое время настенного приложения в среднем на 10 запусков составляет около 0,73 секунды. Я компилирую код с icpc 2017 обновление 3 со следующими флагами компилятора:
INTEL_OPT=-O3 -ipo -simd -xCORE-AVX2 -parallel -qopenmp -fargument-noalias -ansi-alias -no-prec-div -fp-model fast=2 -fma -align -finline-functions
INTEL_PROFILE=-g -qopt-report=5 -Bdynamic -shared-intel -debug inline-debug-info -qopenmp-link dynamic -parallel-source-info=2 -ldl
Кроме того, я установил KMP_BLOCKTIME=0 потому что значение по умолчанию (200) создавало огромные накладные расходы.
Мы можем разделить код на 3 параллельные области (только в одной #pragma parallel для эффективности) и предыдущий последовательный, который составляет около 25% алгоритма (и его нельзя распараллелить).
Я постараюсь описать их (или вы можете сразу перейти к структуре кода):
- Мы создаем
parallelрегион, чтобы избежать накладных расходов на создание нового параллельного региона. Конечным результатом является заполнение строк объекта матрицы,cv::Mat descriptor, Мы поделились 3std::vectorобъекты: (а)blursкоторая представляет собой цепочку размытий (не распараллеливается) с использованиемGuassianBlurOpenCV (который использует реализацию IPP гуасианских пятен) (б)hessResps(размер известен, скажем, 32) (с)findAffineShapeArgs(неизвестный размер, но в порядке тысяч элементов, скажем, 2.3k) (d)cv::Mat descriptors(неизвестный размер, конечный результат). В серийной части мы заполняем `blurs ', который является вектором только для чтения. - В первой параллельной области
hessRespsзаполняется с помощьюblursбез какого-либо механизма синхронизации. - Во второй параллельной области
findLevelKeypointsзаполняется с помощьюhessRespsтолько для чтения. посколькуfindAffineShapeArgsразмер неизвестен, нам нужен локальный векторlocalfindAffineShapeArgsкоторый будет добавлен кfindAffineShapeArgsна следующем этапе - поскольку
findAffineShapeArgsявляется общим и его размер неизвестен, нам нуженcriticalраздел, где каждыйlocalfindAffineShapeArgsдобавлен к нему. - В третьей параллельной области каждый
findAffineShapeArgsиспользуется для генерации строк финалаcv::Mat descriptor, Опять же, так какdescriptorsподелился, нам нужна локальная версияcv::Mat localDescriptors, - Финал
criticalразделpush_backкаждыйlocalDescriptorsвdescriptors, Обратите внимание, что это очень быстро, так какcv::Matэто своего рода умный указатель, поэтому мыpush_backуказатели.
Это структура кода:
cv::Mat descriptors;
std::vector<Mat> blurs(blursSize);
std::vector<Mat> hessResps(32);
std::vector<FindAffineShapeArgs> findAffineShapeArgs;//we don't know its tsize in advance
#pragma omp parallel
{
//compute all the hessianResponses
#pragma omp for collapse(2) schedule(dynamic)
for(int i=0; i<levels; i++)
for (int j = 1; j <= scaleCycles; j++)
{
hessResps[/**/] = hessianResponse(/*...*/);
}
std::vector<FindAffineShapeArgs> localfindAffineShapeArgs;
#pragma omp for collapse(2) schedule(dynamic) nowait
for(int i=0; i<levels; i++)
for (int j = 2; j < scaleCycles; j++){
findLevelKeypoints(localfindAffineShapeArgs, hessResps[/*...*], /*...*/); //populate localfindAffineShapeArgs with push_back
}
#pragma omp critical{
findAffineShapeArgs.insert(findAffineShapeArgs.end(), localfindAffineShapeArgs.begin(), localfindAffineShapeArgs.end());
}
#pragma omp barrier
#pragma omp for schedule(dynamic) nowait
for(int i=0; i<findAffineShapeArgs.size(); i++){
{
findAffineShape(findAffineShapeArgs[i]);
}
#pragma omp critical{
for(size_t i=0; i<localRes.size(); i++)
descriptors.push_back(localRes[i].descriptor);
}
}
В конце вопроса вы можете найти FindAffineShapeArgs,
Я использую Intel Amplifier, чтобы увидеть горячие точки и оценить свое приложение.
Анализ OpenMP Potential Gain говорит о том, что Paintial Gain при идеальной балансировке нагрузки будет составлять 5,8%, поэтому мы можем сказать, что рабочая нагрузка сбалансирована между разными процессорами.
Это гистограмма использования CPU для региона OpenMP (помните, что это результат 10 последовательных прогонов):
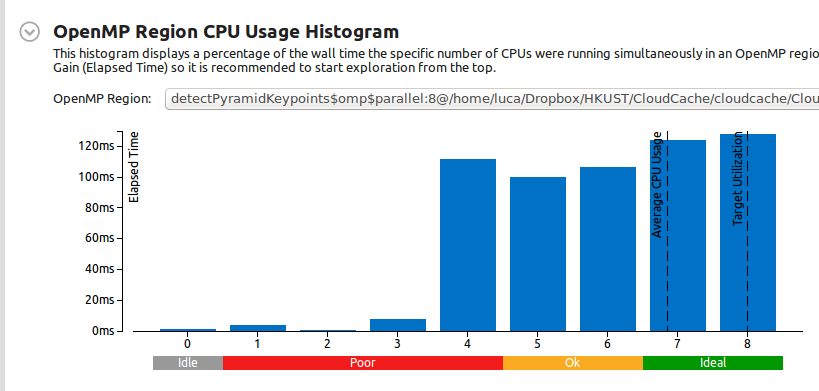
Итак, как вы можете видеть, средняя загрузка процессора составляет 7 ядер, и это хорошо.
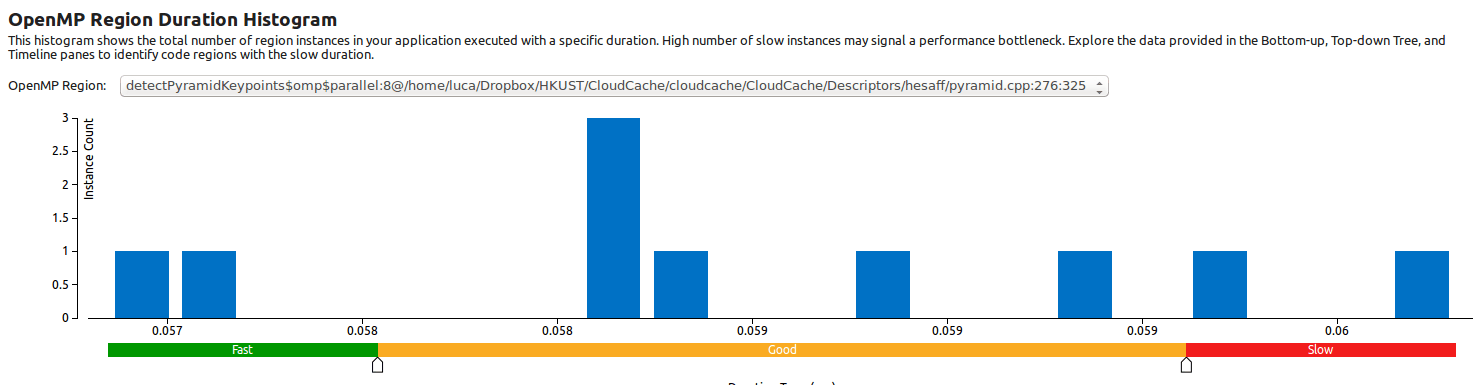
Эта гистограмма продолжительности области OpenMP показывает, что в этих 10 запусках параллельная область выполняется всегда с одинаковым временем (с разбросом около 4 миллисекунд):
Это вкладка Caller/Calee:
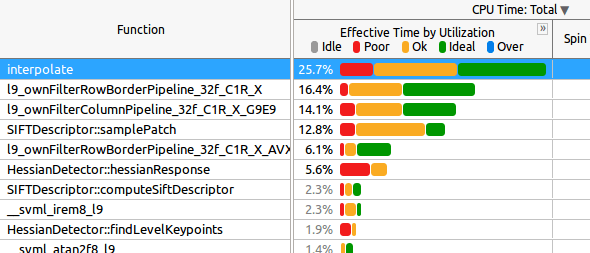
Для вас знание:
interpolateвызывается в последней параллельной областиl9_ownFilter*все функции вызываются в последней параллельной областиsamplePatchвызывается в последней параллельной области.hessianResponseназывается во второй параллельной области
Теперь мой первый вопрос: как мне интерпретировать данные выше? Как вы можете видеть, во многих функциях половину времени "Эффективное время при использовании" - "хорошо", что, вероятно, станет "Плохим" с большим количеством ядер (например, на машине KNL, где я протестирую Приложение рядом).
Наконец, это результат анализа ожидания и блокировки:
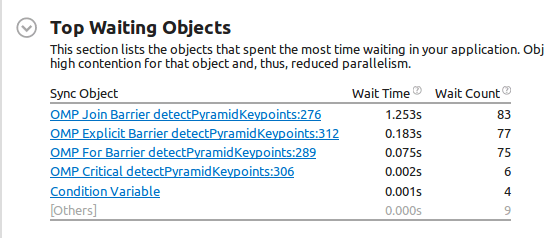
Теперь, это первая странная вещь: линия 276 Join Barrier (который соответствует наиболее дорогому объекту ожидания ) is #pragma omp parallel`, поэтому начало параллельной области. Так что кажется, что кто-то породил темы раньше. Я ошибся? Кроме того, время ожидания больше, чем сама программа (0,827 с против 1,253 с из барьера соединения, о котором я говорю)! Но, возможно, это относится к ожиданию всех потоков (а не времени настенных часов, что явно невозможно, так как это дольше, чем сама программа).
Тогда явный барьер в строке 312 #pragma omp barrier кода выше, и его продолжительность составляет 0,183 с.
Глядя на вкладку Caller/Callee:

Как видите, большая часть времени ожидания невелика, поэтому она относится к одному потоку. Но я уверен, что понимаю это. Мой второй вопрос: можем ли мы интерпретировать это как "все потоки ждут только одного потока, который остается позади?".
FindAffineShapeArgs определение:
struct FindAffineShapeArgs
{
FindAffineShapeArgs(float x, float y, float s, float pixelDistance, float type, float response, const Wrapper &wrapper) :
x(x), y(y), s(s), pixelDistance(pixelDistance), type(type), response(response), wrapper(std::cref(wrapper)) {}
float x, y, s;
float pixelDistance, type, response;
std::reference_wrapper<Wrapper const> wrapper;
};
Топ 5 параллельных регионов по потенциальному приросту в сводном представлении показывает только один регион (единственный)

Посмотрите на группировку "/OpenMP Region/OpenMP Barrier-to-Barrier", это порядок самых дорогих циклов:
3-й цикл:
Прагма омп для графика (динамический) Nowait
для (int i=0; i
это самый дорогой (как я уже знал) и вот скриншот израсходованного просмотра:
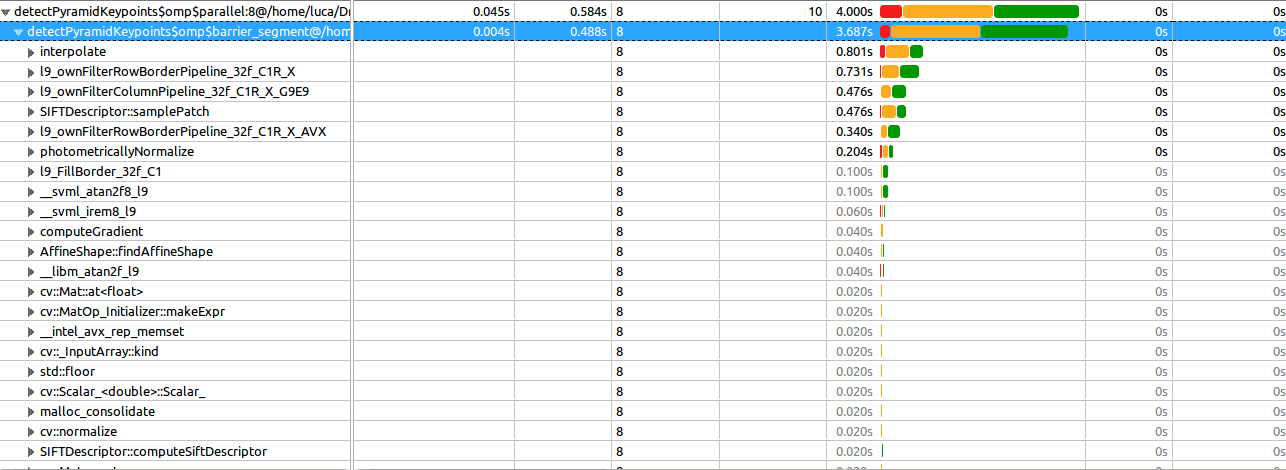
Как видите, многие функции из OpenCV, который использует IPP и уже (должен быть) уже оптимизирован. Расширение двух других функций (interpolate и samplePatch) показывает [Нет информации о стеке вызовов]. То же самое для всех других функций (также и в других регионах).
2-й самый дорогой регион - вторая параллель для:
#pragma omp for collapse(2) schedule(dynamic) nowait
for(int i=0; i<levels; i++)
for (int j = 2; j < scaleCycles; j++){
findLevelKeypoints(localfindAffineShapeArgs, hessResps[/*...*], /*...*/); //populate localfindAffineShapeArgs with push_back
}
Вот расширенный вид:

И, наконец, 3-й самый дорогой это первый цикл:
#pragma omp for collapse(2) schedule(dynamic)
for(int i=0; i<levels; i++)
for (int j = 1; j <= scaleCycles; j++)
{
hessResps[/**/] = hessianResponse(/*...*/);
}
Вот расширенный вид:

Если вы хотите узнать больше, пожалуйста, используйте мои прилагаемые файлы VTune или просто спросите!
1 ответ
Попробуйте прочитать информацию в этой ссылке, особенно часть о "Вложенном OpenMP", поскольку Intel IPP уже использует OpenMP в своей реализации. Из моего опыта работы с Intel IPP и OpenMP, если вы выполняете какой-то другой тип многопоточности и когда каждый из созданных потоков достигает вызовов OpenMP, производительность была действительно плохой. Кроме того, вы можете попробовать использовать #pragma omp параллельный для каждой из параллельных областей вместо #pragma omp для и избавиться от внешней параллели #pragma omp