Не жадное (неохотное) сопоставление регулярных выражений в sed?
Я пытаюсь использовать sed, чтобы очистить строки URL-адресов, чтобы извлечь только домен..
Так из:
http://www.suepearson.co.uk/product/174/71/3816/
Я хочу:
(с косой чертой или без нее, это не имеет значения)
Я пытался:
sed 's|\(http:\/\/.*?\/\).*|\1|'
и (избегая не жадного квантификатора)
sed 's|\(http:\/\/.*\?\/\).*|\1|'
но я не могу заставить работать не жадный квантификатор, поэтому он всегда совпадает со всей строкой.
27 ответов
Ни базовое, ни расширенное регулярное выражение Posix/GNU не распознает не жадный квантификатор; вам нужно позднее регулярное выражение К счастью, Perl регулярное выражение для этого контекста довольно легко получить:
perl -pe 's|(http://.*?/).*|\1|'
С помощью sed я обычно реализую поиск без жадности, ища что-либо, кроме разделителя до разделителя:
echo "http://www.suon.co.uk/product/1/7/3/" | sed -n 's;\(http://[^/]*\)/.*;\1;p'
Выход:
http://www.suon.co.uk
это:
- не выводить
-n - поиск, сопоставление шаблона, замена и печать
s/<pattern>/<replace>/p - использование
;разделитель команд поиска вместо/чтобы было легче печатать такs;<pattern>;<replace>;p - запомнить совпадение в скобках
\(...\), позже доступны с\1,\2... - матч
http:// - после чего в скобках
[],[ab/]будет означать либоaили жеbили же/ - первый
^в[]средстваnot, за которым следует все, кроме вещи в[] - так
[^/]означает что-нибудь кроме/персонаж *это повторить предыдущую группу так[^/]*означает символы кроме/,- до сих пор
sed -n 's;\(http://[^/]*\)значит искать и помнитьhttp://с последующими любыми символами, кроме/и запомни, что ты нашел - мы хотим искать до конца домена, поэтому остановимся на следующем
/так что добавь еще/в конце:sed -n 's;\(http://[^/]*\)/'но мы хотим сопоставить остальную часть строки после домена, поэтому добавьте.* - сейчас матч запомнился в группе 1 (
\1) является доменом, поэтому замените совпавшую строку материалом, сохраненным в группе\1и распечатать:sed -n 's;\(http://[^/]*\)/.*;\1;p'
Если вы хотите включить обратную косую черту и после домена, добавьте еще одну обратную косую черту в группу, чтобы запомнить:
echo "http://www.suon.co.uk/product/1/7/3/" | sed -n 's;\(http://[^/]*/\).*;\1;p'
выход:
http://www.suon.co.uk/
Имитация ленивого (не жадного) квантификатора в sed
И все другие регулярные выражения!
Нахождение первого появления выражения:
POSIX ERE (используя
-rопция)Regex:
(EXPRESSION).*|.Sed:
sed -r "s/(EXPRESSION).*|./\1/g" # Global `g` modifier should be onПример (поиск первой последовательности цифр) Демо:
$ sed -r "s/([0-9]+).*|./\1/g" <<< "foo 12 bar 34"12Как это работает?
Это регулярное выражение извлекает выгоду из чередования
|, В каждой позиции двигатель будет искать первую сторону чередования (наша цель) и, если она не совпадает, вторая сторона чередования, которая имеет точку.соответствует следующему непосредственному символу.
Поскольку установлен глобальный флаг, движок пытается продолжить сопоставление символ за символом до конца входной строки или нашей цели. Как только первая и единственная группа захвата левой стороны чередования совпадает
(EXPRESSION)остальная часть линии потребляется сразу же.*, Теперь мы держим нашу ценность в первой группе захвата.POSIX BRE
Regex:
\(\(\(EXPRESSION\).*\)*.\)*Sed:
sed "s/\(\(\(EXPRESSION\).*\)*.\)*/\3/"Пример (поиск первой последовательности цифр):
$ sed "s/\(\(\([0-9]\{1,\}\).*\)*.\)*/\3/" <<< "foo 12 bar 34"12Это похоже на версию ERE, но без чередования. Это все. В каждой позиции двигатель пытается сопоставить цифру.

Если он найден, другие следующие цифры потребляются и захватываются, а остальная часть строки сопоставляется немедленно, иначе
*означаетбольше или ноль пропускает вторую группу захвата\(\([0-9]\{1,\}\).*\)*и достигает точки.соответствовать одному символу, и этот процесс продолжается.
Нахождение первого вхождения выражения с разделителями:
Этот подход будет соответствовать самому первому вхождению строки с разделителями. Мы можем назвать это блоком строк.
sed "s/\(END-DELIMITER-EXPRESSION\).*/\1/; \ s/\(\(START-DELIMITER-EXPRESSION.*\)*.\)*/\1/g"Строка ввода:
foobar start block #1 end barfoo start block #2 end-EDE:
end-SDE:
start$ sed "s/\(end\).*/\1/; s/\(\(start.*\)*.\)*/\1/g"Выход:
start block #1 endПервое регулярное выражение
\(end\).*соответствует и захватывает первый конечный разделительendи подставляет все совпадения с недавно захваченными символами, которые являются конечным разделителем. На данном этапе наш результат:foobar start block #1 end,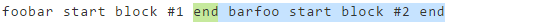
Затем результат передается второму регулярному выражению
\(\(start.*\)*.\)*это то же самое, что версия POSIX BRE выше. Соответствует одному символу, если начальный разделительstartне совпадает, иначе совпадает и захватывает начальный разделитель и соответствует остальным символам.
Непосредственно отвечая на ваш вопрос
Используя подход № 2 (выражение с разделителями), вы должны выбрать два соответствующих выражения:
EDE:
[^:/]\/SDE:
http:
Использование:
$ sed "s/\([^:/]\/\).*/\1/g; s/\(\(http:.*\)*.\)*/\1/" <<< "http://www.suepearson.co.uk/product/174/71/3816/"
Выход:
http://www.suepearson.co.uk/
sed не поддерживает "не жадный" оператор.
Вы должны использовать оператор "[]", чтобы исключить "/" из совпадения.
sed 's,\(http://[^/]*\)/.*,\1,'
PS нет необходимости использовать обратную косую черту "/".
sed - не жадное совпадение от Christoph Sieghart
Уловка, чтобы получить не жадное соответствие в sed, состоит в том, чтобы сопоставить все символы, кроме того, который заканчивает соответствие. Я знаю, нетрудно, но я потратил драгоценные минуты на это, и сценарии оболочки должны быть, в конце концов, быстрыми и легкими. Так что в случае, если это может понадобиться кому-то другому:
Жадный подход
% echo "<b>foo</b>bar" | sed 's/<.*>//g'
bar
Не жадные соответствия
% echo "<b>foo</b>bar" | sed 's/<[^>]*>//g'
foobar
Нежадное решение для более чем одного персонажа
Эта ветка действительно старая, но я предполагаю, что людям она все еще нужна. Допустим, вы хотите убить все до самого первого появления HELLO, Ты не можешь сказать [^HELLO]...
Таким образом, хорошее решение состоит из двух шагов, при условии, что вы можете сэкономить уникальное слово, которое вы не ожидаете во входных данных, скажем, top_sekrit,
В этом случае мы можем:
s/HELLO/top_sekrit/ #will only replace the very first occurrence
s/.*top_sekrit// #kill everything till end of the first HELLO
Конечно, при более простом вводе вы можете использовать меньшее слово или, возможно, даже один символ.
НТН!
Это можно сделать с помощью cut:
echo "http://www.suepearson.co.uk/product/174/71/3816/" | cut -d'/' -f1-3
Другой способ, не используя регулярное выражение, это использовать метод fields/delimiter, например
string="http://www.suepearson.co.uk/product/174/71/3816/"
echo $string | awk -F"/" '{print $1,$2,$3}' OFS="/"
sed конечно есть свое место но это не один из них!
Как указал Ди: просто используйте cut, В этом случае все гораздо проще и безопаснее. Вот пример, где мы извлекаем различные компоненты из URL, используя синтаксис Bash:
url="http://www.suepearson.co.uk/product/174/71/3816/"
protocol=$(echo "$url" | cut -d':' -f1)
host=$(echo "$url" | cut -d'/' -f3)
urlhost=$(echo "$url" | cut -d'/' -f1-3)
urlpath=$(echo "$url" | cut -d'/' -f4-)
дает тебе:
protocol = "http"
host = "www.suepearson.co.uk"
urlhost = "http://www.suepearson.co.uk"
urlpath = "product/174/71/3816/"
Как видите, это гораздо более гибкий подход.
(все заслуги перед Ди)
sed -E интерпретирует регулярные выражения как расширенные (современные) регулярные выражения
Обновление: -E на MacOS X, -r в GNU sed.
Все еще есть надежда решить эту проблему с помощью чистого (GNU) sed. Несмотря на то, что в некоторых случаях это не является общим решением, вы можете использовать "циклы" для удаления всех ненужных частей строки, например:
sed -r -e ":loop" -e 's|(http://.+)/.*|\1|' -e "t loop"
- -r: использовать расширенное регулярное выражение (для + и неэкранированных скобок)
- ": loop": определить новую метку с именем "loop"
- -e: добавить команды в sed
- "t loop": вернуться к метке "loop", если произошла успешная замена
Единственная проблема здесь в том, что он также обрезает последний символ-разделитель ('/'), но если он вам действительно нужен, вы все равно можете просто вернуть его после завершения цикла, просто добавьте эту дополнительную команду в конце предыдущего командная строка:
-e "s,$,/,"
Поскольку вы специально указали, что пытаетесь использовать sed (вместо perl, cut и т. Д.), Попробуйте группировать. Это позволяет обойтись без жадного идентификатора, который может быть не распознан. Первая группа - это протокол (т. Е. "Http: //", "https: //", "tcp: //" и т. Д.). Вторая группа - это домен:
эхо "http://www.suon.co.uk/product/1/7/3/" | sed "s|^\(.*//\)\([^/]*\).*$|\1\2|"
Если вы не знакомы с группировкой, начните здесь.
Я понимаю, что это старая запись, но кто-то может найти ее полезной. Поскольку полное доменное имя не должно превышать общую длину 253 символов, замените.* На.\{1, 255\}
Следующее решение работает для сопоставления/работы с множественными присутствующими (сцепленными, тандемными, составными) HTML или другими тегами. Например, я хотел отредактировать HTML-код, чтобы удалить теги, которые появляются в тандеме.
Выпуск: обычный
sedрегулярные выражения жадно сопоставлялись по всем тегам от первого до последнего.
Решение: нежадное сопоставление с образцом (согласно обсуждениям в этом потоке, например /questions/3025202/ne-zhadnoe-neohotnoe-sopostavlenie-regulyarnyih-vyirazhenij-v-sed/3025213#3025213).
Пример:
echo '<span>Will</span>This <span>remove</span>will <span>this.</span>remain.' | \
sed 's/<span>[^>]*>//g' ; echo
This will remain.
Объяснение:
-
s/<span>: найти<span> -
[^>]: за которым следует все, что не -
*>: пока не найдешь> -
//g: заменить любые такие строки ничем.
Приложение
Я пытался очистить URL-адреса, но столкнулся с трудностями при сопоставлении/исключении слова, используя подход, описанный выше. Я кратко рассмотрел отрицательные обходы ( регулярное выражение для сопоставления строки, не содержащей слова ), но этот подход показался мне слишком сложным и не дал удовлетворительного решения.
Я решил заменить на (обратная галочка), выполнить замену регулярных выражений, а затем заменить на .
Пример (отформатировано здесь для удобочитаемости):
printf '\n
<a aaa h href="apple">apple</a>
<a bbb "c=ccc" href="banana">banana</a>
<a class="gtm-content-click"
data-vars-link-text="nope"
data-vars-click-url="https://blablabla"
data-vars-event-category="story"
data-vars-sub-category="story"
data-vars-item="in_content_link"
data-vars-link-text
href="https:example.com">Example.com</a>\n\n' |
sed 's/href/`/g ;
s/<a[^`]*`/\n<a href/g'
<a href="apple">apple</a>
<a href="banana">banana</a>
<a href="https:example.com">Example.com</a>
Объяснение: в основном, как указано выше. Здесь,
-
s/href/`: заменятьhrefс (обратная галочка) -
s/<a: найти начало URL -
[^`]: за которым следует все, что не является (обратная кавычка) -
*`: пока не найдете` -
/<a href/g: заменить каждый из найденных на<a href
Еще не видел этот ответ, так вот как вы можете сделать это с vi или же vim:
vi -c '%s/\(http:\/\/.\{-}\/\).*/\1/ge | wq' file &>/dev/null
Это запускает vi:%s глобальное замещение (конечный g), воздерживается от выдачи ошибки, если шаблон не найден (e), затем сохраняет полученные изменения на диск и завершает работу. &>/dev/null предотвращает кратковременное мигание графического интерфейса на экране, что может раздражать.
Мне нравится использовать vi иногда для очень сложных регулярных выражений, потому что (1) perl умирает, (2) vim имеет очень продвинутый движок регулярных выражений, и (3) я уже близко знаком с vi регулярные выражения в моих ежедневных документах редактирования использования.
Поскольку PCRE также помечен здесь, мы могли бы использовать GNU, используя неленивое сопоставление в регулярном выражении, которое будет соответствовать первому ближайшему совпадению, противоположному
.*(что действительно жадно и продолжается до последнего совпадения).
grep -oP '^http[s]?:\/\/.*?/' Input_file
Объяснение: использование
oPварианты здесь, где
-Pотвечает за включение регулярного выражения PCRE здесь. В основной программе
grepупоминание регулярного выражения, которое соответствует запуску http/https, за которым следует
://до следующего появления, так как мы использовали
.*?он будет искать в первую очередь
/после (http/https://). Он будет печатать совпадающую часть только в строке.
Это - то, как надежно сделать не жадное сопоставление многосимвольных строк, используя sed. Допустим, вы хотите изменить каждый foo...bar в <foo...bar> так, например, этот вход:
$ cat file
ABC foo DEF bar GHI foo KLM bar NOP foo QRS bar TUV
должен стать этот вывод:
ABC <foo DEF bar> GHI <foo KLM bar> NOP <foo QRS bar> TUV
Для этого вы конвертируете foo и bar в отдельные символы, а затем используете отрицание этих символов между ними:
$ sed 's/@/@A/g; s/{/@B/g; s/}/@C/g; s/foo/{/g; s/bar/}/g; s/{[^{}]*}/<&>/g; s/}/bar/g; s/{/foo/g; s/@C/}/g; s/@B/{/g; s/@A/@/g' file
ABC <foo DEF bar> GHI <foo KLM bar> NOP <foo QRS bar> TUV
В приведенном выше:
s/@/@A/g; s/{/@B/g; s/}/@C/gконвертирует{а также}для строк-заполнителей, которые не могут существовать во входных данных, так что эти символы затем доступны для преобразованияfooа такжеbarк.s/foo/{/g; s/bar/}/gконвертируетfooа такжеbarв{а также}соответственноs/{[^{}]*}/<&>/gвыполняет операцию, которую мы хотим - преобразованиеfoo...barв<foo...bar>s/}/bar/g; s/{/foo/gконвертирует{а также}вернуться кfooа такжеbar,s/@C/}/g; s/@B/{/g; s/@A/@/gпреобразует строки заполнителя обратно в их оригинальные символы.
Обратите внимание, что вышеприведенное не зависит от какой-либо конкретной строки, отсутствующей во входных данных, поскольку она производит такие строки на первом шаге, и не заботится о том, какое вхождение какого-либо конкретного регулярного выражения вы хотите сопоставить, так как вы можете использовать {[^{}]*} столько раз, сколько необходимо в выражении, чтобы выделить фактическое совпадение, которое вы хотите, и / или с помощью оператора числового совпадения seds, например, чтобы заменить только второе вхождение:
$ sed 's/@/@A/g; s/{/@B/g; s/}/@C/g; s/foo/{/g; s/bar/}/g; s/{[^{}]*}/<&>/2; s/}/bar/g; s/{/foo/g; s/@C/}/g; s/@B/{/g; s/@A/@/g' file
ABC foo DEF bar GHI <foo KLM bar> NOP foo QRS bar TUV
Еще одна версия sed:
sed 's|/[:alphanum:].*||' file.txt
Это соответствует / сопровождаемый буквенно-цифровым символом (таким образом, не другой слеш), а также остальными символами до конца строки. После этого он заменяет его ничем (т.е. удаляет его).
@Daniel H (относительно вашего комментария к ответу andcoz, хотя и давно): удаление конечных нулей работает с
s,([[:digit:]]\.[[:digit:]]*[1-9])[0]*$,\1,gречь идет о четком определении условий соответствия...
Вот что вы можете сделать с помощью двухэтапного подхода и awk:
A=http://www.suepearson.co.uk/product/174/71/3816/
echo $A|awk '
{
var=gensub(///,"||",3,$0) ;
sub(/\|\|.*/,"",var);
print var
}'
Выход: http://www.suepearson.co.uk/
Надеюсь, это поможет!
echo "/home/one/two/three/myfile.txt" | sed 's|\(.*\)/.*|\1|'
не беспокойтесь, я получил это на другом форуме:)
Вы также должны подумать о случае, когда нет совпадающих разделителей. Вы хотите вывести строку или нет. Мои примеры здесь ничего не выводят, если совпадений нет.
Вам нужен префикс до 3-го /, поэтому выберите дважды строку любой длины, не содержащую / и следующую за /, а затем строку любой длины, не содержащую /, а затем сопоставьте / после любой строки, а затем распечатайте выделение. Эта идея работает с любыми отдельными символами-ограничителями.
echo http://www.suepearson.co.uk/product/174/71/3816/ | \
sed -nr 's,(([^/]*/){2}[^/]*)/.*,\1,p'
Используя команды sed, вы можете быстро удалить префикс или выбрать разделитель, например:
echo 'aaa @cee: { "foo":" @cee: " }' | \
sed -r 't x;s/ @cee: /\n/;D;:x'
Это намного быстрее, чем есть уголь за раз.
Перейти к метке, если предыдущее совпадение было успешным. Добавьте \n в / перед 1-м разделителем. Удалить до первого \n. Если был добавлен \n, перейдите в конец и напечатайте.
Если есть начальные и конечные разделители, просто удалить конечные разделители, пока вы не дойдете до нужного элемента nth-2, а затем выполните трюк с D, удалите после конечного разделителя, перейдите, чтобы удалить, если нет совпадения, удалите до начала разделителя и и Распечатать. Это работает, только если начальные / конечные разделители встречаются парами.
echo 'foobar start block #1 end barfoo start block #2 end bazfoo start block #3 end goo start block #4 end faa' | \
sed -r 't x;s/end//;s/end/\n/;D;:x;s/(end).*/\1/;T y;s/.*(start)/\1/;p;:y;d'
Если у вас есть доступ к gnu grep, вы можете использовать регулярное выражение perl:
grep -Po '^https?://([^/]+)(?=)' <<< 'http://www.suepearson.co.uk/product/174/71/3816/'
http://www.suepearson.co.uk
В качестве альтернативы, чтобы получить все после использования домена
grep -Po '^https?://([^/]+)\K.*' <<< 'http://www.suepearson.co.uk/product/174/71/3816/'
/product/174/71/3816/
К сожалению, как уже упоминалось, это не поддерживается в sed. Чтобы преодолеть это, я предлагаю использовать следующую лучшую вещь (на самом деле даже лучше), чтобы использовать возможности, подобные vim sed.
определить в
.bash-profile
vimdo() { vim $2 --not-a-term -c "$1" -es +"w >> /dev/stdout" -cq! ; }
Это создаст безголовый vim для выполнения команды.
Теперь вы можете сделать, например:
echo $PATH | vimdo "%s_\c:[a-zA-Z0-9\\/]\{-}python[a-zA-Z0-9\\/]\{-}:__g" -
чтобы отфильтровать python в
$PATH.
Использовать
-иметь ввод из трубы в vimdo.
Хотя большая часть синтаксиса одинакова. Vim имеет более продвинутые функции, и использование
\{-}является стандартным для нежадного соответствия. видеть
help regexp.