Что на самом деле означает Кластерный и Некластерный индекс?
Я имею ограниченную подверженность БД и использую только БД в качестве прикладного программиста. Я хочу знать о Clustered а также Non clustered indexes, Я погуглил и нашел:
Кластерный индекс - это особый тип индекса, который изменяет порядок физического хранения записей в таблице. Поэтому таблица может иметь только один кластерный индекс. Конечные узлы кластерного индекса содержат страницы данных. Некластеризованный индекс - это особый тип индекса, в котором логический порядок индекса не соответствует физическому сохраненному порядку строк на диске. Конечный узел некластеризованного индекса не состоит из страниц данных. Вместо этого конечные узлы содержат строки индекса.
В SO я обнаружил, что есть различия между кластеризованным и некластеризованным индексом?,
Может кто-нибудь объяснить это на простом английском языке?
13 ответов
С кластеризованным индексом строки физически хранятся на диске в том же порядке, что и индекс. Следовательно, может быть только один кластерный индекс.
С некластеризованным индексом есть второй список, который имеет указатели на физические строки. У вас может быть много некластеризованных индексов, хотя каждый новый индекс будет увеличивать время, необходимое для записи новых записей.
Как правило, быстрее читать из кластеризованного индекса, если вы хотите вернуть все столбцы. Вам не нужно идти сначала к индексу, а затем к таблице.
Запись в таблицу с кластеризованным индексом может быть медленнее, если есть необходимость перегруппировать данные.
Кластерный индекс означает, что вы говорите базе данных хранить близкие значения, фактически близкие друг к другу на диске. Это дает преимущество быстрого сканирования / извлечения записей, попадающих в некоторый диапазон значений кластеризованного индекса.
Например, у вас есть две таблицы, Клиент и Заказ:
Customer
----------
ID
Name
Address
Order
----------
ID
CustomerID
Price
Если вы хотите быстро получить все заказы одного конкретного клиента, вы можете создать кластеризованный индекс в столбце "CustomerID" таблицы "Заказы". Таким образом, записи с одним и тем же CustomerID будут физически храниться близко друг к другу на диске (кластеризованно), что ускоряет их поиск.
PS Индекс CustomerID, очевидно, будет не уникальным, поэтому вам нужно либо добавить второе поле для "унификации" индекса, либо позволить базе данных обработать это для вас, но это уже другая история.
Относительно нескольких индексов. Вы можете иметь только один кластеризованный индекс на таблицу, потому что это определяет, как физически организованы данные. Если вы хотите провести аналогию, представьте себе большую комнату со множеством столов. Вы можете либо поместить эти таблицы в несколько строк, либо собрать их все вместе, чтобы сформировать большой конференц-стол, но не в обоих направлениях одновременно. Таблица может иметь другие индексы, которые затем будут указывать на записи в кластерном индексе, которые, в свою очередь, в конечном итоге скажут, где найти фактические данные.
В хранилище, ориентированном на строки в SQL Server, как кластерные, так и некластеризованные индексы организованы в виде B-деревьев.
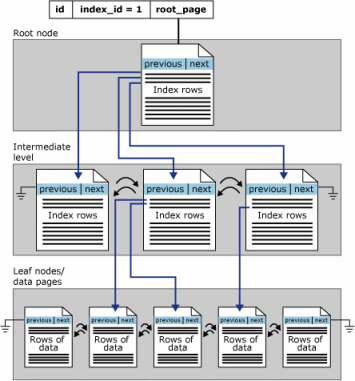
Основное различие между кластеризованными индексами и некластеризованными индексами заключается в том, что конечным уровнем кластеризованного индекса является таблица. Это имеет два значения.
- Строки на листовых страницах кластеризованного индекса всегда содержат что-то для каждого (не разреженного) столбца таблицы (либо значение, либо указатель на фактическое значение).
- Кластерный индекс является основной копией таблицы.
Некластеризованные индексы также могут сделать точку 1, используя INCLUDE Предложение (начиная с SQL Server 2005) явно включать все неключевые столбцы, но они являются вторичными представлениями, и всегда есть другая копия данных (сама таблица).
CREATE TABLE T
(
A INT,
B INT,
C INT,
D INT
)
CREATE UNIQUE CLUSTERED INDEX ci ON T(A,B)
CREATE UNIQUE NONCLUSTERED INDEX nci ON T(A,B) INCLUDE (C,D)
Два индекса выше будут почти идентичны. С индексными страницами верхнего уровня, содержащими значения для ключевых столбцов A,B и страницы уровня листа, содержащие A,B,C,D
В таблице может быть только один кластеризованный индекс, поскольку сами строки данных могут быть отсортированы только в одном порядке.
Приведенная выше цитата из книг по SQL Server в Интернете вызывает много путаницы
На мой взгляд, это было бы гораздо лучше сформулировать как.
В таблице может быть только один кластеризованный индекс, потому что строки уровня листьев кластеризованного индекса являются строками таблицы.
Онлайновая цитата из книг не является неправильной, но вы должны понимать, что "сортировка" как некластеризованных, так и кластеризованных индексов является логической, а не физической. Если вы читаете страницы на уровне листа, следуя связанному списку, и читаете строки на странице в порядке расположения слотов, то вы будете читать строки индекса в отсортированном порядке, но физически страницы могут быть не отсортированы. Обычно считается, что при кластеризованном индексе строки всегда физически хранятся на диске в том же порядке, что и ключ индекса, неверно.
Это было бы абсурдной реализацией. Например, если строка вставлена в середину таблицы 4 ГБ, SQL Server не нужно копировать 2 ГБ данных в файл, чтобы освободить место для вновь вставленной строки.
Вместо этого происходит разделение страницы. Каждая страница на уровне листьев как кластеризованных, так и некластеризованных индексов имеет адрес (File:Page) следующей и предыдущей страницы в порядке логического ключа. Эти страницы не обязательно должны быть смежными или в ключевом порядке.
например, связанная цепочка страниц может быть 1:2000 <-> 1:157 <-> 1:7053
Когда происходит разделение страницы, новая страница выделяется из любой точки файловой группы (из смешанного экстента, для небольших таблиц, или из непустого единообразного экстента, принадлежащего этому объекту, или из вновь выделенного единообразного экстента). Это может даже не быть в том же файле, если файловая группа содержит больше чем один.
Степень, в которой логический порядок и смежность отличаются от идеализированной физической версии, является степенью логической фрагментации.
Во вновь созданной базе данных с одним файлом я запустил следующее.
CREATE TABLE T
(
X TINYINT NOT NULL,
Y CHAR(3000) NULL
);
CREATE CLUSTERED INDEX ix
ON T(X);
GO
--Insert 100 rows with values 1 - 100 in random order
DECLARE @C1 AS CURSOR,
@X AS INT
SET @C1 = CURSOR FAST_FORWARD
FOR SELECT number
FROM master..spt_values
WHERE type = 'P'
AND number BETWEEN 1 AND 100
ORDER BY CRYPT_GEN_RANDOM(4)
OPEN @C1;
FETCH NEXT FROM @C1 INTO @X;
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO T (X)
VALUES (@X);
FETCH NEXT FROM @C1 INTO @X;
END
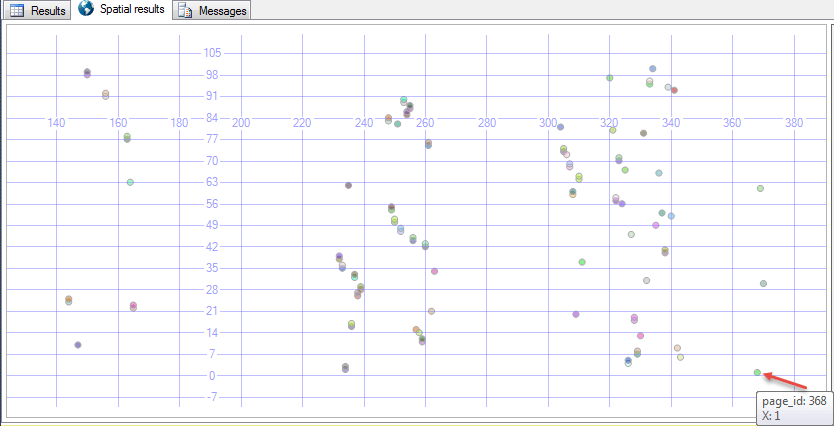
Затем проверил макет страницы с помощью
SELECT page_id,
X,
geometry::Point(page_id, X, 0).STBuffer(1)
FROM T
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
ORDER BY page_id
Результаты были повсюду. Первая строка в ключевом порядке (со значением 1 - выделено стрелкой ниже) была почти на последней физической странице.
Фрагментация может быть уменьшена или удалена путем перестройки или реорганизации индекса для увеличения корреляции между логическим порядком и физическим порядком.
После запуска
ALTER INDEX ix ON T REBUILD;
Я получил следующее
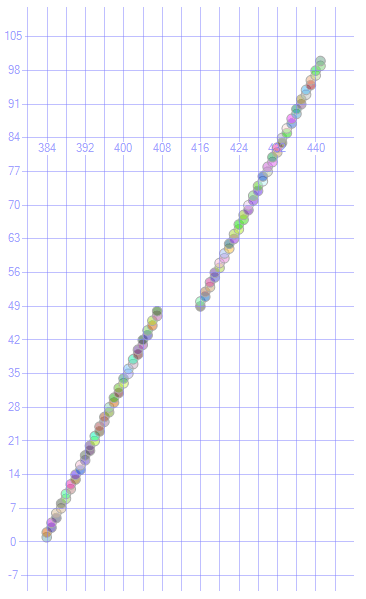
Если таблица не имеет кластеризованного индекса, она называется кучей.
Некластеризованные индексы могут быть построены либо на куче, либо на кластерном индексе. Они всегда содержат локатор строк обратно к базовой таблице. В случае кучи это физический идентификатор строки (rid) и состоит из трех компонентов (File:Page:Slot). В случае кластеризованного индекса указатель строки является логическим (ключ кластеризованного индекса).
В последнем случае, если некластеризованный индекс уже естественным образом включает столбцы ключа CI либо как ключевые столбцы NCI, либо INCLUDE -d столбцы, то ничего не добавляется. В противном случае отсутствующие ключевые столбцы CI автоматически добавляются в NCI.
SQL Server всегда гарантирует, что ключевые столбцы уникальны для обоих типов индекса. Механизм, в котором это применяется для индексов, не объявленных как уникальные, отличается между двумя типами индексов.
Кластерные индексы получают uniquifier добавлено для любых строк со значениями ключа, которые дублируют существующую строку. Это просто восходящее целое число.
Для некластеризованных индексов, не объявленных как уникальные, SQL Server автоматически добавляет локатор строк в ключ некластеризованного индекса. Это относится ко всем строкам, а не только к тем, которые на самом деле являются дубликатами.
Кластеризованная и некластерная номенклатура также используется для индексов хранилища столбцов. Усовершенствования бумажных хранилищ столбцов SQL Server
Хотя данные хранилища столбцов на самом деле не "кластеризованы" ни по одному ключу, мы решили сохранить традиционное соглашение SQL Server, согласно которому первичный индекс следует называть кластеризованным индексом.
Я понимаю, что это очень старый вопрос, но я решил предложить аналогию, чтобы проиллюстрировать прекрасные ответы выше.
КЛАСТЕРНЫЙ ИНДЕКС
Если вы войдете в публичную библиотеку, вы обнаружите, что все книги расположены в определенном порядке (скорее всего, десятичная система Дьюи, или DDS). Это соответствует "кластерному указателю" книг. Если DDS# для книги, которую вы хотите, был 005.7565 F736s, вы бы начать с поиска ряда книжных полок, который помечен 001-099 или что-то типа того. (Этот знак конца колпачка в конце стека соответствует "промежуточному узлу" в индексе.) В конце концов, вам нужно перейти к определенной полке с меткой 005.7450 - 005.7600, затем вы будете сканировать, пока не найдете книгу с указанным DDS#, и в этот момент вы найдете свою книгу.
НЕКЛАСТЕРНЫЙ ИНДЕКС
Но если вы не пришли в библиотеку с запоминанием DDS# вашей книги, то вам понадобится второй индекс, чтобы помочь вам. В старину перед библиотекой находилось замечательное бюро ящиков, известное как "Каталог карт". В ней были тысячи карточек 3х5 - по одной на каждую книгу, отсортированные в алфавитном порядке (возможно, по названию). Это соответствует "некластеризованному индексу". Эти каталоги карт были организованы в иерархическую структуру, так что каждый ящик был помечен диапазоном карт, которые он содержал (Ka - Kl, например; т. е. "промежуточный узел"). Еще раз, вы будете углубляться до тех пор, пока не найдете свою книгу, но в этом случае, как только вы ее найдете (т. Е. "Листовой узел"), у вас будет не сама книга, а только карточка с индексным номером. (DDS#), с помощью которого вы можете найти фактическую книгу в кластерном индексе.
Конечно, ничто не помешает библиотекарю фотокопировать все карточки и сортировать их в другом порядке в отдельном каталоге карточек. (Обычно таких каталогов было как минимум два: один отсортирован по имени автора, а другой по названию.) В принципе, вы можете иметь столько "некластеризованных" индексов, сколько захотите.
Ниже приведены некоторые характеристики кластерных и некластеризованных индексов:
Кластерные индексы
- Кластерные индексы - это индексы, которые однозначно идентифицируют строки в таблице SQL.
- Каждая таблица может иметь ровно один кластерный индекс.
- Вы можете создать кластерный индекс, который охватывает более одного столбца. Например:
create Index index_name(col1, col2, col.....), - По умолчанию столбец с первичным ключом уже имеет кластерный индекс.
Некластеризованные индексы
- Некластеризованные индексы похожи на простые индексы. Они просто используются для быстрого поиска данных. Не обязательно иметь уникальные данные.
Кластерный индекс
Кластерный индекс определяет физический порядок данных в таблице. По этой причине таблица имеет только 1 кластерный индекс.
как "словарь" Нет необходимости в любом другом индексе, его уже индекс по словам
Некластерный индекс
Некластеризованный индекс аналогичен индексу в Книге. Данные хранятся в одном месте. Индекс хранится в другом месте, и у индекса есть указатели на место хранения данных. По этой причине таблица имеет более 1 некластеризованного индекса.
как и в "Книге химии" при взгляде, есть отдельный указатель для указания местоположения главы, а в "КОНЕЦ" есть еще один указатель, указывающий общее местоположение СЛОВ
Очень простое нетехническое практическое правило заключается в том, что кластерные индексы обычно используются для вашего первичного ключа (или, по крайней мере, уникального столбца), а некластеризованные используются для других ситуаций (возможно, внешнего ключа)., Действительно, SQL Server по умолчанию создаст кластерный индекс для столбцов первичного ключа. Как вы узнали, кластеризованный индекс относится к способу физической сортировки данных на диске, что означает, что это хороший универсальный выбор для большинства ситуаций.
Кластерный индекс
Кластерный индекс - это, по сути, таблица с древовидной структурой. Вместо хранения записей в несортированном табличном пространстве Heap, кластеризованный индекс на самом деле представляет собой индекс B+Tree, в котором конечные узлы хранят фактические записи таблицы, как показано на следующей диаграмме.
Кластерный индекс - это структура таблицы по умолчанию в SQL Server и MySQL. В то время как MySQL добавляет индекс скрытых кластеров, даже если таблица не имеет первичного ключа, SQL Server всегда строит кластерный индекс, если таблица имеет столбец первичного ключа. В противном случае SQL Server сохраняется как таблица кучи.
Кластерный индекс может ускорить запросы, которые фильтруют записи по ключу кластеризованного индекса, как обычные операторы CRUD. Поскольку записи расположены в конечных узлах, нет никакого дополнительного поиска дополнительных значений столбцов при поиске записей по их значениям первичного ключа.
Например, при выполнении следующего SQL-запроса на SQL Server:
SELECT PostId, Title
FROM Post
WHERE PostId = ?
Вы можете видеть, что план выполнения использует операцию поиска кластерного индекса для поиска конечного узла, содержащего запись, и для сканирования узлов кластерного индекса требуется только два логических чтения:
|StmtText |
|-------------------------------------------------------------------------------------|
|SELECT PostId, Title FROM Post WHERE PostId = @P0 |
| |--Clustered Index Seek(OBJECT:([high_performance_sql].[dbo].[Post].[PK_Post_Id]), |
| SEEK:([high_performance_sql].[dbo].[Post].[PostID]=[@P0]) ORDERED FORWARD) |
Table 'Post'. Scan count 0, logical reads 2, physical reads 0
Некластерный индекс
Поскольку кластерный индекс обычно строится с использованием значений столбца первичного ключа, если вы хотите ускорить запросы, использующие какой-либо другой столбец, вам придется добавить вторичный некластеризованный индекс.
Вторичный индекс будет хранить значение первичного ключа в своих конечных узлах, как показано на следующей диаграмме:

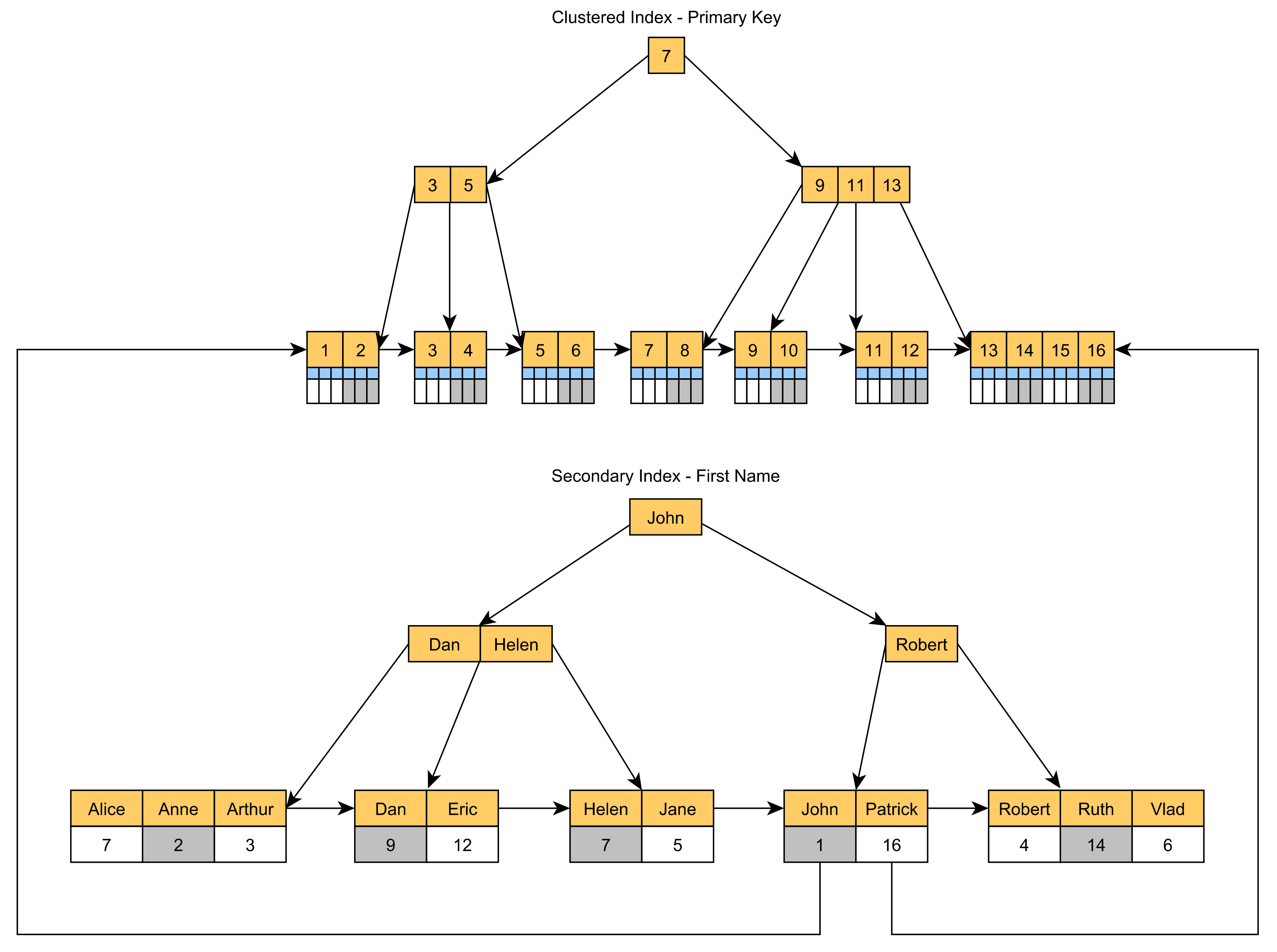
Итак, если мы создадим вторичный индекс на
Title столбец таблицы:
CREATE INDEX IDX_Post_Title on Post (Title)
И выполняем следующий SQL-запрос:
SELECT PostId, Title
FROM Post
WHERE Title = ?
Мы видим, что операция поиска индекса используется для поиска конечного узла в индексе, который может предоставить интересующую нас проекцию SQL-запроса:
|StmtText |
|------------------------------------------------------------------------------|
|SELECT PostId, Title FROM Post WHERE Title = @P0 |
| |--Index Seek(OBJECT:([high_performance_sql].[dbo].[Post].[IDX_Post_Title]),|
| SEEK:([high_performance_sql].[dbo].[Post].[Title]=[@P0]) ORDERED FORWARD)|
Table 'Post'. Scan count 1, logical reads 2, physical reads 0
Поскольку связанный
PostId Значение столбца первичного ключа хранится в
IDX_Post_Title Leaf Node, этот запрос не требует дополнительного поиска, чтобы найти
Post строка в кластеризованном индексе.
Кластерный индекс
Кластерные индексы сортируют и сохраняют строки данных в таблице или представлении на основе значений их ключей. Это столбцы, включенные в определение индекса. В таблице может быть только один кластеризованный индекс, поскольку сами строки данных могут быть отсортированы только в одном порядке.
Единственный раз, когда строки данных в таблице хранятся в отсортированном порядке, это когда таблица содержит кластерный индекс. Когда таблица имеет кластеризованный индекс, она называется кластерной таблицей. Если таблица не имеет кластеризованного индекса, ее строки данных хранятся в неупорядоченной структуре, называемой кучей.
Некластеризованный
Некластеризованные индексы имеют структуру, отдельную от строк данных. Некластеризованный индекс содержит значения ключа некластеризованного индекса, и каждая запись значения ключа имеет указатель на строку данных, которая содержит значение ключа. Указатель от строки индекса в некластеризованном индексе к строке данных называется локатором строки. Структура локатора строк зависит от того, хранятся ли страницы данных в куче или в кластерной таблице. Для кучи локатор строки - это указатель на строку. Для кластеризованной таблицы указатель строки является ключом кластеризованного индекса.
Вы можете добавить неключевые столбцы на конечный уровень некластеризованного индекса, чтобы обойти существующие ограничения ключа индекса и выполнить полностью покрытые, проиндексированные запросы. Для получения дополнительной информации см. Создание индексов с включенными столбцами. Подробные сведения об ограничениях ключа индекса см. В разделе Характеристики максимальной емкости для SQL Server.
Позвольте мне предложить определение учебника по "индексу кластеризации", которое взято из 15.6.1 из Системы баз данных: Полная книга:
Мы также можем говорить о кластеризованных индексах, которые являются индексами атрибута или атрибутов, так что все кортежи с фиксированным значением для ключа поиска этого индекса появляются примерно на нескольких блоках, которые могут их содержать.
Чтобы понять определение, давайте взглянем на пример 15.10, представленный в учебнике:
Отношение
R(a,b)сортируется по атрибутуaи хранится в таком порядке, упакован в блоки, безусловно, кластеризован. Индекс наaявляется индексом кластеризации, так как для данногоa-значение а1, все кортежи с этим значением дляaявляются последовательными Таким образом, они упакованы в блоки, за исключением, возможно, первого и последнего блоков, которые содержатa-значение а1, как показано на рис.15.14. Тем не менее, индекс на b вряд ли будет кластеризованным, так как кортежи с фиксированнымb-value будет распространяться по всему файлу, если только значенияaа такжеbочень тесно связаны.
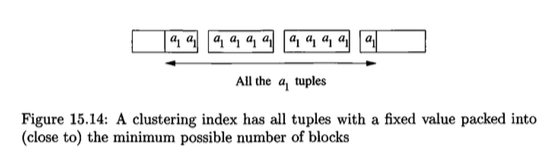
Обратите внимание, что определение не требует, чтобы блоки данных были смежными на диске; он только говорит, что кортежи с ключом поиска упакованы в как можно меньше блоков данных.
Родственное понятие - кластерное отношение. Отношение "кластеризовано", если его кортежи упакованы примерно в несколько блоков, которые могут содержать эти кортежи. Другими словами, с точки зрения дискового блока, если он содержит кортежи из разных отношений, то эти отношения не могут быть кластеризованы (т. Е. Существует более упакованный способ хранения такого отношения путем замены кортежей этого отношения из других дисковых блоков с помощью кортежи не принадлежат отношению в текущем блоке диска). Очевидно, что R(a,b) в приведенном выше примере кластер.
Чтобы связать две концепции вместе, кластеризованное отношение может иметь индекс кластеризации и индекс некластеризации. Однако для некластеризованного отношения кластеризация индекса невозможна, если индекс не построен поверх первичного ключа отношения.
"Кластер" как слово является спамом на всех уровнях абстракции на стороне хранилища базы данных (три уровня абстракции: кортежи, блоки, файл). Концепция, называемая " кластеризованный файл ", которая описывает, содержит ли файл (абстракция для группы блоков (один или несколько дисковых блоков)) кортежи из одного отношения или разных отношений. Это не относится к концепции индекса кластеризации, как на уровне файлов.
Однако некоторым учебным материалам нравится определять индекс кластеризации на основе определения кластеризованного файла. Эти два типа определений одинаковы на уровне кластеризованных отношений, независимо от того, определяют ли они кластеризованные отношения в терминах блока данных или файла. По ссылке в этом абзаце
Индекс для атрибута (ов) A в файле является индексом кластеризации, когда: Все кортежи со значением атрибута A = a хранятся последовательно (= последовательно) в файле данных
Последовательное хранение кортежей - это то же самое, что сказать, что "кортежи упакованы примерно в несколько блоков, которые могут содержать эти кортежи" (с небольшой разницей в том, что один говорит о файле, другой говорит о диске). Это потому, что последовательное хранение кортежей - это способ достичь "упакованного в примерно столько блоков, сколько может вместить эти кортежи".
Кластерныйиндекс: ограничение первичного ключа автоматически создает кластерный индекс, если в таблице еще нет кластеризованного индекса. Фактические данные кластерного индекса могут храниться на уровне листа индекса.
Некластеризованный индекс: фактические данные некластеризованного индекса непосредственно не обнаруживаются на конечном узле, вместо этого необходимо выполнить дополнительный шаг для поиска, поскольку в нем есть только значения локаторов строк, указывающие на фактические данные. Некластерный индекс не может быть отсортирован как кластерный индекс. В одной таблице может быть несколько некластеризованных индексов, на самом деле это зависит от используемой нами версии сервера SQL. В основном Sql server 2005 допускает 249 некластеризованных индексов, а для вышеприведенных версий, таких как 2008, 2016, он допускает 999 некластеризованных индексов на таблицу.
Кластерный индекс - кластерный индекс определяет порядок, в котором данные физически хранятся в таблице. Данные таблицы могут быть отсортированы только одним способом, поэтому для каждой таблицы может быть только один кластеризованный индекс. В SQL Server ограничение первичного ключа автоматически создает кластеризованный индекс для этого конкретного столбца.
Некластерный индекс- Некластеризованный индекс не сортирует физические данные внутри таблицы. Фактически, некластеризованный индекс хранится в одном месте, а данные таблицы хранятся в другом месте. Это похоже на учебник, где содержание книги находится в одном месте, а указатель - в другом. Это позволяет использовать более одного некластеризованного индекса для каждой таблицы. Здесь важно упомянуть, что внутри таблицы данные будут отсортированы по кластеризованному индексу. Однако внутри некластеризованного индекса данные хранятся в указанном порядке. Индекс содержит значения столбцов, по которым создается индекс, и адрес записи, которой принадлежит значение столбца. Когда запрос выполняется в отношении столбца, для которого создан индекс, база данных сначала переходит к индексу и ищет адрес соответствующей строки в таблице.Затем он перейдет к адресу этой строки и получит другие значения столбца. Из-за этого дополнительного шага некластеризованные индексы работают медленнее, чем кластеризованные.
Различия между кластеризованным и некластеризованным индексом
- Для каждой таблицы может быть только один кластеризованный индекс. Однако вы можете создать несколько некластеризованных индексов для одной таблицы.
- Кластерные индексы только сортируют таблицы. Следовательно, они не занимают лишнего места. Некластеризованные индексы хранятся в отдельном месте от реальной таблицы, требуя больше места для хранения.
- Кластерные индексы работают быстрее, чем некластеризованные индексы, поскольку они не требуют дополнительных шагов поиска.
Для получения дополнительной информации обратитесь к этой статье.
Если файл, содержащий записи, упорядочен последовательно, индекс кластеризации - это индекс, ключ поиска которого также определяет последовательный порядок файла. Индексы кластеризации также называют первичными индексами; может показаться, что термин первичный индекс обозначает индекс первичного ключа, но на самом деле такие индексы могут быть построены на любом поисковом ключе. Ключ поиска индекса кластеризации часто является первичным ключом, хотя это не обязательно так. Индексы, в ключе поиска которых указан порядок, отличный от последовательного порядка файла, называются некластеризованными индексами или вторичными индексами. Термины "кластеризованный" и "некластеризованный" часто используются вместо "кластеризация" и "некластеризация".