Является ли низкая производительность std::vector из-за того, что realloc не называется логарифмическим числом раз?
РЕДАКТИРОВАТЬ: я добавил еще два теста, чтобы сравнить использование realloc с массивом C и reserve() с std::vector. Из последнего анализа кажется, что realloc влияет очень сильно, даже если вызывается только 30 раз. Проверка документации, я думаю, это связано с тем, что realloc может вернуть полностью новый указатель, копируя старый. Для завершения сценария я также добавил код и график для полного выделения массива во время инициализации. Отличие от reserve() ощутимо
Флаги компиляции: только оптимизация, описанная в графе, компиляция с g++ и ничего более.
Оригинальный вопрос:
Я сделал эталон std::vector против массива new/delete, когда я добавляю 1 миллиард целых чисел, а второй код значительно быстрее, чем тот, который использует вектор, особенно с включенной оптимизацией.
Я подозреваю, что это вызвано тем, что вектор внутренне вызывает realloc слишком много раз. Это было бы в том случае, если вектор не увеличивается, удваивая свой размер каждый раз, когда он заполняется (здесь число 2 не имеет ничего особенного, важно то, что его размер растет геометрически). В таком случае вызовы realloc будут только O(log n) вместо O(n),
Если это и является причиной медлительности первого кода, как я могу сказать, что std:: vector будет расти геометрически?
Обратите внимание, что вызов резерва один раз будет работать в этом случае, но не в более общем случае, когда число push_back заранее неизвестно.
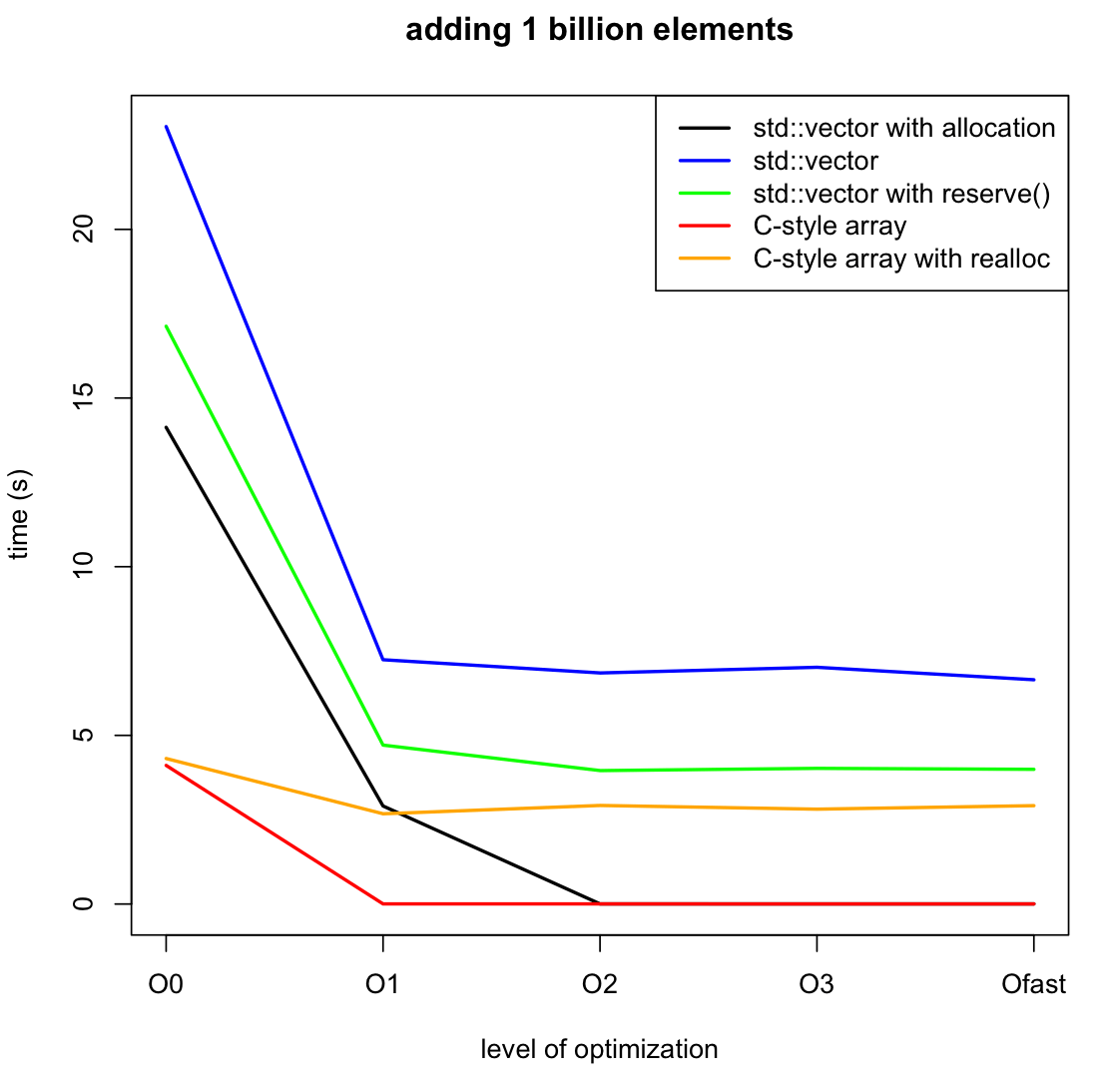
черная линия
#include<vector>
int main(int argc, char * argv[]) {
const unsigned long long size = 1000000000;
std::vector <int> b(size);
for(int i = 0; i < size; i++) {
b[i]=i;
}
return 0;
}
Синяя линия
#include<vector>
int main(int argc, char * argv[]) {
const int size = 1000000000;
std::vector <int> b;
for(int i = 0; i < size; i++) {
b.push_back(i);
}
return 0;
}
зеленая линия
#include<vector>
int main(int argc, char * argv[]) {
const int size = 1000000000;
std::vector <int> b;
b.reserve(size);
for(int i = 0; i < size; i++) {
b.push_back(i);
}
return 0;
}
Красная линия
int main(int argc, char * argv[]) {
const int size = 1000000000;
int * a = new int [size];
for(int i = 0; i < size; i++) {
a[i] = i;
}
delete [] a;
return 0;
}
оранжевая линия
#include<vector>
int main(int argc, char * argv[]) {
const unsigned long long size = 1000000000;
int * a = (int *)malloc(size*sizeof(int));
int next_power = 1;
for(int i = 0; i < size; i++) {
a[i] = i;
if(i == next_power - 1) {
next_power *= 2;
a=(int*)realloc(a,next_power*sizeof(int));
}
}
free(a);
return 0;
}
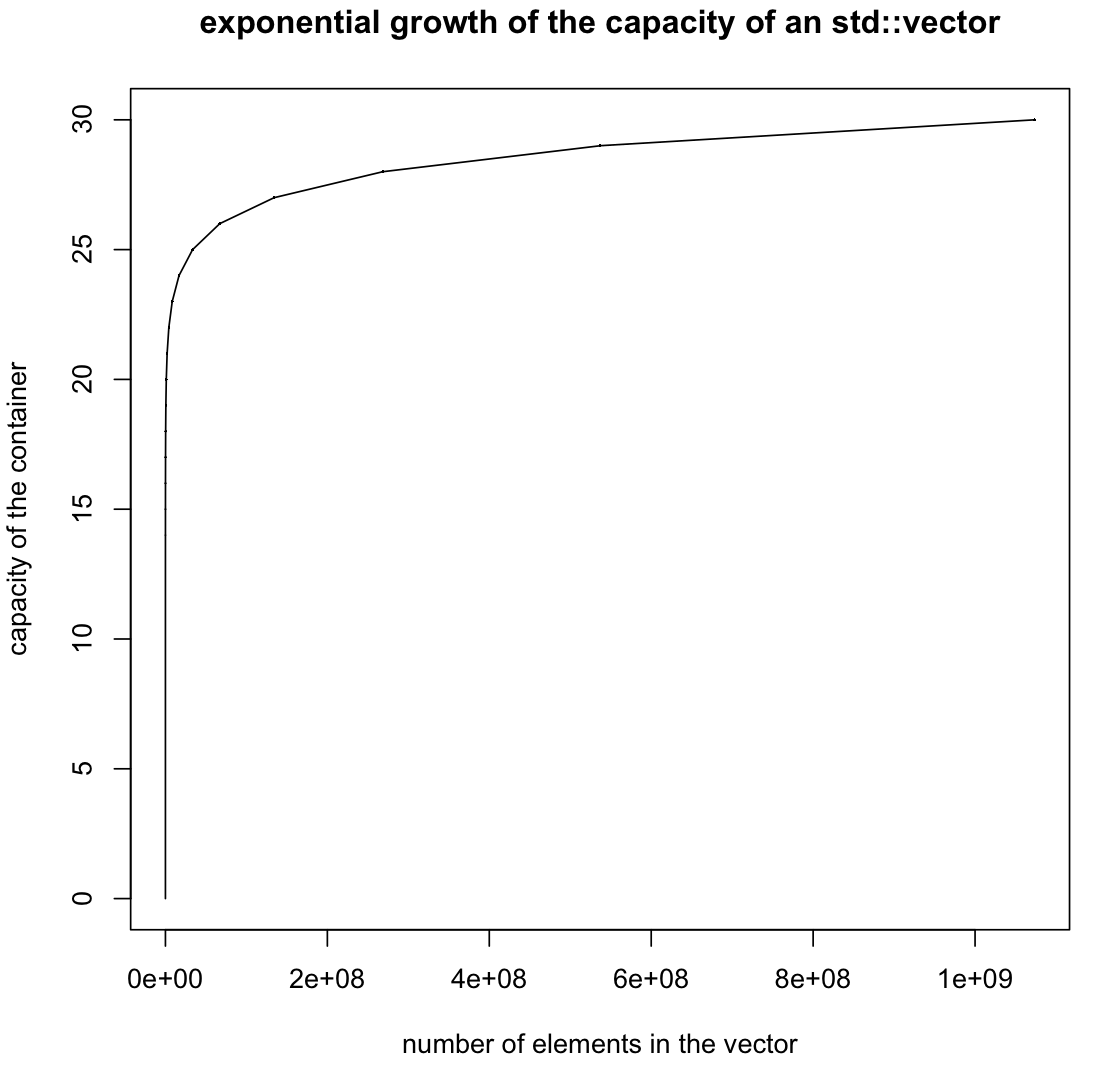
РЕДАКТИРОВАТЬ: проверка .capacity()Как и предполагалось, мы увидели, что рост действительно экспоненциальный. Так почему же вектор такой медленный?
5 ответов
Оптимизированный массив в стиле C оптимизирован до нуля.
xorl %eax, %eax
retq
это программа.
Всякий раз, когда у вас есть программа, оптимизированная почти до 0, вы должны рассмотреть эту возможность.
Оптимизатор видит, что вы ничего не делаете с выделенной памятью, отмечает, что неиспользованное выделение памяти может иметь нулевые побочные эффекты, и устраняет выделение.
И запись в память, а затем ее никогда не читать, также имеет нулевые побочные эффекты.
Для сравнения, компилятору трудно доказать, что распределение вектора бесполезно. Возможно, разработчики компилятора могли бы научить его распознавать неиспользуемые векторы std так же, как они распознают неиспользуемые необработанные массивы C, но эта оптимизация действительно является угловым случаем, и в моем опыте возникает много проблем с профилированием.
Обратите внимание, что вектор с резервом на любом уровне оптимизации в основном соответствует скорости неоптимизированной версии в стиле C.
В коде стиля C единственное, что нужно оптимизировать, это "ничего не делать". В векторном коде неоптимизированная версия полна дополнительных стековых фреймов и отладочных проверок, чтобы гарантировать, что вы не выйдете за пределы (и, если вы это сделаете, произойдет чистый сбой).
Обратите внимание, что в системе Linux распределение огромных кусков памяти не делает ничего, кроме как возиться с таблицей виртуальной памяти. Только при касании памяти он действительно найдет для вас некоторую нулевую физическую память.
Без резерва, вектор std должен угадать исходный маленький размер, изменить его размер, скопировать и повторить. Это приводит к снижению производительности на 50%, что мне кажется разумным.
С резервом, это на самом деле делает работу. Работа занимает чуть менее 5 с.
Добавление к вектору с помощью push back приводит к его геометрическому росту. Геометрическое увеличение приводит к асимптотическому среднему значению в 2-3 копии каждого создаваемого фрагмента данных.
Что касается realloc, std::vector не realloc. Он выделяет новый буфер и копирует старые данные, а затем удаляет старый.
Realloc пытается увеличить буфер, и если он не может, он побитно копирует буфер.
Это более эффективно, чем вектор STD, может управлять для побитовых копируемых типов. Держу пари, что версия realloc на самом деле никогда не копирует; всегда есть место в памяти для роста вектора (в реальной программе это может быть не так).
Отсутствие realloc в распределителях библиотек std является незначительным недостатком. Вам нужно было бы изобрести новый API для него, потому что вы хотели бы, чтобы он работал для недобитного копирования (что-то вроде "попытаться увеличить выделенную память", которая в случае неудачи оставляет вам возможность увеличить выделение).
когда я добавляю 1 миллиард целых чисел, и второй код значительно быстрее, чем тот, который использует вектор
Это... совершенно неудивительно. Один из ваших случаев связан с контейнером динамического размера, который должен быть перенастроен для его загрузки, а другой - с контейнером фиксированного размера, который этого не делает. Последний просто должен выполнять намного меньше работы, без ветвления, без дополнительных выделений. Справедливое сравнение будет:
std::vector<int> b(size);
for(int i = 0; i < size; i++) {
b[i] = i;
}
Это теперь делает то же самое, что и ваш пример массива (ну, почти - new int[size] по умолчанию инициализирует все intс тогда как std::vector<int>(size) обнуляет их, так что это еще больше работы).
Не имеет смысла сравнивать эти два слова друг с другом. Если фиксированный размер int массив соответствует вашему варианту использования, затем используйте его. Если это не так, то не надо. Вам нужен контейнер динамического размера или нет. Если вы это сделаете, то выполнение медленнее, чем решение фиксированного размера, - это то, от чего вы неявно отказываетесь.
Если это то, что вызывает медлительность первого кода, как я могу сказать,
std::vectorрасти геометрически?
std::vector уже уполномочен расти геометрически, это единственный способ сохранить O(1) амортизированный push_back сложность.
Является ли низкая производительность std::vector из-за того, что realloc не называется логарифмическим числом раз?
Ваш тест не подтверждает этот вывод и не доказывает обратное. Однако я бы предположил, что перераспределение называется линейным числом раз, если нет противоположных доказательств.
Обновление: Ваш новый тест является очевидным доказательством против вашей гипотезы о нелогарифмическом перераспределении.
Я подозреваю, что это вызвано тем, что вектор внутренне вызывает realloc слишком много раз.
Обновление: ваш новый тест показывает, что некоторая разница связана с перераспределением... но не со всеми. Я подозреваю, что остаток связан с тем фактом, что оптимизатор смог доказать (но только в случае нерастущих), что значения массива не используются, и решил не зацикливать и записывать их вообще. Если бы вы были уверены, что записанные значения действительно используются, то я ожидаю, что нерастущий массив будет иметь оптимизированную производительность, аналогичную резервирующему вектору.
Разница (между резервирующим кодом и нерезервирующим вектором) в оптимизированной сборке, скорее всего, связана с большим количеством перераспределений (по сравнению с отсутствием перераспределений зарезервированного массива). Является ли количество перераспределений слишком большим, ситуативно и субъективно. Недостатком выполнения меньшего количества перераспределений является больше потраченного впустую пространства из-за перераспределения.
Обратите внимание, что стоимость перераспределения больших массивов в основном связана с копированием элементов, а не с самим выделением памяти.
В неоптимизированной сборке, вероятно, есть дополнительные линейные издержки из-за вызовов функций, которые не были развернуты в строке.
как я могу сказать std::vector расти геометрически?
Геометрический рост требуется стандартом. Нет пути и не нужно рассказывать std::vector использовать геометрический рост.
Обратите внимание, что вызов резерва один раз будет работать в этом случае, но не в более общем случае, когда число push_back заранее неизвестно.
Тем не менее, общий случай, когда число push_back заранее неизвестно - это случай, когда нерастущий массив даже не вариант, поэтому его производительность не имеет значения для этого общего случая.
Это не сравнивает геометрический рост с арифметическим (или любым другим) ростом. Он сравнивает предварительное распределение всего пространства, необходимого для роста пространства по мере необходимости. Итак, давайте начнем с сравнения std::vector к некоторому коду, который на самом деле использует геометрический рост, и использует оба способа так, чтобы геометрический рост использовал 1. Итак, вот простой класс, который выполняет геометрический рост:
class my_vect {
int *data;
size_t current_used;
size_t current_alloc;
public:
my_vect()
: data(nullptr)
, current_used(0)
, current_alloc(0)
{}
void push_back(int val) {
if (nullptr == data) {
data = new int[1];
current_alloc = 1;
}
else if (current_used == current_alloc) {
int *temp = new int[current_alloc * 2];
for (size_t i=0; i<current_used; i++)
temp[i] = data[i];
swap(temp, data);
delete [] temp;
current_alloc *= 2;
}
data[current_used++] = val;
}
int &at(size_t index) {
if (index >= current_used)
throw bad_index();
return data[index];
}
int &operator[](size_t index) {
return data[index];
}
~my_vect() { delete [] data; }
};
... и вот код для его осуществления (и сделать то же самое с std::vector):
int main() {
std::locale out("");
std::cout.imbue(out);
using namespace std::chrono;
std::cout << "my_vect\n";
for (int size = 100; size <= 1000000000; size *= 10) {
auto start = high_resolution_clock::now();
my_vect b;
for(int i = 0; i < size; i++) {
b.push_back(i);
}
auto stop = high_resolution_clock::now();
std::cout << "Size: " << std::setw(15) << size << ", Time: " << std::setw(15) << duration_cast<microseconds>(stop-start).count() << " us\n";
}
std::cout << "\nstd::vector\n";
for (int size = 100; size <= 1000000000; size *= 10) {
auto start = high_resolution_clock::now();
std::vector<int> b;
for (int i = 0; i < size; i++) {
b.push_back(i);
}
auto stop = high_resolution_clock::now();
std::cout << "Size: " << std::setw(15) << size << ", Time: " << std::setw(15) << duration_cast<microseconds>(stop - start).count() << " us\n";
}
}
Я скомпилировал это с g++ -std=c++14 -O3 my_vect.cpp, Когда я выполняю это, я получаю такой результат:
my_vect
Size: 100, Time: 8 us
Size: 1,000, Time: 23 us
Size: 10,000, Time: 141 us
Size: 100,000, Time: 950 us
Size: 1,000,000, Time: 8,040 us
Size: 10,000,000, Time: 51,404 us
Size: 100,000,000, Time: 442,713 us
Size: 1,000,000,000, Time: 7,936,013 us
std::vector
Size: 100, Time: 40 us
Size: 1,000, Time: 4 us
Size: 10,000, Time: 29 us
Size: 100,000, Time: 426 us
Size: 1,000,000, Time: 3,730 us
Size: 10,000,000, Time: 41,294 us
Size: 100,000,000, Time: 363,942 us
Size: 1,000,000,000, Time: 5,200,545 us
Я, несомненно, мог бы оптимизировать my_vect чтобы идти в ногу с std::vector (например, изначально выделение места, скажем, для 256 элементов, вероятно, было бы довольно большой помощью). Я не пытался сделать достаточно прогонов (и статистический анализ), чтобы быть уверенным, что std::vector действительно надежнее, чем my_vect или. Тем не менее, это, кажется, указывает на то, что когда мы сравниваем яблоки с яблоками, мы получаем результаты, которые по крайней мере приблизительно сопоставимы (например, в пределах довольно небольшого, постоянного фактора друг друга).
1. В качестве дополнительного примечания, я чувствую себя обязанным отметить, что на самом деле это не совсем сравнивает яблоки с яблоками - но, по крайней мере, пока мы только воплощаем std::vector над int многие из очевидных различий в основном скрыты.
Этот пост включает
- классы обертки над
realloc,mremapобеспечить функциональность перераспределения. - Пользовательский векторный класс.
- Тест производительности.
// C++17
#include <benchmark/benchmark.h> // Googleo benchmark lib, for benchmark.
#include <new> // For std::bad_alloc.
#include <memory> // For std::allocator_traits, std::uninitialized_move.
#include <cstdlib> // For C heap management API.
#include <cstddef> // For std::size_t, std::max_align_t.
#include <cassert> // For assert.
#include <utility> // For std::forward, std::declval,
namespace linux {
#include <sys/mman.h> // For mmap, mremap, munmap.
#include <errno.h> // For errno.
auto get_errno() noexcept {
return errno;
}
}
/*
* Allocators.
* These allocators will have non-standard compliant behavior if the type T's cp ctor has side effect.
*/
// class mrealloc are usefull for allocating small space for
// std::vector.
//
// Can prevent copy of data and memory fragmentation if there's enough
// continous memory at the original place.
template <class T>
struct mrealloc {
using pointer = T*;
using value_type = T;
auto allocate(std::size_t len) {
if (auto ret = std::malloc(len))
return static_cast<pointer>(ret);
else
throw std::bad_alloc();
}
auto reallocate(pointer old_ptr, std::size_t old_len, std::size_t len) {
if (auto ret = std::realloc(old_ptr, len))
return static_cast<pointer>(ret);
else
throw std::bad_alloc();
}
void deallocate(void *ptr, std::size_t len) noexcept {
std::free(ptr);
}
};
// class mmaprealloc is suitable for large memory use.
//
// It will be usefull for situation that std::vector can grow to a huge
// size.
//
// User can call reserve without worrying wasting a lot of memory.
//
// It can prevent data copy and memory fragmentation at any time.
template <class T>
struct mmaprealloc {
using pointer = T*;
using value_type = T;
auto allocate(std::size_t len) const
{
return allocate_impl(len, MAP_PRIVATE | MAP_ANONYMOUS);
}
auto reallocate(pointer old_ptr, std::size_t old_len, std::size_t len) const
{
return reallocate_impl(old_ptr, old_len, len, MREMAP_MAYMOVE);
}
void deallocate(pointer ptr, std::size_t len) const noexcept
{
assert(linux::munmap(ptr, len) == 0);
}
protected:
auto allocate_impl(std::size_t _len, int flags) const
{
if (auto ret = linux::mmap(nullptr, get_proper_size(_len), PROT_READ | PROT_WRITE, flags, -1, 0))
return static_cast<pointer>(ret);
else
fail(EAGAIN | ENOMEM);
}
auto reallocate_impl(pointer old_ptr, std::size_t old_len, std::size_t _len, int flags) const
{
if (auto ret = linux::mremap(old_ptr, old_len, get_proper_size(_len), flags))
return static_cast<pointer>(ret);
else
fail(EAGAIN | ENOMEM);
}
static inline constexpr const std::size_t magic_num = 4096 - 1;
static inline auto get_proper_size(std::size_t len) noexcept -> std::size_t {
return round_to_pagesize(len);
}
static inline auto round_to_pagesize(std::size_t len) noexcept -> std::size_t {
return (len + magic_num) & ~magic_num;
}
static inline void fail(int assert_val)
{
auto _errno = linux::get_errno();
assert(_errno == assert_val);
throw std::bad_alloc();
}
};
template <class T>
struct mmaprealloc_populate_ver: mmaprealloc<T> {
auto allocate(size_t len) const
{
return mmaprealloc<T>::allocate_impl(len, MAP_PRIVATE | MAP_ANONYMOUS | MAP_POPULATE);
}
};
namespace impl {
struct disambiguation_t2 {};
struct disambiguation_t1 {
constexpr operator disambiguation_t2() const noexcept { return {}; }
};
template <class Alloc>
static constexpr auto has_reallocate(disambiguation_t1) noexcept -> decltype(&Alloc::reallocate, bool{}) { return true; }
template <class Alloc>
static constexpr bool has_reallocate(disambiguation_t2) noexcept { return false; }
template <class Alloc>
static inline constexpr const bool has_reallocate_v = has_reallocate<Alloc>(disambiguation_t1{});
} /* impl */
template <class Alloc>
struct allocator_traits: public std::allocator_traits<Alloc> {
using Base = std::allocator_traits<Alloc>;
using value_type = typename Base::value_type;
using pointer = typename Base::pointer;
using size_t = typename Base::size_type;
static auto reallocate(Alloc &alloc, pointer prev_ptr, size_t prev_len, size_t new_len) {
if constexpr(impl::has_reallocate_v<Alloc>)
return alloc.reallocate(prev_ptr, prev_len, new_len);
else {
auto new_ptr = Base::allocate(alloc, new_len);
// Move existing array
for(auto _prev_ptr = prev_ptr, _new_ptr = new_ptr; _prev_ptr != prev_ptr + prev_len; ++_prev_ptr, ++_new_ptr) {
new (_new_ptr) value_type(std::move(*_prev_ptr));
_new_ptr->~value_type();
}
Base::deallocate(alloc, prev_ptr, prev_len);
return new_ptr;
}
}
};
template <class T, class Alloc = std::allocator<T>>
struct vector: protected Alloc {
using alloc_traits = allocator_traits<Alloc>;
using pointer = typename alloc_traits::pointer;
using size_t = typename alloc_traits::size_type;
pointer ptr = nullptr;
size_t last = 0;
size_t avail = 0;
~vector() noexcept {
alloc_traits::deallocate(*this, ptr, avail);
}
template <class ...Args>
void emplace_back(Args &&...args) {
if (last == avail)
double_the_size();
alloc_traits::construct(*this, &ptr[last++], std::forward<Args>(args)...);
}
void double_the_size() {
if (__builtin_expect(!!(avail), true)) {
avail <<= 1;
ptr = alloc_traits::reallocate(*this, ptr, last, avail);
} else {
avail = 1 << 4;
ptr = alloc_traits::allocate(*this, avail);
}
}
};
template <class T>
static void BM_vector(benchmark::State &state) {
for(auto _: state) {
T c;
for(auto i = state.range(0); --i >= 0; )
c.emplace_back((char)i);
}
}
static constexpr const auto one_GB = 1 << 30;
BENCHMARK_TEMPLATE(BM_vector, vector<char>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mrealloc<char>>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mmaprealloc<char>>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mmaprealloc_populate_ver<char>>)->Range(1 << 3, one_GB);
BENCHMARK_MAIN();
- Тест производительности.
Все тесты производительности сделаны на:
Debian 9.4, Linux version 4.9.0-6-amd64 (debian-kernel@lists.debian.org)(gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1) ) #1 SMP Debian 4.9.82-1+deb9u3 (2018-03-02)
Скомпилировано с использованием clang++ -std=c++17 -lbenchmark -lpthread -Ofast main.cc
Команда, которую я использовал для запуска этого теста:
sudo cpupower frequency-set --governor performance
./a.out
Вот результаты теста производительности Google:
Run on (8 X 1600 MHz CPU s)
CPU Caches:
L1 Data 32K (x4)
L1 Instruction 32K (x4)
L2 Unified 256K (x4)
L3 Unified 6144K (x1)
----------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------------------------------------------------------
BM_vector<vector<char>>/8 58 ns 58 ns 11476934
BM_vector<vector<char>>/64 324 ns 324 ns 2225396
BM_vector<vector<char>>/512 1527 ns 1527 ns 453629
BM_vector<vector<char>>/4096 7196 ns 7196 ns 96695
BM_vector<vector<char>>/32768 50145 ns 50140 ns 13655
BM_vector<vector<char>>/262144 549821 ns 549825 ns 1245
BM_vector<vector<char>>/2097152 5007342 ns 5006393 ns 146
BM_vector<vector<char>>/16777216 42873349 ns 42873462 ns 15
BM_vector<vector<char>>/134217728 336225619 ns 336097218 ns 2
BM_vector<vector<char>>/1073741824 2642934606 ns 2642803281 ns 1
BM_vector<vector<char, mrealloc<char>>>/8 55 ns 55 ns 12914365
BM_vector<vector<char, mrealloc<char>>>/64 266 ns 266 ns 2591225
BM_vector<vector<char, mrealloc<char>>>/512 1229 ns 1229 ns 567505
BM_vector<vector<char, mrealloc<char>>>/4096 6903 ns 6903 ns 102752
BM_vector<vector<char, mrealloc<char>>>/32768 48522 ns 48523 ns 14409
BM_vector<vector<char, mrealloc<char>>>/262144 399470 ns 399368 ns 1783
BM_vector<vector<char, mrealloc<char>>>/2097152 3048578 ns 3048619 ns 229
BM_vector<vector<char, mrealloc<char>>>/16777216 24426934 ns 24421774 ns 29
BM_vector<vector<char, mrealloc<char>>>/134217728 262355961 ns 262357084 ns 3
BM_vector<vector<char, mrealloc<char>>>/1073741824 2092577020 ns 2092317044 ns 1
BM_vector<vector<char, mmaprealloc<char>>>/8 4285 ns 4285 ns 161498
BM_vector<vector<char, mmaprealloc<char>>>/64 5485 ns 5485 ns 125375
BM_vector<vector<char, mmaprealloc<char>>>/512 8571 ns 8569 ns 80345
BM_vector<vector<char, mmaprealloc<char>>>/4096 24248 ns 24248 ns 28655
BM_vector<vector<char, mmaprealloc<char>>>/32768 165021 ns 165011 ns 4421
BM_vector<vector<char, mmaprealloc<char>>>/262144 1177041 ns 1177048 ns 557
BM_vector<vector<char, mmaprealloc<char>>>/2097152 9229860 ns 9230023 ns 74
BM_vector<vector<char, mmaprealloc<char>>>/16777216 75425704 ns 75426431 ns 9
BM_vector<vector<char, mmaprealloc<char>>>/134217728 607661012 ns 607662273 ns 1
BM_vector<vector<char, mmaprealloc<char>>>/1073741824 4871003928 ns 4870588050 ns 1
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/8 3956 ns 3956 ns 175037
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/64 5087 ns 5086 ns 133944
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/512 8662 ns 8662 ns 80579
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/4096 23883 ns 23883 ns 29265
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/32768 158374 ns 158376 ns 4444
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/262144 1171514 ns 1171522 ns 593
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/2097152 9297357 ns 9293770 ns 74
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/16777216 75140789 ns 75141057 ns 9
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/134217728 636359403 ns 636368640 ns 1
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/1073741824 4865103542 ns 4864582150 ns 1