Как прочитать CSV-файл объемом 6 ГБ с пандами
Я пытаюсь прочитать большой CSV-файл (около 6 ГБ) в пандах, и я получаю следующую ошибку памяти:
MemoryError Traceback (most recent call last)
<ipython-input-58-67a72687871b> in <module>()
----> 1 data=pd.read_csv('aphro.csv',sep=';')
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in parser_f(filepath_or_buffer, sep, dialect, compression, doublequote, escapechar, quotechar, quoting, skipinitialspace, lineterminator, header, index_col, names, prefix, skiprows, skipfooter, skip_footer, na_values, na_fvalues, true_values, false_values, delimiter, converters, dtype, usecols, engine, delim_whitespace, as_recarray, na_filter, compact_ints, use_unsigned, low_memory, buffer_lines, warn_bad_lines, error_bad_lines, keep_default_na, thousands, comment, decimal, parse_dates, keep_date_col, dayfirst, date_parser, memory_map, nrows, iterator, chunksize, verbose, encoding, squeeze, mangle_dupe_cols, tupleize_cols, infer_datetime_format)
450 infer_datetime_format=infer_datetime_format)
451
--> 452 return _read(filepath_or_buffer, kwds)
453
454 parser_f.__name__ = name
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in _read(filepath_or_buffer, kwds)
242 return parser
243
--> 244 return parser.read()
245
246 _parser_defaults = {
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in read(self, nrows)
693 raise ValueError('skip_footer not supported for iteration')
694
--> 695 ret = self._engine.read(nrows)
696
697 if self.options.get('as_recarray'):
C:\Python27\lib\site-packages\pandas\io\parsers.pyc in read(self, nrows)
1137
1138 try:
-> 1139 data = self._reader.read(nrows)
1140 except StopIteration:
1141 if nrows is None:
C:\Python27\lib\site-packages\pandas\parser.pyd in pandas.parser.TextReader.read (pandas\parser.c:7145)()
C:\Python27\lib\site-packages\pandas\parser.pyd in pandas.parser.TextReader._read_low_memory (pandas\parser.c:7369)()
C:\Python27\lib\site-packages\pandas\parser.pyd in pandas.parser.TextReader._read_rows (pandas\parser.c:8194)()
C:\Python27\lib\site-packages\pandas\parser.pyd in pandas.parser.TextReader._convert_column_data (pandas\parser.c:9402)()
C:\Python27\lib\site-packages\pandas\parser.pyd in pandas.parser.TextReader._convert_tokens (pandas\parser.c:10057)()
C:\Python27\lib\site-packages\pandas\parser.pyd in pandas.parser.TextReader._convert_with_dtype (pandas\parser.c:10361)()
C:\Python27\lib\site-packages\pandas\parser.pyd in pandas.parser._try_int64 (pandas\parser.c:17806)()
MemoryError:
Любая помощь по этому вопросу?
17 ответов
Ошибка показывает, что на машине недостаточно памяти для одновременного считывания всего CSV-файла в DataFrame. Предполагая, что вам не нужен весь набор данных в памяти одновременно, один из способов избежать этой проблемы - обработать CSV порциями (указав chunksize параметр):
chunksize = 10 ** 6
for chunk in pd.read_csv(filename, chunksize=chunksize):
process(chunk)
Чанкинг не всегда должен быть первым портом захода для этой проблемы.
1. Является ли файл большим из-за повторяющихся нечисловых данных или нежелательных столбцов?
Если это так, иногда вы можете увидеть значительную экономию памяти, читая в столбцах категории и выбирая необходимые столбцы с помощью pd.read_csv usecols параметр.
2. Требует ли ваш рабочий процесс нарезки, манипуляции, экспорта?
Если это так, вы можете использовать dask.dataframe для нарезки, выполнения своих вычислений и многократного экспорта. Чанкинг выполняется dask без вывода сообщений, который также поддерживает подмножество API pandas.
3. Если ничего не помогает, читайте построчно через чанки.
Кусок через панд или через библиотеку csv в крайнем случае.
Для больших данных я рекомендую использовать библиотеку "dask"
например:
# Dataframes implement the Pandas API
import dask.dataframe as dd
df = dd.read_csv('s3://.../2018-*-*.csv')
Я поступил так:
chunks=pd.read_table('aphro.csv',chunksize=1000000,sep=';',\
names=['lat','long','rf','date','slno'],index_col='slno',\
header=None,parse_dates=['date'])
df=pd.DataFrame()
%time df=pd.concat(chunk.groupby(['lat','long',chunk['date'].map(lambda x: x.year)])['rf'].agg(['sum']) for chunk in chunks)
Вы можете читать данные как куски и сохранять каждый кусок как рассол.
import pandas as pd
import pickle
in_path = "" #Path where the large file is
out_path = "" #Path to save the pickle files to
chunk_size = 400000 #size of chunks relies on your available memory
separator = "~"
reader = pd.read_csv(in_path,sep=separator,chunksize=chunk_size,
low_memory=False)
i=1
for chunk in reader:
out_file = out_path + "/data_{}.pkl".format(i)
with open(out_file, "wb") as f:
pickle.dump(chunk,f,pickle.HIGHEST_PROTOCOL)
i+=1
На следующем шаге вы читаете в рассолах и добавляете каждый рассол к желаемому фрейму данных.
import glob
pickle_path = "" #Same Path as out_path i.e. where the pickle files are
data_files=[]
for name in glob.glob(pickle_path + "/data_*.pkl"):
data_p_files.append(name)
df = pd.DataFrame([])
for i in range(len(data_p_files)):
df = df.append(pd.read_pickle(data_p_files[i]),ignore_index=True)
Приведенный выше ответ уже удовлетворяет тему. В любом случае, если вам нужны все данные в памяти - взгляните на bcolz. Это сжатие данных в памяти. У меня был действительно хороший опыт с этим. Но его хватает много функций панд
Изменить: Я получил степень сжатия около 1/10 или оригинального размера, я думаю, конечно, в зависимости от типа данных. Важными недостающими чертами были агрегаты.
Я хочу дать более исчерпывающий ответ, основанный на большинстве потенциальных решений, которые уже предоставлены. Я также хочу указать еще на одно возможное вспомогательное средство, которое может помочь процессу чтения.
Вариант 1: типы
"dtypes" - довольно мощный параметр, который можно использовать для уменьшения нагрузки на память readметоды. Смотрите этот и этот ответ. Pandas по умолчанию пытается определить типы данных.
Что касается структур данных, то для каждых сохраненных данных происходит выделение памяти. На базовом уровне см. Значения ниже (в таблице ниже показаны значения для языка программирования C):
The maximum value of UNSIGNED CHAR = 255
The minimum value of SHORT INT = -32768
The maximum value of SHORT INT = 32767
The minimum value of INT = -2147483648
The maximum value of INT = 2147483647
The minimum value of CHAR = -128
The maximum value of CHAR = 127
The minimum value of LONG = -9223372036854775808
The maximum value of LONG = 9223372036854775807
Обратитесь к этой странице, чтобы увидеть соответствие между типами NumPy и C.
Допустим, у вас есть массив целых чисел. Вы можете как теоретически, так и практически присвоить, скажем, массив 16-битного целочисленного типа, но тогда вы выделите больше памяти, чем вам действительно нужно для хранения этого массива. Чтобы предотвратить это, вы можете установитьdtype вариант на read_csv. Вы не хотите хранить элементы массива как длинные целые числа, где на самом деле вы можете разместить их с 8-битным целым числом (np.int8 или np.uint8).
Обратите внимание на следующую карту dtype.
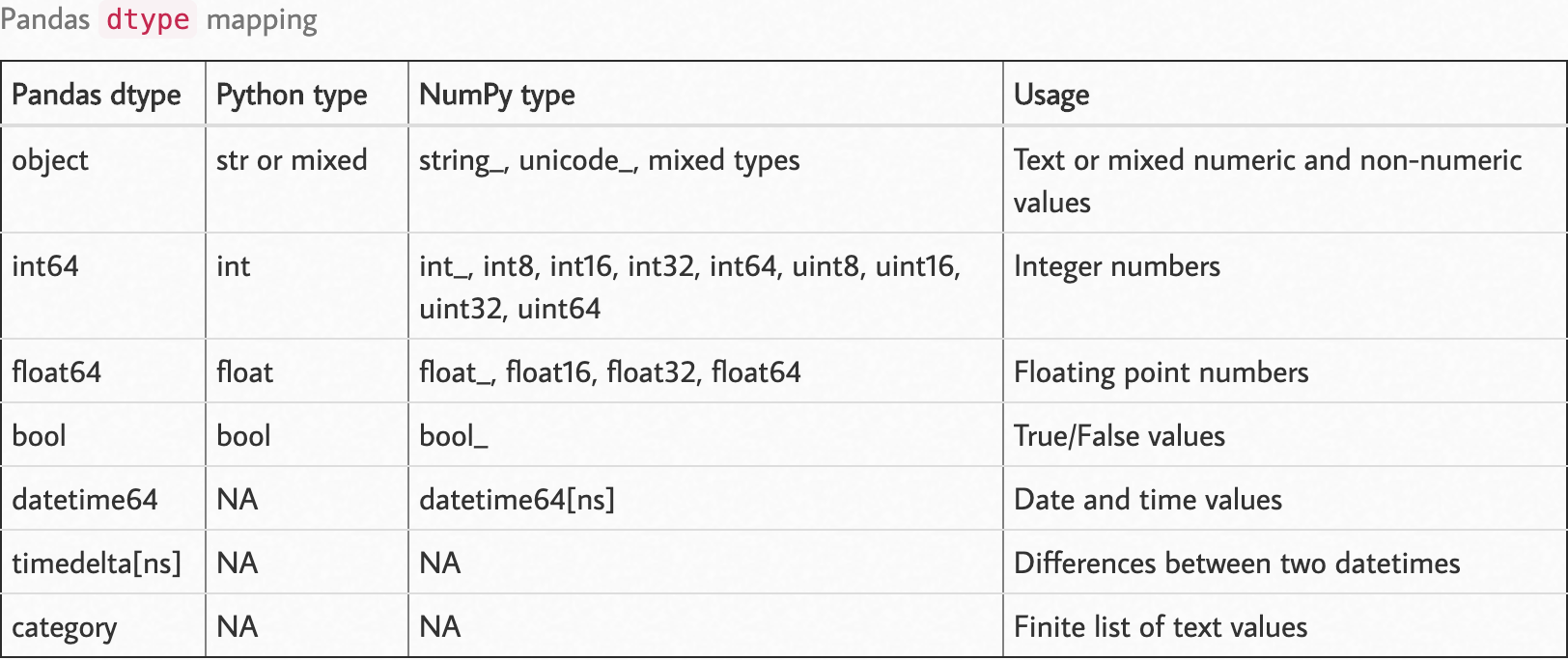 Источник: https://pbpython.com/pandas_dtypes.html
Источник: https://pbpython.com/pandas_dtypes.html
Вы можете пройти dtype параметр как параметр в методах pandas как dict на read как {столбец: тип}.
import numpy as np
import pandas as pd
df_dtype = {
"column_1": int,
"column_2": str,
"column_3": np.int16,
"column_4": np.uint8,
...
"column_n": np.float32
}
df = pd.read_csv('path/to/file', dtype=df_dtype)
Вариант 2: чтение по частям
Чтение данных по частям позволяет вам получить доступ к части данных в памяти, и вы можете применить предварительную обработку к своим данным и сохранить обработанные данные, а не необработанные данные. Было бы намного лучше, если бы вы сочетали этот вариант с первым, dtypes.
Я хочу указать на разделы кулинарной книги pandas для этого процесса, где вы можете найти это здесь. Обратите внимание на эти два раздела;
Вариант 3: Даск
Dask - это фреймворк, который на веб-сайте Dask определяется как:
Dask обеспечивает расширенный параллелизм для аналитики, обеспечивая масштабируемую производительность для ваших любимых инструментов.
Он был рожден для того, чтобы покрывать необходимые части, до которых панды не могут добраться. Dask - это мощный фреймворк, который обеспечивает гораздо больший доступ к данным за счет их распределенной обработки.
Вы можете использовать dask для предварительной обработки ваших данных в целом, Dask позаботится о фрагментации, поэтому, в отличие от pandas, вы можете просто определить шаги обработки и позволить Dask выполнять работу. Dask не применяет вычисления до тех пор, пока они не будут явно отправленыcompute и / или persist(см. ответ здесь, чтобы узнать разницу).
Другие средства (идеи)
- Поток ETL разработан для данных. Сохранение только того, что необходимо из необработанных данных.
- Сначала примените ETL ко всем данным с помощью таких фреймворков, как Dask или PySpark, и экспортируйте обработанные данные.
- Затем посмотрите, могут ли обработанные данные уместиться в памяти в целом.
- Рассмотрите возможность увеличения объема оперативной памяти.
- Рассмотрите возможность работы с этими данными на облачной платформе.
Перед использованием опции chunksize, если вы хотите быть уверенным в функции процесса, которую вы хотите записать внутри цикла for-chunking, как указано в @unutbu, вы можете просто использовать опцию nrows.
small_df = pd.read_csv(filename, nrows=100)
Убедившись, что блок процесса готов, вы можете поместить его в цикл for для всего фрейма данных.
Функции read_csv и read_table практически одинаковы. Но вы должны назначить разделитель ",", когда вы используете функцию read_table в вашей программе.
def get_from_action_data(fname, chunk_size=100000):
reader = pd.read_csv(fname, header=0, iterator=True)
chunks = []
loop = True
while loop:
try:
chunk = reader.get_chunk(chunk_size)[["user_id", "type"]]
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped")
df_ac = pd.concat(chunks, ignore_index=True)
Решение 1:
Использование панд с большими данными
Решение 2:
TextFileReader = pd.read_csv(path, chunksize=1000) # the number of rows per chunk
dfList = []
for df in TextFileReader:
dfList.append(df)
df = pd.concat(dfList,sort=False)
Вот следующий пример:
chunkTemp = []
queryTemp = []
query = pd.DataFrame()
for chunk in pd.read_csv(file, header=0, chunksize=<your_chunksize>, iterator=True, low_memory=False):
#REPLACING BLANK SPACES AT COLUMNS' NAMES FOR SQL OPTIMIZATION
chunk = chunk.rename(columns = {c: c.replace(' ', '') for c in chunk.columns})
#YOU CAN EITHER:
#1)BUFFER THE CHUNKS IN ORDER TO LOAD YOUR WHOLE DATASET
chunkTemp.append(chunk)
#2)DO YOUR PROCESSING OVER A CHUNK AND STORE THE RESULT OF IT
query = chunk[chunk[<column_name>].str.startswith(<some_pattern>)]
#BUFFERING PROCESSED DATA
queryTemp.append(query)
#! NEVER DO pd.concat OR pd.DataFrame() INSIDE A LOOP
print("Database: CONCATENATING CHUNKS INTO A SINGLE DATAFRAME")
chunk = pd.concat(chunkTemp)
print("Database: LOADED")
#CONCATENATING PROCESSED DATA
query = pd.concat(queryTemp)
print(query)
Если вы используете панды для чтения большого файла в чанк, а затем выводите строку за строкой, вот что я сделал
import pandas as pd
def chunck_generator(filename, header=False,chunk_size = 10 ** 5):
for chunk in pd.read_csv(filename,delimiter=',', iterator=True, chunksize=chunk_size, parse_dates=[1] ):
yield (chunk)
def _generator( filename, header=False,chunk_size = 10 ** 5):
chunk = chunck_generator(filename, header=False,chunk_size = 10 ** 5)
for row in chunk:
yield row
if __name__ == "__main__":
filename = r'file.csv'
generator = generator(filename=filename)
while True:
print(next(generator))
Вы можете попробовать sframe, который имеет тот же синтаксис, что и pandas, но позволяет вам манипулировать файлами, которые больше вашей оперативной памяти.
Если у тебя есть
csv файл с
millions ввода данных, и вы хотите загрузить полный набор данных, вы должны использовать
dask_cudf,
import dask_cudf as dc
df = dc.read_csv("large_data.csv")
В случае, если кто-то все еще ищет что-то подобное, я обнаружил, что эта новая библиотека под названием modin может помочь. Он использует распределенные вычисления, которые могут помочь с чтением. Вот хорошая статья, сравнивающая его функциональность с пандами. По сути, он использует те же функции, что и панды.
import modin.pandas as pd
pd.read_csv(CSV_FILE_NAME)
def read_csv_with_progress(file_path, sep):
import pandas as pd
from tqdm import tqdm
chunk_size = 50000 # Number of lines to read in each iteration
# Get the total number of lines in the CSV file
print("Calculating average line length + getting file size")
counter = 0
total_length = 0
num_to_sample = 10
for line in open(file_path, 'r'):
counter += 1
if counter > 1:
total_length += len(line)
if counter == num_to_sample + 1:
break
file_size = os.path.getsize(file_path)
avg_line_length = total_length / num_to_sample
avg_number_of_lines = int(file_size / avg_line_length)
chunks = []
with tqdm(total=avg_number_of_lines, desc='Reading CSV') as pbar:
for chunk in pd.read_csv(file_path, chunksize=chunk_size, low_memory=False, sep=sep):
chunks.append(chunk)
pbar.update(chunk.shape[0])
print("Concating...")
df = pd.concat(chunks, ignore_index=True)
return df
В дополнение к ответам выше, для тех, кто хочет обработать CSV и затем экспортировать в csv, parquet или SQL, d6tstack является еще одним хорошим вариантом. Вы можете загрузить несколько файлов, и это имеет дело с изменениями схемы данных (добавлены / удалены столбцы). Поддержка по частям уже встроена.
def apply(dfg):
# do stuff
return dfg
c = d6tstack.combine_csv.CombinerCSV([bigfile.csv], apply_after_read=apply, sep=',', chunksize=1e6)
# or
c = d6tstack.combine_csv.CombinerCSV(glob.glob('*.csv'), apply_after_read=apply, chunksize=1e6)
# output to various formats, automatically chunked to reduce memory consumption
c.to_csv_combine(filename='out.csv')
c.to_parquet_combine(filename='out.pq')
c.to_psql_combine('postgresql+psycopg2://usr:pwd@localhost/db', 'tablename') # fast for postgres
c.to_mysql_combine('mysql+mysqlconnector://usr:pwd@localhost/db', 'tablename') # fast for mysql
c.to_sql_combine('postgresql+psycopg2://usr:pwd@localhost/db', 'tablename') # slow but flexible