Являются ли кортежи более эффективными, чем списки в Python?
Есть ли разница в производительности между кортежами и списками, когда дело доходит до создания и извлечения элементов?
8 ответов
dis Модуль разбирает байт-код для функции и полезен для просмотра различий между кортежами и списками.
В этом случае вы можете видеть, что при доступе к элементу генерируется идентичный код, но назначение кортежа происходит намного быстрее, чем назначение списка.
>>> def a():
... x=[1,2,3,4,5]
... y=x[2]
...
>>> def b():
... x=(1,2,3,4,5)
... y=x[2]
...
>>> import dis
>>> dis.dis(a)
2 0 LOAD_CONST 1 (1)
3 LOAD_CONST 2 (2)
6 LOAD_CONST 3 (3)
9 LOAD_CONST 4 (4)
12 LOAD_CONST 5 (5)
15 BUILD_LIST 5
18 STORE_FAST 0 (x)
3 21 LOAD_FAST 0 (x)
24 LOAD_CONST 2 (2)
27 BINARY_SUBSCR
28 STORE_FAST 1 (y)
31 LOAD_CONST 0 (None)
34 RETURN_VALUE
>>> dis.dis(b)
2 0 LOAD_CONST 6 ((1, 2, 3, 4, 5))
3 STORE_FAST 0 (x)
3 6 LOAD_FAST 0 (x)
9 LOAD_CONST 2 (2)
12 BINARY_SUBSCR
13 STORE_FAST 1 (y)
16 LOAD_CONST 0 (None)
19 RETURN_VALUE
Резюме
Кортежи имеют тенденцию работать лучше, чем списки почти в каждой категории:
1) Кортежи могут быть постоянно сложены.
2) Кортежи можно использовать повторно вместо копирования.
3) Кортежи компактны и не перераспределяют.
4) Кортежи напрямую ссылаются на свои элементы.
Кортежи могут быть постоянно сложены
Кортежи констант могут быть предварительно вычислены оптимизатором глазков Python или AST-оптимизатором. Списки, с другой стороны, создаются с нуля:
>>> from dis import dis
>>> dis(compile("(10, 'abc')", '', 'eval'))
1 0 LOAD_CONST 2 ((10, 'abc'))
3 RETURN_VALUE
>>> dis(compile("[10, 'abc']", '', 'eval'))
1 0 LOAD_CONST 0 (10)
3 LOAD_CONST 1 ('abc')
6 BUILD_LIST 2
9 RETURN_VALUE
Кортежи не нужно копировать
Бег tuple(some_tuple) возвращается сразу сам. Поскольку кортежи являются неизменяемыми, их не нужно копировать:
>>> a = (10, 20, 30)
>>> b = tuple(a)
>>> a is b
True
По сравнению, list(some_list) требует, чтобы все данные были скопированы в новый список:
>>> a = [10, 20, 30]
>>> b = list(a)
>>> a is b
False
Кортежи не перераспределяют
Поскольку размер кортежа фиксирован, он может храниться более компактно, чем списки, которые необходимо перераспределить, чтобы сделать операции append() эффективными.
Это дает кортежам хорошее космическое преимущество:
>>> import sys
>>> sys.getsizeof(tuple(iter(range(10))))
128
>>> sys.getsizeof(list(iter(range(10))))
200
Вот комментарий от Objects/listobject.c, который объясняет, что делают списки:
/* This over-allocates proportional to the list size, making room
* for additional growth. The over-allocation is mild, but is
* enough to give linear-time amortized behavior over a long
* sequence of appends() in the presence of a poorly-performing
* system realloc().
* The growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
* Note: new_allocated won't overflow because the largest possible value
* is PY_SSIZE_T_MAX * (9 / 8) + 6 which always fits in a size_t.
*/
Кортежи ссылаются непосредственно на свои элементы
Ссылки на объекты включаются непосредственно в объект кортежа. Напротив, списки имеют дополнительный уровень косвенности к внешнему массиву указателей.
Это дает кортежам небольшое преимущество в скорости для индексированных поисков и распаковки:
$ python3.6 -m timeit -s 'a = (10, 20, 30)' 'a[1]'
10000000 loops, best of 3: 0.0304 usec per loop
$ python3.6 -m timeit -s 'a = [10, 20, 30]' 'a[1]'
10000000 loops, best of 3: 0.0309 usec per loop
$ python3.6 -m timeit -s 'a = (10, 20, 30)' 'x, y, z = a'
10000000 loops, best of 3: 0.0249 usec per loop
$ python3.6 -m timeit -s 'a = [10, 20, 30]' 'x, y, z = a'
10000000 loops, best of 3: 0.0251 usec per loop
Вот как кортеж (10, 20) хранится:
typedef struct {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
Py_ssize_t ob_size;
PyObject *ob_item[2]; /* store a pointer to 10 and a pointer to 20 */
} PyTupleObject;
Вот как выглядит список [10, 20] хранится:
PyObject arr[2]; /* store a pointer to 10 and a pointer to 20 */
typedef struct {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
Py_ssize_t ob_size;
PyObject **ob_item = arr; /* store a pointer to the two-pointer array */
Py_ssize_t allocated;
} PyListObject;
Обратите внимание, что объект кортежа включает два указателя данных напрямую, в то время как объект списка имеет дополнительный уровень косвенности к внешнему массиву, содержащему два указателя данных.
В целом, вы можете ожидать, что кортежи будут немного быстрее. Однако вы должны обязательно протестировать ваш конкретный случай (если разница может повлиять на производительность вашей программы - помните: "преждевременная оптимизация - корень всего зла").
Python делает это очень просто: время - твой друг.
$ python -m timeit "x=(1,2,3,4,5,6,7,8)"
10000000 loops, best of 3: 0.0388 usec per loop
$ python -m timeit "x=[1,2,3,4,5,6,7,8]"
1000000 loops, best of 3: 0.363 usec per loop
а также...
$ python -m timeit -s "x=(1,2,3,4,5,6,7,8)" "y=x[3]"
10000000 loops, best of 3: 0.0938 usec per loop
$ python -m timeit -s "x=[1,2,3,4,5,6,7,8]" "y=x[3]"
10000000 loops, best of 3: 0.0649 usec per loop
Таким образом, в этом случае создание экземпляра почти на порядок быстрее для кортежа, но доступ к элементу на самом деле несколько быстрее для списка! Так что, если вы создаете несколько кортежей и обращаетесь к ним много-много раз, на самом деле может быть быстрее использовать списки.
Конечно, если вы хотите изменить элемент, список определенно будет быстрее, так как вам нужно будет создать целый новый кортеж, чтобы изменить один его элемент (так как кортежи неизменны).
Кортежи, будучи неизменяемыми, более эффективны для памяти; списки, для эффективности, перераспределить память, чтобы разрешить добавления без постоянного reallocs. Итак, если вы хотите перебрать постоянную последовательность значений в вашем коде (например, for direction in 'up', 'right', 'down', 'left':), кортежи являются предпочтительными, поскольку такие кортежи предварительно рассчитываются во время компиляции.
Скорости доступа должны быть одинаковыми (они оба хранятся в памяти в виде смежных массивов).
Но, alist.append(item) гораздо предпочтительнее atuple+= (item,) когда вы имеете дело с изменчивыми данными. Помните, что кортежи должны рассматриваться как записи без имен полей.
Вот еще один маленький ориентир, просто ради этого..
In [11]: %timeit list(range(100))
749 ns ± 2.41 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [12]: %timeit tuple(range(100))
781 ns ± 3.34 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
In [1]: %timeit list(range(1_000))
13.5 µs ± 466 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
In [2]: %timeit tuple(range(1_000))
12.4 µs ± 182 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
In [7]: %timeit list(range(10_000))
182 µs ± 810 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [8]: %timeit tuple(range(10_000))
188 µs ± 2.38 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
In [3]: %timeit list(range(1_00_000))
2.76 ms ± 30.5 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [4]: %timeit tuple(range(1_00_000))
2.74 ms ± 31.8 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
In [10]: %timeit list(range(10_00_000))
28.1 ms ± 266 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [9]: %timeit tuple(range(10_00_000))
28.5 ms ± 447 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Давайте усредним это:
In [3]: l = np.array([749 * 10 ** -9, 13.5 * 10 ** -6, 182 * 10 ** -6, 2.76 * 10 ** -3, 28.1 * 10 ** -3])
In [2]: t = np.array([781 * 10 ** -9, 12.4 * 10 ** -6, 188 * 10 ** -6, 2.74 * 10 ** -3, 28.5 * 10 ** -3])
In [11]: np.average(l)
Out[11]: 0.0062112498000000006
In [12]: np.average(t)
Out[12]: 0.0062882362
In [17]: np.average(t) / np.average(l) * 100
Out[17]: 101.23946713590554
Вы можете назвать это почти безрезультатным.
Но конечно, кортежи взяли 101.239% время или 1.239% дополнительное время для выполнения работы по сравнению со списками.
Вы должны также рассмотреть array модуль в стандартной библиотеке, если все элементы в вашем списке или кортеже относятся к одному и тому же типу C. Это займет меньше памяти и может быть быстрее.
Кортежи работают лучше, но если все элементы неизменяемы. Если какой-либо элемент кортежа является неизменяемым, для его компиляции потребуется больше времени. Я скомпилировал 3 разных объекта:
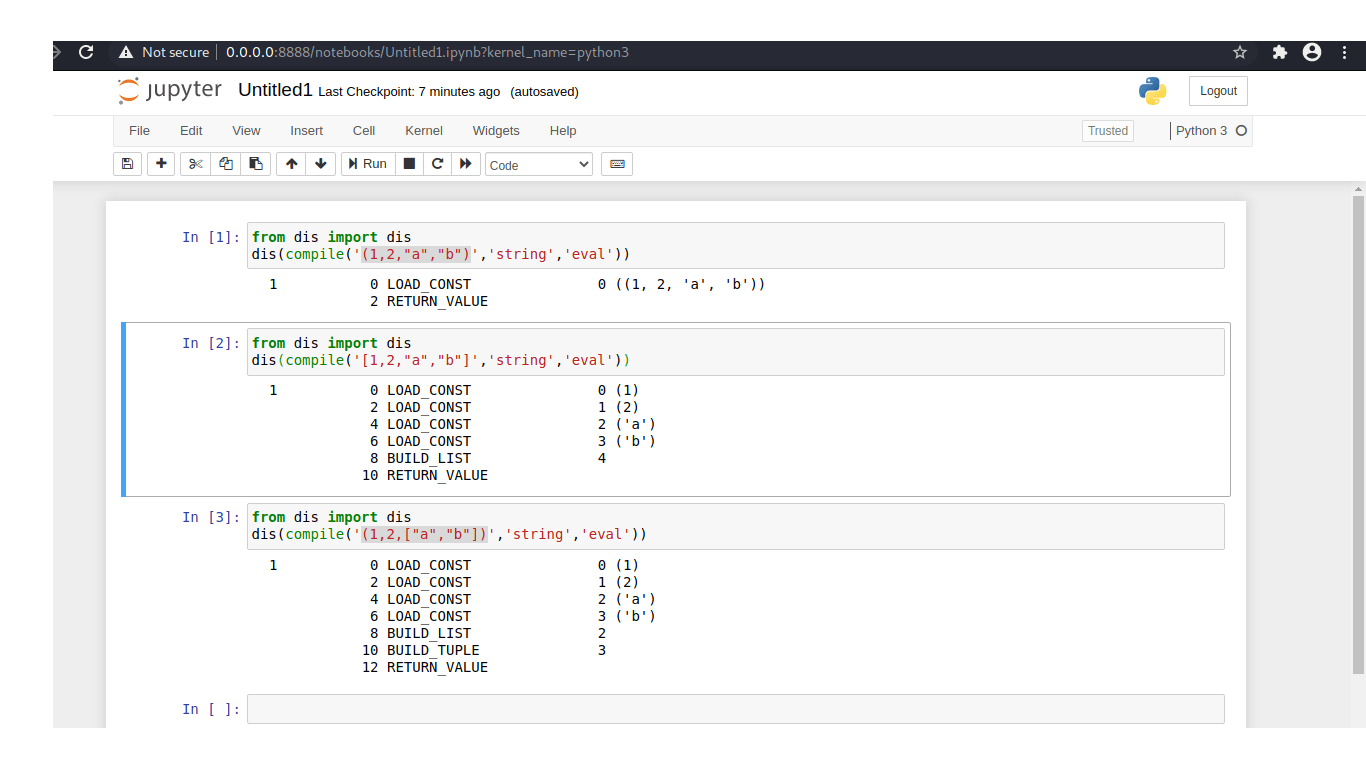
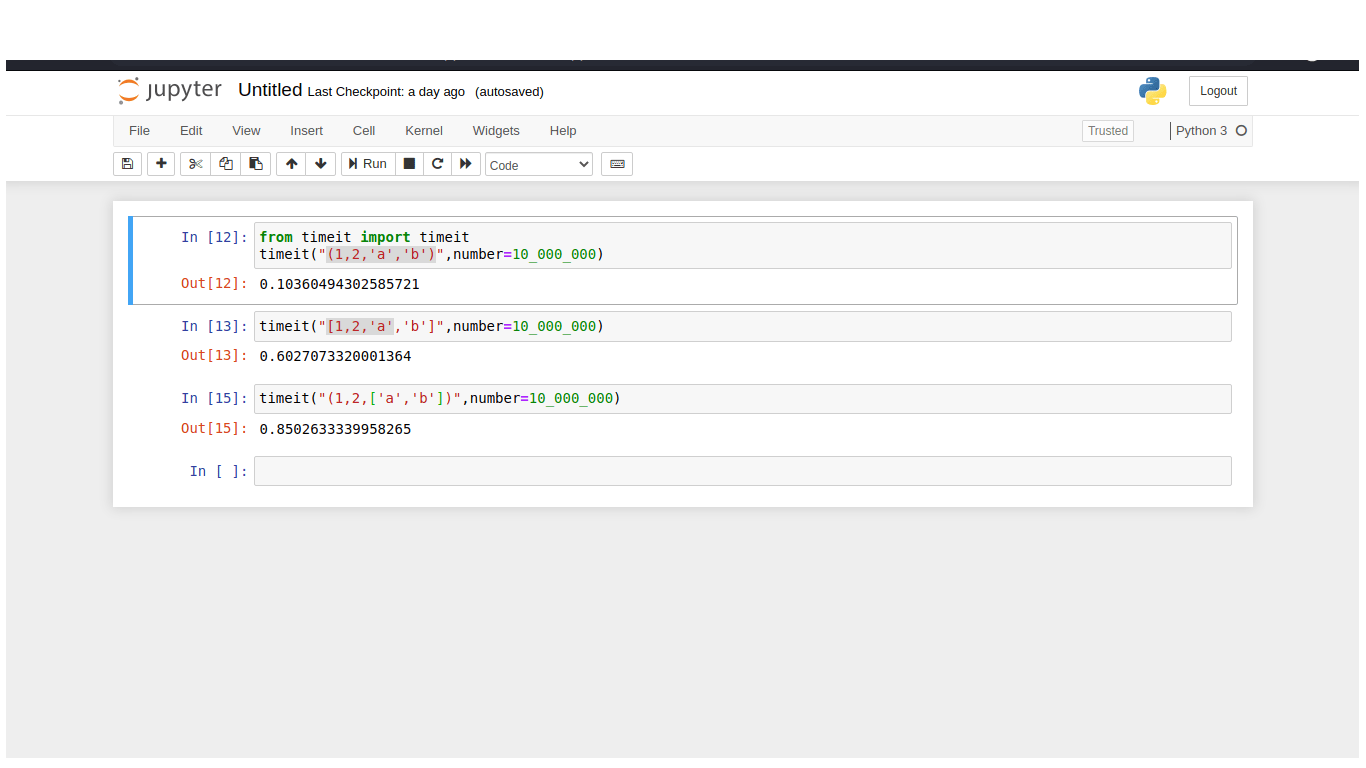
In the first example i compiled a tuple. it loaded at the tuple as constant, it loaded and returned value. it took one step to compile. this is called constant folding. when i compiled a list with the same elements, it has to load each individual constant first, then it builds the list and returns it. in the third example i used a tuple that includes a list. I timed each operation.
-- MEMORY ALLOCATION
When mutable container objects such as lists, sets, dictionaries, etc are created, and during their lifetime, the allocated capacity of these containers (the number of items they can contain) is greater than the number of elements in the container. This is done to make adding elements to the collection more efficient, and is called over-allocating. Thus size of the list doesn't grow every time we append an element - it only does so occasionally. Resizing a list is very expensive, so not resizing every time an item is added helps out but you don't want to overallocate too much as this has a memory cost.
Immutable containers on the other hand, since their item count is fixed once they have been created, do not need this overallocation - so their storage efficiency is greater. As tuples get larger, their size increases.
-- COPY
it does not make sense to make a shallow copy of immutable sequence because you cannot mutate it anyways. So copying tuple just returns itself, with the memory address. That is why copying tuple is faster
Кортежи должны быть немного более эффективными и поэтому быстрее, чем списки, потому что они неизменяемы.
Основная причина, почему Tuple очень эффективен в чтении, потому что он неизменен.
почему неизменяемые объекты легко читать?
Причина в том, что кортежи могут храниться в кеш-памяти, в отличие от списков. Программа всегда считывает из памяти ячейки списков, так как она изменчива (может измениться в любое время)