Идея грамматического комплекта восстановления, когда кеширует парсер на первом элементе в списке
У меня есть грамматика BNF:
{
tokens = [
COLON = ":"
space=' '
word = 'regexp:[^\r\n\s\t@\$\{\}\(\)\|\#:<>]+'
nl = 'regexp:\r|\n|(\r\n)'
]
}
root ::= nlsp book_keyword COLON [space] book_title sections
book_keyword ::= 'Journal Book' | 'Fiction Book'
book_title ::= (! section (word | string) space?)+
sections ::= section+
section ::= nlsp section_keyword COLON [space] section_title {recoverWhile='sectionRecover'}
section_keyword ::= 'Section' | 'Content'
section_title ::= (!section (word | space | COLON))+
sectionRecover ::= !(nlsp| section_keyword)
nlsp ::= (NL| space)*
Текст для проверки:
Fiction Book: Some Fiction
Section: Chapter One
Section: Chapter Two Section
Content: Chapter Three
Если я сделаю ошибку во втором или более позднем элементе, все будет хорошо, но если в первом Sectio: Chapter One все пси-дерево будет сломано.
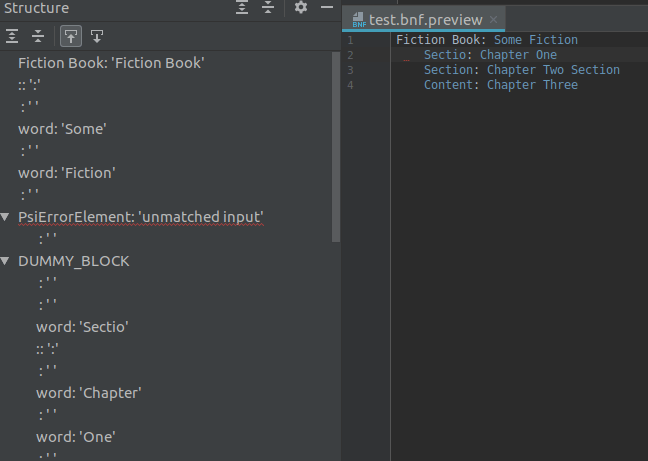
1 ответ
Я вижу несколько проблем: 1) у вас должен быть токен пробела. Что-то вроде этого:
WHITESPACE="regexp:[ \n\r\t\f]"
как следствие, вам больше не нужно пространство и npsp
2) правило restoreWhile должно быть указано без кавычек
3) раздел Восстановление соответствующих пробелов, который, скорее всего, является неправильным