Возможно ли событие RESOURCE_STALLS.RS произойти, даже если RS не полностью заполнен?
Описание RESOURCE_STALLS.RS Событие производительности оборудования для Intel Broadwell следующее:
Это событие подсчитывает циклы останова, вызванные отсутствием подходящих записей на станции резервирования (RS). Это может произойти из-за переполнения RS или из-за освобождения RS из-за схемы распределения портов записи массива RS (каждая запись RS имеет два порта записи вместо четырех. В результате пустые записи не могут использоваться, хотя RS на самом деле не заполнен), Это подсчитывает циклы, когда бэкэнд-конвейер заблокировал доставку из внешнего интерфейса.
Это в основном говорит о том, что есть две ситуации, когда происходит событие остановки RS:
- Когда все подходящие записи RS заняты, а распределитель не остановлен.
- Когда происходит "освобождение RS", потому что есть только два порта записи, и распределитель не останавливается.
Что означает "приемлемый" в первой ситуации? Означает ли это, что не все записи могут быть заняты всеми видами мопов? Потому что я понимаю, что в современных микроархитектурах любая запись может быть использована любым видом мопов. Кроме того, что такое схема распределения портов записи массива RS и как она вызывает остановку RS, даже если не все записи заняты? Означает ли это, что в Haswell было четыре порта записи, а сейчас в Broadwell только два? Применима ли какая-либо из этих двух ситуаций к Skylake или Haswell, даже если в руководстве не указано иное?
1 ответ
Да, это возможно RESOURCE_STALLS для индикации полного RS до того, как RS будет полностью заполнен.
По мере заполнения RS распределение новых мопов в RS становится менее идеальным до тех пор, пока в какой-то момент оно не может полностью остановиться, даже если некоторые записи остаются.
Кроме того, не все записи RS доступны для всех инструкций. Например, в Haswell я заметил, что только 30-32 из 60 записей RS доступны для загрузки: эти записи могут быть особенными, например, в том, что они поддерживают воспроизведение uop. На Skylake ситуация иная: вся RS недоступна для любого типа инструкций: скорее, RS "97 записей" фактически состоит из RS с 64 входами для операций ALU и RS с 33 входами для операций загрузки.. Таким образом, все 97 записей RS редко будут заполнены, если только по некоторому совпадению они не будут заполнены в один и тот же момент.
В RESOURCE_STALLS.RS событие (umask 0x4) срабатывает только тогда, когда "ALU" часть RS заполнена (или настолько заполнена, что операция не может выделить). Для нагрузки RS(которая перекрывается с ALU RS в Haswell, но не в Skylake) соответствующее событие имеет umask0x40. Вы можете использовать его сperf как 'cpu/event=0xa2,umask=0x40,name=resource_stalls_memrs_full/. Хотя события не задокументированы для Skylake, похоже, они работают нормально (хотя события с масками0x10 через 0x80 сильно отличаются от задокументированных на Sandy Bridge.
У будущих чипов Intel, вероятно, будут еще более точные станции резервирования.
Я написал программу, которая может быть использована для изучения недокументированных ограничений RS в процессорах Intel в надежде, что в конечном итоге я смогу ответить на этот вопрос. Основная идея состоит в том, чтобы удостовериться, что RS полностью пуст, прежде чем выделять и выполнять определенную последовательность мопов в цикле. RESOURCE_STALLS.RS может использоваться для определения того, попала ли эта последовательность в ограничение самой RS. Например, если RESOURCE_STALLS.RS равен 1 на каждую итерацию, тогда распределителю пришлось остановиться на один цикл, чтобы выделить записи RS для всех мопов в последовательности. Если RESOURCE_STALLS.RS намного меньше, чем 1 на одну итерацию, тогда он в принципе не должен был останавливаться, и поэтому мы знаем, что не затронули ни одно из ограничений RS.
Я экспериментировал с последовательностью зависимых ADD инструкции, последовательность зависимых инструкций BSWAP, последовательность зависимых инструкций загрузки в одно и то же местоположение, последовательность обратных или прямых инструкций безусловного перехода и последовательность инструкций сохранения в одно и то же местоположение. Следующие два графика показывают результаты для последовательности add инструкции по различным целевым занятиям RS (максимальное количество записей RS, которые будут одновременно требоваться и заняты последовательностью мопов). Все значения отображаются за одну итерацию.
Следующий график показывает, что RESOURCE_STALLS.RS на итерацию становится как минимум (или где-то рядом) 1 цикл на итерацию, когда занятость RS составляет 50. Хотя это не ясно видно, RESOURCE_STALLS.RS становится больше нуля, когда занятость RS превышает 43, но только превышает 1, когда занятость RS превышает 49. Другими словами, я могу одновременно использовать до 49 записей RS из 60 (в Haswell) без остановок RS, После этого, RESOURCE_STALLS.RS увеличивается в среднем на 1 на дополнительный моп в последовательности, что согласуется с импульсным поведением распределителя и тем фактом, что каждый ADD моп может быть завершен каждый цикл (каждый моп занимает запись RS только для 1 цикла). cycles увеличивается в среднем на 2,3 за дополнительную моп. Это больше, чем 1 на дополнительный моп, потому что в ROB есть также дополнительные киоски по причинам, не связанным с add упс, но это нормально, потому что они не влияют RESOURCE_STALLS.RS,
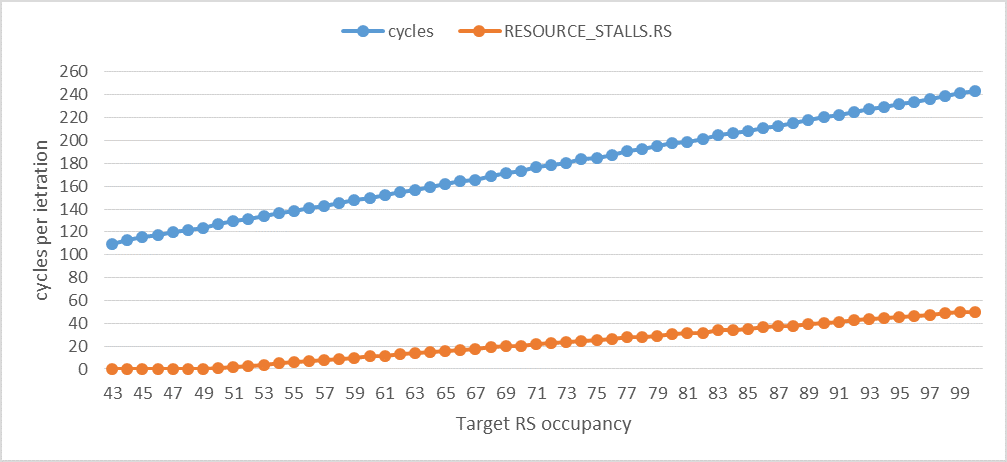
На следующем графике показано изменение cycles а также RESOURCE_STALLS.RS за итерацию. Это иллюстрирует сильную корреляцию между временем выполнения и остановками RS.
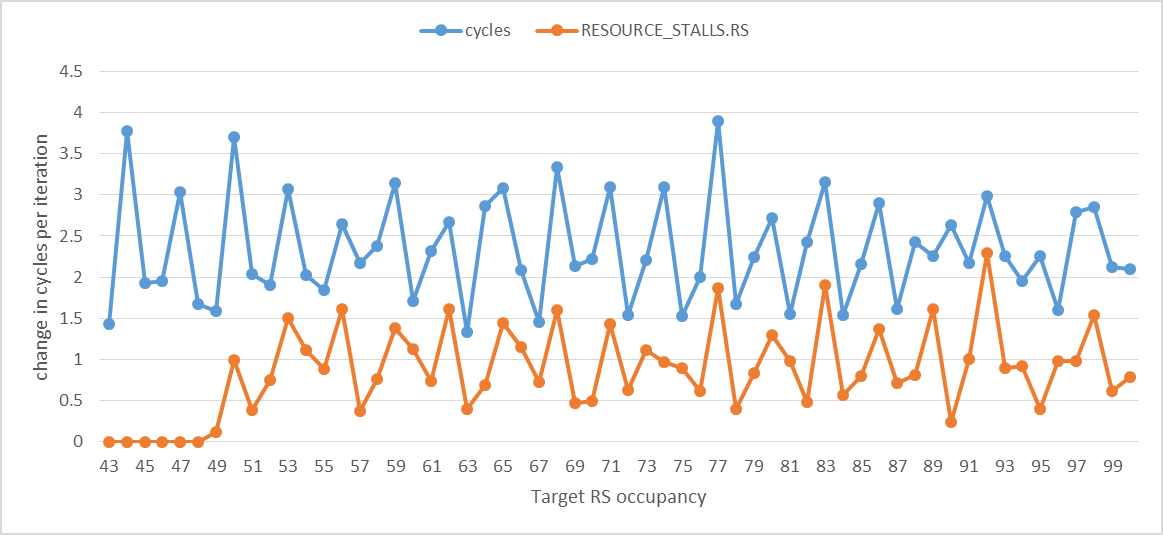
Когда целевая занятость RS находится между 44-49, RESOURCE_STALLS.RS очень маленький, но все же не совсем ноль. Я также заметил, что точный порядок, в котором различные мопы представляются распределителю, немного влияет на занятость RS, которая может быть достигнута. Я думаю, что это эффект схемы распределения портов записи массива RS, упомянутой в руководстве Intel.
Так что же с остальными 11 записями RS (предполагается, что RS Haswell имеет 60 записей)? RESOURCE_STALLS.ANY Событие производительности является ключом к ответу на вопрос. Я обновил код, который я использую для выполнения этих экспериментов, чтобы проверить различные виды нагрузок:
- Нагрузки, которые могут быть отправлены по спекулятивным адресам для достижения 4-тактовой задержки L1D. Этот случай упоминается как
loadspec, - Грузы, которые нельзя отправить с умозрительными адресами. У них L1D задержка попадания в 5 циклов на Haswell. Этот случай упоминается как
loadnonspec, - Грузы, которые можно отправить с умозрительными, но неправильными адресами. У них L1D задержка попадания в 9 циклов на Haswell. Этот случай упоминается как
loadspecreplay,
Я придерживался того же подхода с ADD инструкции, но на этот раз нам нужно посмотреть RESOURCE_STALLS.ANY вместо RESOURCE_STALLS.RS (который фактически не захватывает киоски RS из-за нагрузок). На следующем графике показано изменение cycles а также RESOURCE_STALLS.ANY за итерацию. Первый всплеск указывает, что целевая занятость RS превысила доступные записи RS для этого вида мопов. Мы можем ясно видеть, что для loadspec В этом случае ровно 11 записей RS для load uops! Когда целевая занятость RS превышает 11, требуется в среднем 3,75 цикла для входа RS, чтобы стать свободным до следующей загрузки. Это означает, что мопы освобождаются от RS, когда они завершаются, а не когда они отправляются. Это также объясняет, как работает воспроизведение UOP. Спайк для loadspecreplay происходит при занятости RS 6. Шип для loadnonspec происходит при занятости RS 9. Как вы увидите позже, эти 11 записей не предназначены для загрузки. Некоторые из 11 записей, используемых нагрузками, могут быть среди 39 записей, используемых ADD микрооперации.
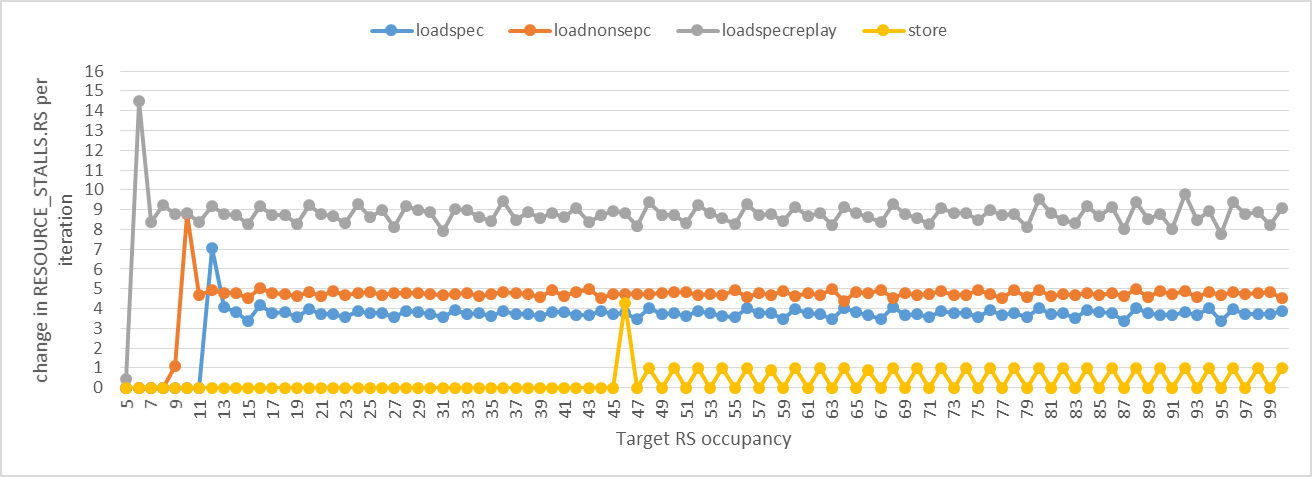
Я также разработал два тестовых примера для магазинов: один достигает предела буфера хранилища, а другой - ограничения RS. На графике выше показан первый случай. Обратите внимание, что хранилищу нужны две записи в RS, поэтому случаи, когда целевое занятие RS нечетно, совпадают с предыдущими четными занятиями RS (изменение равно нулю). График показывает, что в RS может быть до 44/2 = 22 хранилища одновременно. (В коде, который я использовал для построения графика хранилища, была ошибка, из-за которой достигнутая занятость RS была бы больше, чем она есть. После исправления, результаты показывают, что в RS может быть до 20 хранилищ одновременно.) запись, занимаемая адресом магазина или хранением данных, может быть освобождена за один цикл. Intel говорит, что в буфере хранилища Haswell есть 42 записи, но я не смог использовать все эти записи одновременно. Вероятно, мне придется разработать другой эксперимент, чтобы достичь этого.
Последовательности прыжков не вызывали никаких срывов. Я думаю, что это можно объяснить следующим образом: прыжковая операция освобождает запись RS, которую она занимает за один цикл, и распределитель не ведет себя непрерывно, когда он выделяет прыжковые операции. То есть каждый цикл, в котором одна запись RS становится свободной, и распределитель будет просто выделять один прыжок без остановки. Таким образом, мы никогда не останавливаемся, сколько бы прыжков ни было. Это в отличие от добавления мопов, где поведение пакетного распределителя заставляет его останавливаться до тех пор, пока необходимое количество записей RS не станет свободным (4 записи), даже если задержка добавления мопа также равна одному циклу. Имеет смысл, чтобы переходы распределялись как можно скорее, чтобы любые неправильные прогнозы могли быть обнаружены как можно раньше. Таким образом, если распределитель увидел скачок и в RS достаточно места для него, но не позднее, в его группе 4 мопа, он все равно выделил бы его. В противном случае, возможно, придется ждать потенциально много циклов, которые могут значительно задержать обнаружение неправильных прогнозов. Это может быть очень дорого
Есть ли инструкция, мопс которой может одновременно занимать все 60 записей RS? Да, один пример BSWAP, Для его двух мопов требуется две записи RS, и я могу ясно видеть, используя RESOURCE_STALLS.RS что его мопы могут использовать все 60 записей RS одновременно (при условии, что мои расчеты верны относительно того, как увеличивается занятость RS с использованием инструкции). Это доказывает, что в РС действительно 60 записей. Но есть ограничения относительно того, как они используются, о которых мы до сих пор мало знаем.