Ошибка кодирования JPEG для любого размера изображения больше 16x8 или 8x16
В настоящее время я разрабатываю кодировщик jpeg для университетского проекта. Изображение имеет фиксированный размер, и кодировщик использует фиксированные таблицы квантования и таблицы Хаффмана для базового процесса. Во-первых, мой код читает 32-битные значения RGBx из SDRAM, преобразует в цветовое пространство YCbCr, нормализует каждый канал до 0 и записывает обратно. Затем он начинает выполнять DCT для блоков 8x8 и записывает энтропийно закодированные данные в SDRAM. Этот процесс выполняется с использованием C, а затем код Python создает файл с соответствующими маркерами JFIF и энтропийно закодированными данными. И наконец, для просмотра изображения используется стандартный декодер jpeg ОС, для чего достаточно двойного щелчка по нему.
Мой код работает с изображениями 8x8, 8x16 и 16x8, но не с 16x16 и не с реальным размером изображения, используемого в проекте. Ниже вы можете увидеть пример 16х16.
 16x16 вход
16x16 вход
 Выход 16x16
Выход 16x16
Тем не менее, на stackru это выглядит иначе, чем по сравнению с декодером по умолчанию моей ОС. Ниже показано, как это выглядит в приложении MacOS Preview.
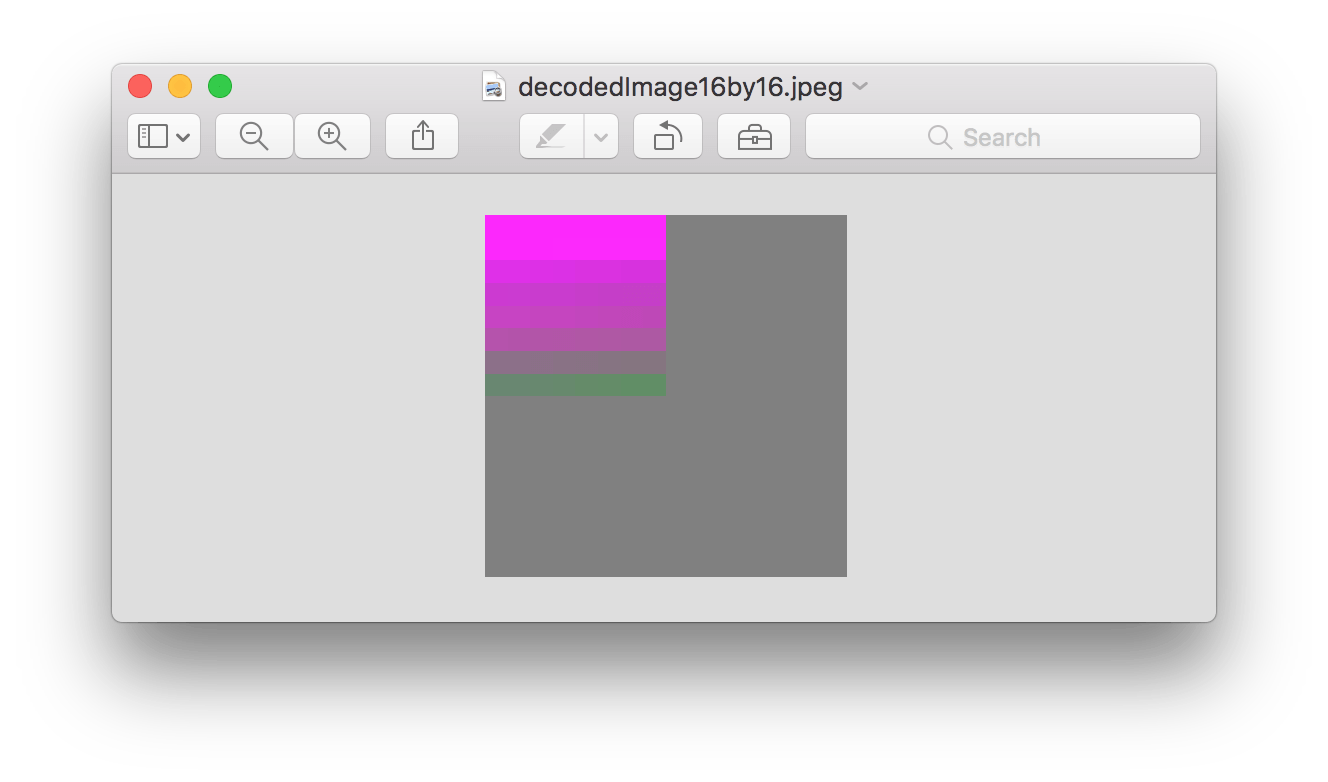
Я считаю, что моя проблема связана с маркерами в JFIF или с какой-то ошибкой алгоритма.
Я был бы очень рад, если кто-нибудь с опытом работы в jpeg может помочь мне.
С уважением
1 ответ
Я написал кодек в формате JPEG. Он поддерживается по адресу https://github.com/MalcolmMcLean/babyxrc однако вы можете посмотреть или даже использовать его, что на самом деле не отвечает на ваш вопрос.
JPEG основан на 16x16 блоках для яркости и 8x8 блоках для яркости. Поэтому неудивительно, что первоначальная версия вашего программного обеспечения падает после первого блока 16x16. Это просто обычная ошибка программирования. Если вы не можете найти его, прочитав спецификацию JEG, запустите редактор и создайте плоское изображение размером 32x32. Тогда посмотрите на двоичный файл и посмотрите, чем он отличается от вашего.
Вот мой loadscan без подвыборки
static int loadscanYuv111(JPEGHEADER *hdr, unsigned char *buff, FILE *fp)
{
short lum[64];
short Cb[64];
short Cr[64];
BITSTREAM *bs;
int i;
int ii;
int iii;
int iv;
int diffdc = 0;
int dcb = 0;
int dcr = 0;
int actableY;
int actableCb;
int actableCr;
int dctableY;
int dctableCb;
int dctableCr;
int count = 0;
int target;
int luminance;
int red;
int green;
int blue;
actableY = hdr->useac[0];
actableCb = hdr->useac[1];
actableCr = hdr->useac[2];
dctableY = hdr->usedc[0];
dctableCb = hdr->usedc[1];
dctableCr = hdr->usedc[2];
bs = bitstream(fp);
for(i=0;i<hdr->height;i+=8)
for(ii=0;ii<hdr->width;ii+=8)
{
if(hdr->dri && (count % hdr->dri) == 0 && count > 0 )
{
readmarker(bs);
diffdc = 0;
dcb = 0;
dcr = 0;
}
getblock(lum, hdr->dctable[dctableY], hdr->actable[actableY], bs);
lum[0] += diffdc;
diffdc = lum[0];
for(iv=0;iv<64;iv++)
lum[iv] *= hdr->qttable[hdr->useq[0]][iv];
unzigzag(lum);
idct8x8(lum);
getblock(Cb, hdr->dctable[dctableCb], hdr->actable[actableCb], bs);
Cb[0] += dcb;
dcb = Cb[0];
for(iv=0;iv<64;iv++)
Cb[iv] *= hdr->qttable[hdr->useq[1]][iv];
unzigzag(Cb);
idct8x8(Cb);
getblock(Cr, hdr->dctable[dctableCr], hdr->actable[actableCr], bs);
Cr[0] += dcr;
dcr = Cr[0];
for(iv=0;iv<64;iv++)
Cr[iv] *= hdr->qttable[hdr->useq[2]][iv];
unzigzag(Cr);
idct8x8(Cr);
for(iii=0;iii<8;iii++)
{
if( i + iii >= hdr->height)
break;
for(iv=0;iv<8;iv++)
{
if(ii + iv >= hdr->width)
break;
target = (i + iii) * hdr->width * 3 + (ii + iv) * 3;
luminance = lum[iii*8+iv]/64 + 128;
red = (int) (luminance + 1.402 * Cr[iii*8+iv]/64);
green = (int) (luminance - 0.34414 * Cb[iii*8+iv]/64 - 0.71414 * Cr[iii*8+iv]/64);
blue = (int) (luminance + 1.772 * Cb[iii*8+iv]/64);
red = clamp(red, 0, 255);
green = clamp(green, 0, 255);
blue = clamp(blue, 0, 255);
buff[target] = red;
buff[target+1] = green;
buff[target+2] = blue;
}
}
count++;
}
killbitstream(bs);
if(loadeoi(fp) == 0)
return 0;
return -1;
}
Как видите, данные чередуются. Однако, если вы ошиблись, это создаст своеобразное изображение правильных размеров, а не меньшее, чем ожидалось.