Как я могу иметь дело с разреженным элементом с высоким измерением в задаче SVR?
У меня есть набор данных в виде твиттера (еще один микроблог) с 1,6 миллионами точек данных, и я пытался предсказать его ретвиты на основе его содержимого. Я извлек его ключевое слово и использую ключевые слова в качестве пакета слов. Тогда я получил 1,2 миллиона единиц измерения. Вектор объектов очень разреженный, обычно только десять измерений в одной точке данных. И я использую SVR, чтобы сделать регресс. Теперь это заняло 2 дня. Я думаю, что время обучения может занять довольно много времени. Я не знаю, если я делаю эту задачу, как это нормально. Есть ли способ или нужно оптимизировать эту проблему?
КСТАТИ. Если в этом случае я не использую какое-либо ядро и машина имеет 32 ГБ ОЗУ и i-7 16 ядер. Как долго время обучения будет в оценке? Я использовал lib pyml.
2 ответа
Вам нужно найти подход уменьшения размерности, который подходит для вашей проблемы.
Я работал над проблемой, аналогичной вашей, и обнаружил, что информационный сбор работает хорошо, но есть и другие.
Я обнаружил, что эта статья (Фабрицио Себастьяни, "Машинное обучение в автоматизированной категоризации текста", ACM Computing Surveys, том 34, № 1, с.1–47, 2002) является хорошей теоретической трактовкой классификации текста, в том числе путем уменьшения функциональности Разнообразие методов от простых (термин частоты) до сложных (информационно-теоретические).
Эти функции пытаются уловить интуицию о том, что наилучшими терминами для ci являются те, которые распределены наиболее по-разному в наборах положительных и отрицательных примеров ci. Однако интерпретации этого принципа различаются в зависимости от функций. Например, в экспериментальных науках χ2 используется для измерения того, как результаты наблюдения отличаются (т.е. не зависят) от результатов, ожидаемых в соответствии с исходной гипотезой (более низкие значения указывают на более низкую зависимость). В DR мы измеряем, насколько независимы tk и ci. Члены tk с наименьшим значением для χ2(tk, ci), таким образом, наиболее независимы от ci; так как нас интересуют термины, которых нет, мы выбираем термины, для которых χ2(tk, ci) является наибольшим.
Эти методы помогают вам выбрать термины, которые наиболее полезны при разделении учебных документов на заданные классы; условия с самой высокой прогностической ценностью для вашей проблемы.
Я успешно использовал Information Gain для сокращения возможностей и нашел этот документ (выбор функций на основе энтропии для категоризации текста Largeron, Christine and Moulin, Christophe and Géry, Mathias - SAC - Pages 924-928 2011) очень хорошим практическим руководством.,
Здесь авторы представляют простую формулировку выбора функции на основе энтропии, которая полезна для реализации в коде:
С учетом термина tj и категории ck ECCD(tj, ck) может быть вычислена из таблицы сопряженности. Пусть A будет количеством документов в категории, содержащей tj; B - количество документов в других категориях, содержащих tj; C, количество документов ck, которые не содержат tj и D, количество документов в других категориях, которые не содержат tj (с N = A + B + C + D):
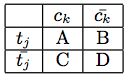
Используя эту таблицу непредвиденных обстоятельств, информационный прирост можно оценить по:
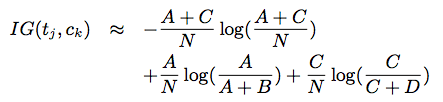
Этот подход прост в реализации и обеспечивает очень хорошее теоретико-информационное сокращение.
Вам также не нужно использовать одну технику; Вы можете объединить их. Ter-Frequency проста, но также может быть эффективной. Я объединил подход информационного усиления с частотой терминов, чтобы успешно выбрать функции. Вы должны поэкспериментировать со своими данными, чтобы увидеть, какая техника или методы работают наиболее эффективно.
Сначала вы можете просто удалить все слова с высокой частотой и все слова с низкой частотой, потому что оба они мало что говорят вам о содержании текста, а затем вы должны сделать поиск по словам.
После этого вы можете попытаться уменьшить размерность своего пространства с помощью хеширования объектов или еще одного расширенного приема уменьшения размерности ( PCA, ICA) или даже того и другого.