Вопрос о SPSS modeler (есть препятствие для автоматического запуска потока)
У меня есть поток SPSSmodeler, который теперь используется и постоянно обновляется каждую неделю для генерации определенного набора данных. Необработанные данные для этого потока также обновляются еженедельно.
В части этого потока есть множество узлов, которые необходимо было модифицировать и обновлять вручную каждую неделю, и последовательность этой части приведена ниже: Тип узла => Узел реструктуризации => Агрегатный узел
Чтобы упростить объяснение роли этих узлов, я нарисовал их изображение ниже.
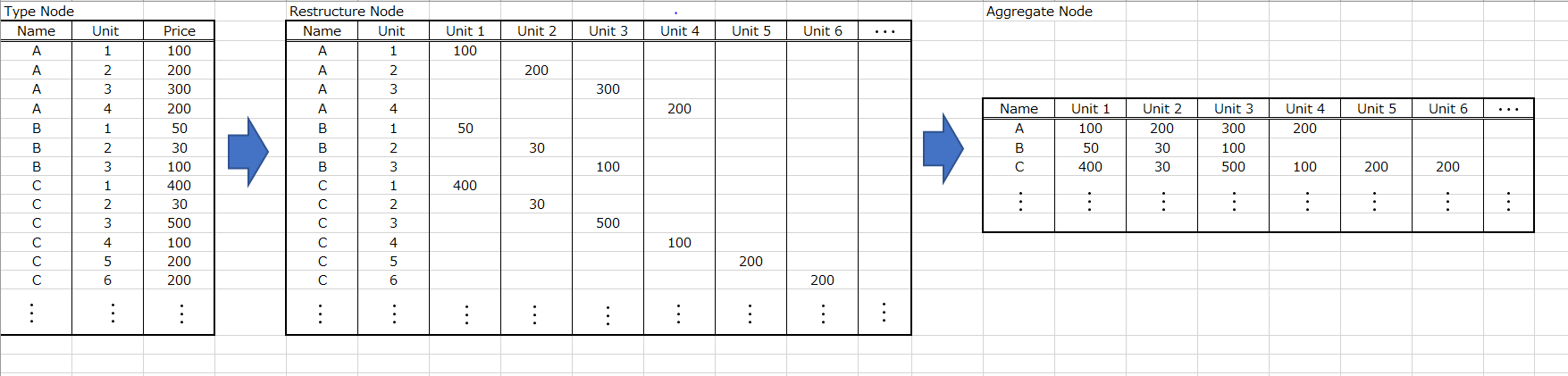
Поскольку исходные исходные данные изменяются еженедельно, диапазон значений единиц измерения, указанных выше, всегда варьируется, иногда более 6 (может быть, 100), другие меньше 6 (может быть, 3). Вот почему кто-то должен модифицировать там и обновлять эти узлы еженедельно до сих пор. * Стоимость единицы имеет определенные ограничения (на данный момент 300)
Однако теперь мы стремимся запустить этот поток автоматически, не затрагивая какие-либо человеческие операции с ним, которые нам нужно настроить, чтобы он работал идеально, автоматически. Пожалуйста, помогите и оцените ваши усилия, спасибо!
1 ответ
Для автоматизации я предлагаю попробовать использовать глобальные узлы в сочетании со скриптами clem внутри выполнения (скрипт по умолчанию). У меня есть поток, который вычисляет первую дату и последнюю дату, и эти переменные используются для переименования файлов в конце выполнения. Я думаю, что вы могли бы использовать нечто подобное, как описано здесь:
1) Создать производные узлы для вывода значений единиц измерения, используемых в еженедельном потоке
2) Сохраните эту информацию в таблице с именем 'count_variable'
3) Используйте глобальный узел с именем Global с запросом, подобным следующему: @GLOBAL_MAX (переменная, созданная в (2)) (только для записи количества переменных. Шаг 2 создал таблицу только с 1 значением, поэтому GLOBAL_MAX будет только приведи количество переменных).
4) Запрос внутри вкладки выполнения будет похож на это:
выполнить count_variable
var tabledata
вар фн
set tabledata = count_variable.output
установить count_variable = значение tabledata в 1 1
выполнить Global
5) Теперь вы можете использовать информацию о переменных, просто используя уже созданную "count_variable"
Это не легко объяснить, просто набрав, но я надеюсь, что было полезно. Пожалуйста, пометьте +1 в этом ответе, если он был релевантным.
Я думаю, что есть лучшее, более простое и более эффективное (но рискованное из-за требований узла к входным данным) решение вашей проблемы. Он называется Transpose node и делает именно это - поворачивает вашу таблицу. Но только с версии 18.1. Вот пример: https://developer.ibm.com/answers/questions/389161/how-does-new-feature-partial-transpose-work-in-sps/