Pivot в SQL: счетчик работает не так, как ожидалось
В моей базе данных Oracle Responsys есть таблица, которая содержит записи, среди которых есть две другие переменные:
статус
LOCATION_ID
Я хочу подсчитать количество записей, сгруппированных по status и location_id, и отобразить их в виде сводной таблицы.
Это, кажется, точный пример, который появляется здесь
Но когда я использую следующий запрос:
select * from
(select status,location_id from $a$ )
pivot (count(status)
for location_id in (0,1,2,3,4)
) order by status
Значения, которые появляются в сводной таблице, являются просто именами столбцов:
выход:
status 0 1 2 3 4
-1 0 1 2 3 4
1 0 1 2 3 4
2 0 1 2 3 4
3 0 1 2 3 4
4 0 1 2 3 4
5 0 1 2 3 4
Я также дал попробовать следующее:
select * from
(select status,location_id , count(*) as nbreports
from $a$ group by status,location_id )
pivot (sum(nbreports)
for location in (0,1,2,3,4)
) order by status
но это дает мне тот же результат.
select status,location_id , count(*) as nbreports
from $a$
group by status,location_id
конечно, даст мне значения, которые я хочу, но отображать их как столбец, а не как сводную таблицу
Как я могу получить в сводной таблице в каждой ячейке количество записей со статусом и расположением в строке и столбце?
Пример данных:
CUSTOMER,STATUS,LOCATION_ID
1,-1,1
2,1,1
3,2,1
4,3,0
5,4,2
6,5,3
7,3,4
Типы данных таблицы:
CUSTOMER Text Field (to 25 chars)
STATUS Text Field (to 25 chars)
LOCATION_ID Number Field
1 ответ
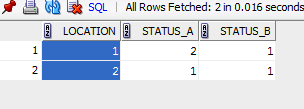
Пожалуйста, проверьте правильность моего понимания ваших требований, вы можете сделать наоборот для столбца местоположения.
create table test(
status varchar2(2),
location number
);
insert into test values('A',1);
insert into test values('A',2);
insert into test values('A',1);
insert into test values('B',1);
insert into test values('B',2);
select * from test;
select status,location,count(*)
from test
group by status,location;
select * from (
select status,location
from test
) pivot(count(*) for (status) in ('A' as STATUS_A,'B' as STATUS_B))