Дедупе в питоне
Просматривая примеры библиотеки Dedupe в Python, которая используется для дедупликации записей, я обнаружил, что в выходном файле создается столбец Cluster Id, который в соответствии с документацией указывает, какие записи ссылаются друг на друга. Хотя я не могу выяснить какую-либо связь между идентификатором кластера и тем, как это помогает найти дубликаты записей. Если у кого-то есть понимание этого, пожалуйста, объясните мне это. Это код для дедупликации.
# This can run either as a python2 or python3 code
from future.builtins import next
import os
import csv
import re
import logging
import optparse
import dedupe
from unidecode import unidecode
input_file = 'data/csv_example_input_with_true_ids.csv'
output_file = 'data/csv_example_output1.csv'
settings_file = 'data/csv_example_learned_settings'
training_file = 'data/csv_example_training.json'
# Clean or process the data
def preProcess(column):
try:
column = column.decode('utf-8')
except AttributeError:
pass
column = unidecode(column)
column = re.sub(' +', ' ', column)
column = re.sub('\n', ' ', column)
column = column.strip().strip('"').strip("'").lower().strip()
if not column:
column = None
return column
# Read in the data from CSV file:
def readData(filename):
data_d = {}
with open(filename) as f:
reader = csv.DictReader(f)
for row in reader:
clean_row = [(k, preProcess(v)) for (k, v) in row.items()]
row_id = int(row['Id'])
data_d[row_id] = dict(clean_row)
return data_d
print('importing data ...')
data_d = readData(input_file)
if os.path.exists(settings_file):
print('reading from', settings_file)
with open(settings_file, 'rb') as f:
deduper = dedupe.StaticDedupe(f)
else:
fields = [
{'field' : 'Site name', 'type': 'String'},
{'field' : 'Address', 'type': 'String'},
{'field' : 'Zip', 'type': 'Exact', 'has missing' : True},
{'field' : 'Phone', 'type': 'String', 'has missing' : True},
]
deduper = dedupe.Dedupe(fields)
deduper.sample(data_d, 15000)
if os.path.exists(training_file):
print('reading labeled examples from ', training_file)
with open(training_file, 'rb') as f:
deduper.readTraining(f)
print('starting active labeling...')
dedupe.consoleLabel(deduper)
deduper.train()
with open(training_file, 'w') as tf:
deduper.writeTraining(tf)
with open(settings_file, 'wb') as sf:
deduper.writeSettings(sf)
threshold = deduper.threshold(data_d, recall_weight=1)
print('clustering...')
clustered_dupes = deduper.match(data_d, threshold)
print('# duplicate sets', len(clustered_dupes))
cluster_membership = {}
cluster_id = 0
for (cluster_id, cluster) in enumerate(clustered_dupes):
id_set, scores = cluster
cluster_d = [data_d[c] for c in id_set]
canonical_rep = dedupe.canonicalize(cluster_d)
for record_id, score in zip(id_set, scores):
cluster_membership[record_id] = {
"cluster id" : cluster_id,
"canonical representation" : canonical_rep,
"confidence": score
}
singleton_id = cluster_id + 1
with open(output_file, 'w') as f_output, open(input_file) as f_input:
writer = csv.writer(f_output)
reader = csv.reader(f_input)
heading_row = next(reader)
heading_row.insert(0, 'confidence_score')
heading_row.insert(0, 'Cluster ID')
canonical_keys = canonical_rep.keys()
for key in canonical_keys:
heading_row.append('canonical_' + key)
writer.writerow(heading_row)
for row in reader:
row_id = int(row[0])
if row_id in cluster_membership:
cluster_id = cluster_membership[row_id]["cluster id"]
canonical_rep = cluster_membership[row_id]["canonical representation"]
row.insert(0, cluster_membership[row_id]['confidence'])
row.insert(0, cluster_id)
for key in canonical_keys:
row.append(canonical_rep[key].encode('utf8'))
else:
row.insert(0, None)
row.insert(0, singleton_id)
singleton_id += 1
for key in canonical_keys:
row.append(None)
writer.writerow(row)
заранее спасибо
1 ответ
Вы правы, Cluster ID не используется ни для чего.
Вы должны посмотреть на Cluster ID в качестве результата дедупликации. Dedupe не заинтересован в слиянии ваших записей. Его основной задачей является попытка определить записи, которые, вероятно, похожи.
Это делается путем назначения строк, которые, по его мнению, похожи с Cluster ID,
Ваша задача как инженера-программиста заключается в том, чтобы затем использовать эти данные разумным образом и решить, как вы хотите объединить эти данные (если вообще).
Если мой вклад следующий:

мой вывод будет примерно таким:
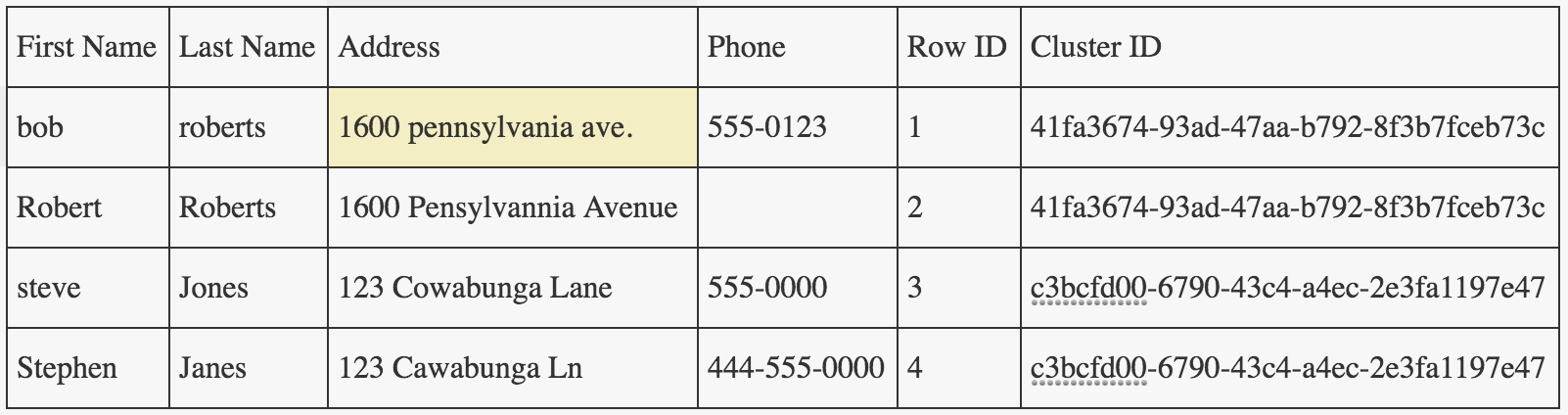
Итак, помните, что введенное вами количество записей должно всегда совпадать с выходным числом записей. Разница лишь в том, что у вас есть новый столбец "Идентификатор кластера", который теперь можно использовать для "группировки" вероятных дубликатов.